














Hugging Face 的 Transformers 是一个功能强大的机器学习框架,提供了一系列 API 和工具,用于预训练模型的下载和训练。为了避免重复下载,提高训练效率,Transformers 会自动下载和缓存模型的权重、词表等资源,默认存储在 ~/.cache/huggingface/hub 目录下。这个缓存数据的机制。
但是,当有多用户或多节点处理相同或关联任务时,每个设备都需要重复下载相同的模型和数据集,这势必造成管理难度增大和浪费网络资源的问题。
要解决这个问题,可以将 Hugging Face 的缓存数据目录设置在共享存储上,让每个需要该资源的用户能够共享使用同一份数据。
在共享存储的选择上,如果设备不多且都在本地,则可以考虑使用 Samba 或 NFS 共享。如果计算资源分布在不同的云或不同地区的机房,则需要采用性能和一致性都更有保证的分布式文件系统,JuiceFS 就是一个非常适合的方案。
利用 JuiceFS 分布式、多端共享、强一致性等特性,不同计算节点间可以高效共享和迁移训练资源,免于重复准备相同数据,从而显著优化资源使用和存储管理,提高整个 AI 模型的训练效率。
JuiceFS 架构
JuiceFS 是开源的云原生分布式文件系统,采用了数据与元数据分离存储的技术架构,以对象存储作为底层存储来保存数据,以键值存储或关系型数据库作为元数据引擎来保存文件的元数据。这些计算资源可以自行搭建,也可以在云平台上购买,因此 JuiceFS 是很容易搭建和使用的。
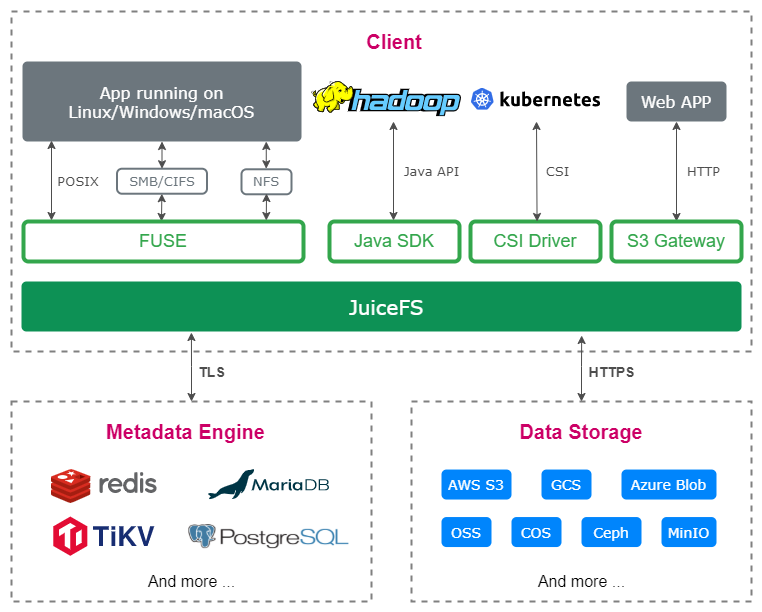
底层数据存储
在底层存储方面,JuiceFS 支持市面上几乎所有主流的公有云对象存储服务,比如 Amazon S3、Google Cloud Storage、阿里云 OSS等,也支持 MinIO、Ceph 等私有部署的对象存储。
元数据引擎
在元数据引擎方面,JuiceFS 支持 Redis、MySQL、PostgreSQL 等多种数据库,另外,也可选购 JuiceFS 官方的云服务版本,它采用 Juicedata 官方自研的高性能分布式元数据引擎,可以满足更高性能要求的场景需求。
JuiceFS 客户端
JuiceFS 分为开源版和云服务版,它们所使用的客户端不同,但使用方法基本一致。本文以开源版为例进行介绍。
JuiceFS 社区版提供了跨平台的客户端,支持 Linux、macOS、Windows 等操作系统,可以在各种环境中使用。
当你基于这些计算资源搭建了一个 JuiceFS 文件系统以后,就可以通过 JuiceFS 客户端提供的 API 或者 FUSE 接口来访问 JuiceFS 文件系统,实现文件的读写、元数据的查询等操作。
对于 Hugging Face 的缓存数据存储,可以将 JuiceFS 挂载到 ~/.cache/huggingface/ 目录下,这样 Hugging Face 相关的数据就可以存储到 JuiceFS 中。另外,也可以通过设置环境变量自定义 Hugging Face 缓存目录位置,指向 JuiceFS 挂载的目录。
接下来就展开介绍如何创建 JuiceFS 文件系统,以及将 JuiceFS 用于 Hugging Face 的缓存目录的两种方法。
创建 JuiceFS 文件系统
假设已经准备好了以下对象存储和元数据引擎:
- 对象存储 Bucket:
https://jfs.xxx.com - 对象存储 Access Key:
your-access - 对象存储 Secret Key:
your-secret - Redis 数据库:
your-redis.xxx.com:6379 - Redis 密码:
redis-password
其中,对象存储相关信息只在创建 JuiceFS 文件系统时使用一次,它们会被写入元数据引擎,在之后的使用中只需要元数据引擎的地址和密码。
安装 JuiceFS 客户端
对于 Linux 和 macOS 系统,可以通过以下命令安装 JuiceFS 客户端:
curl -sSL https://d.juicefs.com/install | sh -
Windows 系统建议在 WSL 2 的 Linux 环境中使用 JuiceFS 客户端,另外也可以自行下载预编译的 JuiceFS 客户端,详情请参考 JuiceFS 官方文档。
创建 JuiceFS 文件系统
使用 format 命令创建 JuiceFS 文件系统:
juicefs format \
--storage s3 \
--bucket https://jfs.xxx.com \
--access-key your-access \
--secret-key your-secret \
"redis://:redis-password@your-redis.xxx.com:6379" \
hf-jfs
其中,
hf-jfs是 JuiceFS 文件系统的名称,可以自定义;--storage s3指定对象存储类型为 S3,可以参考官方文档了解更多对象存储类型;- 元数据引擎 URL 以
redis://开头,紧接着是 Redis 的用户名和密码,使用 : 分隔,然后是 Redis 的地-址和端口号,使用 @ 分隔。建议使用引号包裹整个 URL。
将 JuiceFS 预先挂载到 Hugging Face 缓存目录
如果还没有安装 Hugging Face Transformers,则可以预先创建数据缓存目录,并将 JuiceFS 挂载到该目录。
# 创建 Hugging Face 缓存目录
mkdir -p ~/.cache/huggingface
# 挂载 JuiceFS 到 Hugging Face 缓存目录
juicefs mount -d "redis://:redis-password@your-redis.xxx.com:6379" ~/.cache/huggingface
紧接着再安装 Hugging Face Transformers,它会自动将数据缓存到 JuiceFS 中,例如:
pip install transformers datasets evaluate accelerate
由于不同硬件和环境涉及的包会有所不同,请根据实际情况进行安装配置,这里不做展开。
通过环境变量指定 Hugging Face 缓存目录
另一种方法是通过环境变量指定 Hugging Face 缓存目录,这样可以在不修改代码的情况下,将 Hugging Face 缓存目录指向 JuiceFS 挂载的目录。
比如,JuiceFS 的挂载目录是 /mnt/jfs:
juicefs mount -d "redis://:redis-password@your-redis.xxx.com:6379" /mnt/jfs
通过 HUGGINGFACE_HUB_CACHE 或 TRANSFORMERS_CACHE 环境变量指定 Hugging Face 缓存目录:
export HUGGINGFACE_HUB_CACHE=/mnt/jfs
这样,Hugging Face Transformers 就会将数据缓存到 JuiceFS 挂载的目录中。
随处使用 Hugging Face 缓存数据
得益于 JuiceFS 分布式多端共享存储的特性,用户只需将 Hugging Face 的缓存目录设置到 JuiceFS 挂载点,并完成首次模型资源的下载即可。
随后,在任何需要该资源的节点上挂载 JuiceFS,选择上述两种方法之一进行设置,即可复用缓存数据。JuiceFS 采用 “close-to-open” 机制,确保在多个节点上共享读写相同数据时的数据一致性。
需要注意的是,从 Hugging Face 下载模型资源的速度会受到网络环境的影响,不同国家和地区、不同网络线路的速度可能有所不同。此外,在使用 JuiceFS 共享数据缓存目录时,也可能面临类似的网络延迟问题。为了有效改善速度,建议尽量提升带宽,并降低工作节点与 JuiceFS 底层对象存储以及访问元数据引擎之间的网络延迟。
总结
本文介绍了 JuiceFS 作为 Hugging Face Transformers 的数据缓存目录的两种方法,分别是将 JuiceFS 预先挂载到 Hugging Face 缓存目录,以及通过环境变量指定 Hugging Face 缓存目录。这两种方法都可以实现 AI 训练资源在多个节点间共享复用。
如果你有多个节点需要访问相同的 Hugging Face 缓存数据,或者希望在不同环境中载入相同的训练资源,JuiceFS 也许是一个非常理想的选择。
希望本文介绍的内容能够对你在 AI 模型训练的过程中提供一定的帮助,如果有相关问题欢迎加入 JuiceFS 微信群与社区用户共同交流讨论。
