














光影焕像(Lightillusions)是一家专注于空间智能技术,结合 3D 视觉、图形学和生成模型技术,致力于打造创新的 3D 基础模型公司。公司由谭平教授领导,谭教授曾担任阿里巴巴达摩院实验室负责人,目前是香港科技大学的教授,同时担任冯诺伊曼人工智能研究室副院长,并是香港科技大学与比亚迪联合实验室的主任。
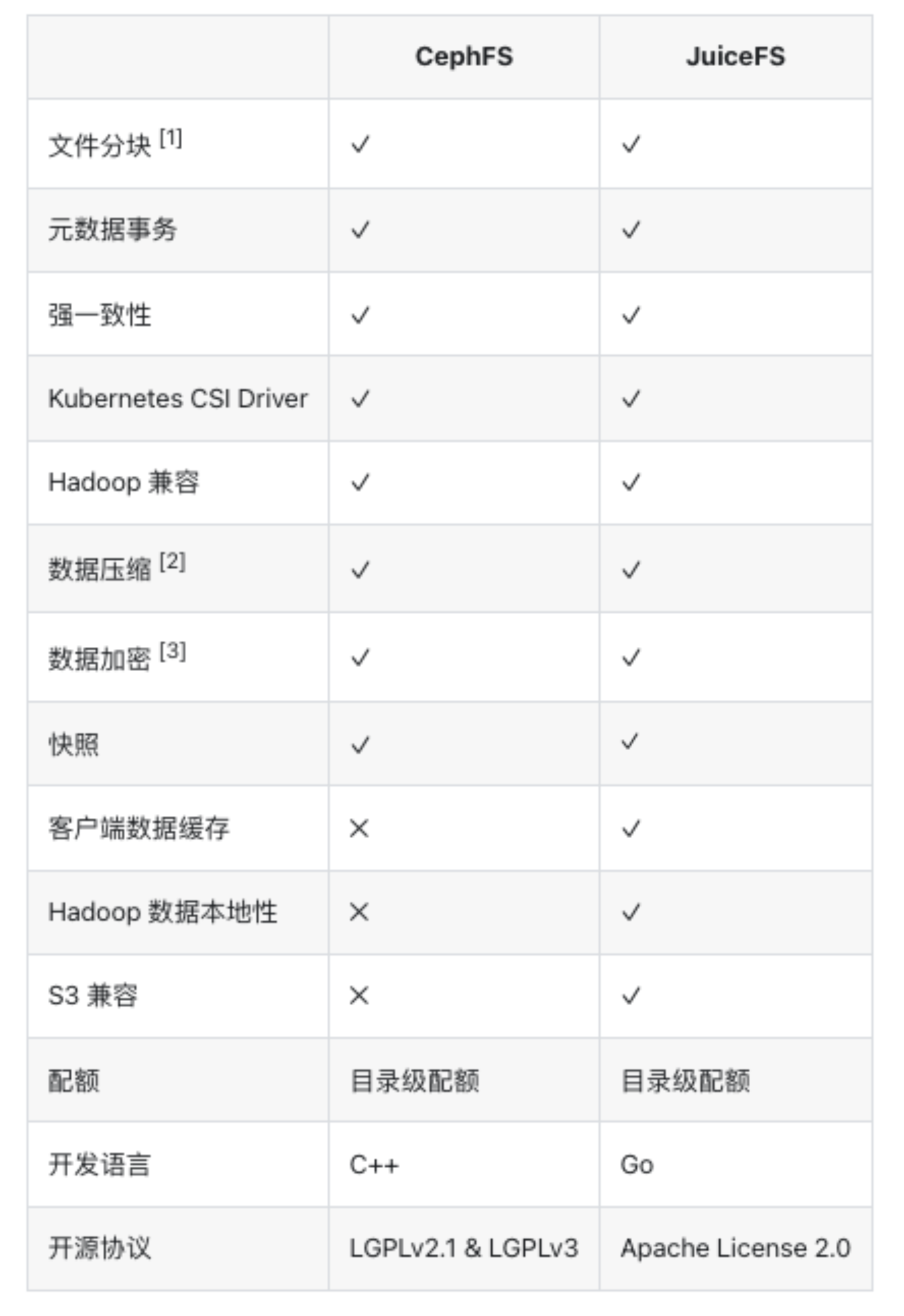
区别于二维模型,三维模型单个模型的大小可达几 GB,尤其是点云数据等复杂模型。当数据量达到 PB 级别时,管理与存储成为巨大的挑战。经过尝试 NFS、GlusterFS 等方案后,我们最终选择了 JuiceFS,成功搭建了一个统一的存储平台,为多个场景服务,并支持跨平台访问,包括 Windows 和 Linux 系统。该平台目前已管理上亿文件,数据处理速度提升了 200%~250%,还实现了高效的存储扩容,同时运维管理得到了极大简化,使得团队能够更专注于核心任务的推进。
01 3D-AIGC 存储需求
我们的研究主要集中在感知和生成两个方向。在三维领域,任务的复杂性与图像和文本处理有本质区别,这对我们的 AI 模型、算法以及基础设施建设都提出了更高的要求。
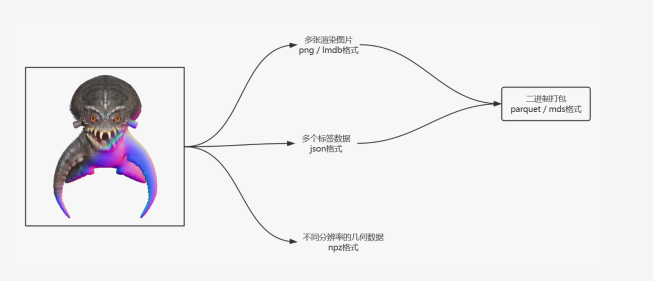
我们通过一个 3D 数据处理流程,来展示三维数据处理的复杂性。下图左侧是一个三维模型,包含纹理(左上角的折射纹理)和几何信息(右下角的几何结构)。首先,我们生成渲染图像。每个模型还附带文本标签,描述其内容、几何特征和纹理特征,这些标签与每个模型紧密相关。此外,我们还处理几何数据,如采样点以及从数据预处理过程中得到的必要数值(如 3DS、SDF 等)。需要注意的是,三维模型的文件格式非常多样,图片格式也各不相同。
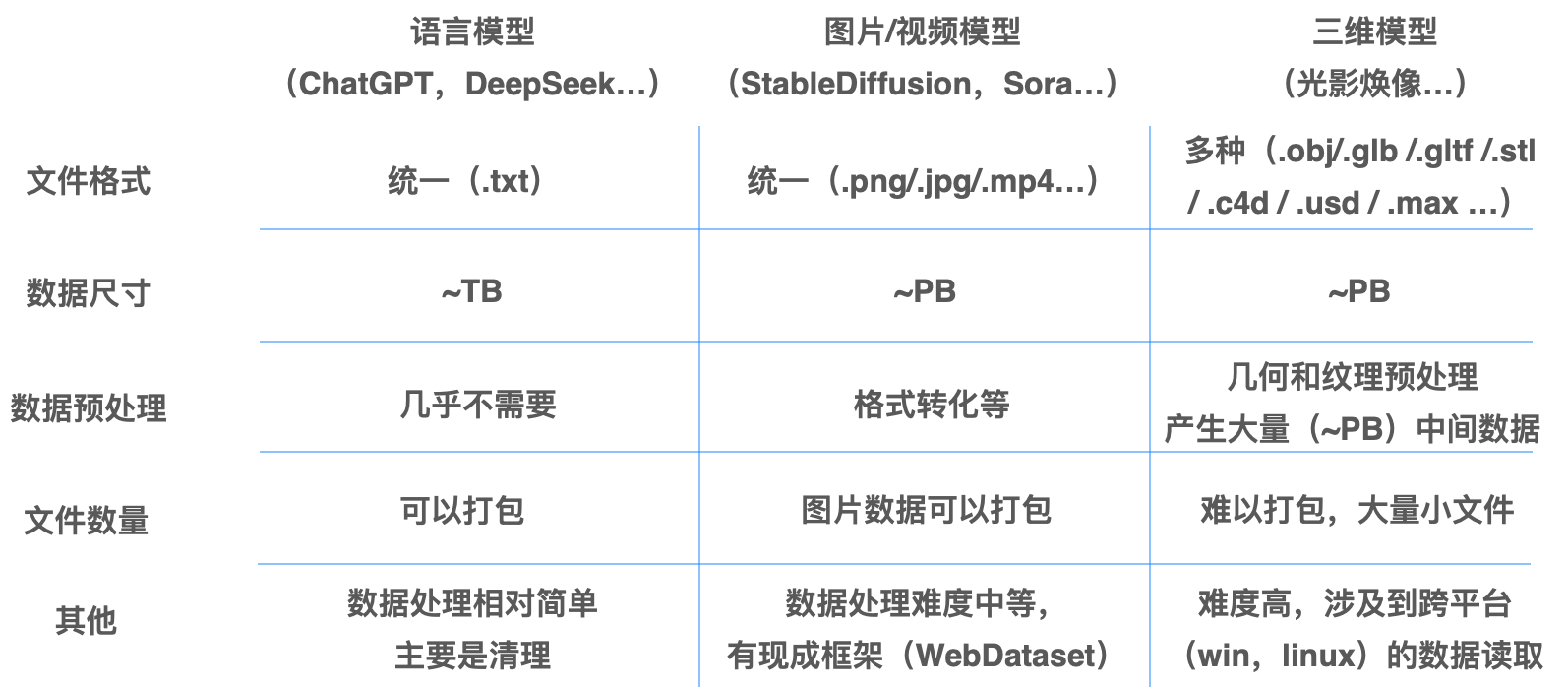
我们的工作场景涉及语言模型、图像/视频模型到三维模型,随着数据量的增长,存储负担也在不断增加。以下是这些场景中数据使用的主要特点:
- 语言模型的数据通常由大量小文件组成。尽管单个文本文件较小,但随着数据量的增加,文件数量可能达到数百万甚至数千万个,这使得管理如此庞大的文件数成为存储的一个主要难点。
- 图像和视频数据,尤其是高分辨率图像和长时间的视频,通常较为庞大。单张图像的大小通常在几百 KB 到几 MB 之间,而视频文件可能达到 GB 级别。在预处理过程中,如数据增强、分辨率调整和帧提取等,数据量会显著增加,特别是在视频处理中,每个视频通常会被拆解为大量的图像文件,管理这些庞大的文件集,带来了更高的复杂性。
- 三维模型,特别是点云数据等复杂模型,单个模型的大小可达几 GB。三维数据的预处理过程比其他数据更加复杂,涉及纹理映射、几何重建等多个步骤,这些处理不仅消耗大量计算资源,还可能增加数据体积。此外,三维模型通常由多个文件组成,文件数量庞大,随着数据量的增长,管理这些文件的难度也会增加。
由上述环节的存储特点,我们希望构建的存储平台能够满足以下几项要求:
-
多样的数据格式与跨节点共享:不同模型的数据格式差异较大,特别是三维模型的格式复杂性和跨平台兼容问题,存储系统需要支持多种格式,并有效管理跨节点和跨平台的数据共享。
-
可以处理不同尺寸的数据模型:无论是语言模型的小文件、大规模图片/视频数据,还是三维模型的大文件,存储系统必须具备高扩展性,以应对快速增长的存储需求,并高效处理大尺寸数据的存储和访问。
-
跨云与集群存储的挑战:随着数据量的增加,特别是三维模型的 PB 级存储需求,跨云和集群存储问题愈加突出。存储系统需要支持跨区域、跨云的无缝数据访问和高效的集群管理。
-
方便扩容:无论是语言模型、图片/视频模型,还是三维模型,扩容需求始终存在,尤其是三维模型的存储和处理对扩容的需求更高。
-
简单的运维:存储系统应提供简便的管理界面和工具,尤其是对于三维模型的管理,运维要求更高,自动化管理和容错能力是必不可少的。
02 存储方案探索:从 NFS、Gluster、CephFS 到 JuiceFS
前期方案:NFS 挂载
最初,我们采用了最简单的方案——使用 NFS 进行挂载。然而,在实际操作中,我们发现训练集群和渲染集群需要各自独立的集群来进行挂载操作。这种方式的维护非常繁琐,尤其是当添加新的数据时,我们需要单独为每个新数据写入挂载点。到了数据量达到约 100 万物体级别时,我们已经无法继续维持这种方案,因此在早期阶段,我们就放弃了这一方案。
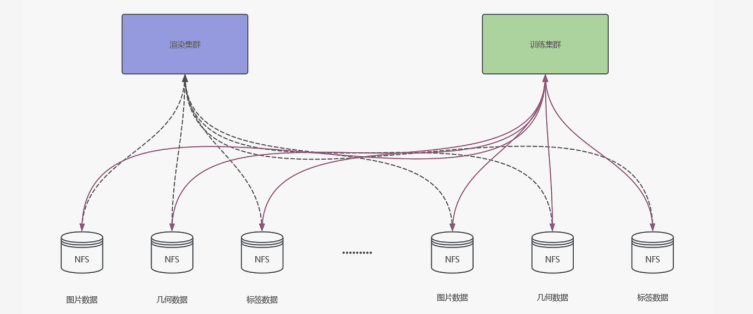
中期方案:GlusterFS
GlusterFS 是一个相对易于上手的选择,安装配置简单,性能也能得到一定保障,且无需划分多个挂载点,只需增加新节点即可。虽然在前期使用时,GlusterFS 大大减轻了我们的工作量,但我们也发现它的生态系统存在一些问题。
首先,GlusterFS 许多执行脚本和功能需要手动编写定时任务。特别是在添加新存储时,它还会有一些额外要求,例如需要按特定倍数增加节点。此外,像克隆、数据同步等操作的支持也相对较弱,导致我们在使用过程中频繁查阅文档,且许多操作并不稳定。例如,使用 FIO 等工具进行测速时,结果并不总是可靠。
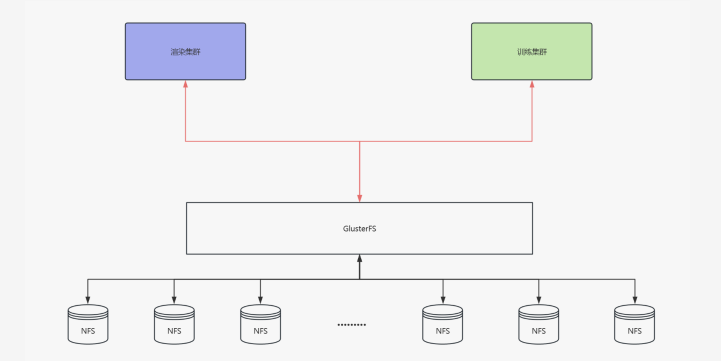
更为严重的问题是,当存储的小文件数量达到一定规模时,GlusterFS 的性能会急剧下降。举个例子,一个模型可能会生成 100 张图片,若有 1000 万个模型,就会产生 10 亿张图片。GlusterFS 在后期的寻址变得极为困难,尤其是小文件过多时,性能会显著下降,导致系统崩溃。
最终选型:CephFS vs JuiceFS
随着存储需求的增加,我们决定转向可持续性更好的方案。在评估了多种方案后,我们主要对比了 CephFS 和 JuiceFS。虽然 Ceph 被广泛使用,但通过自己的实践和对比文档,我们发现 Ceph 的运维和管理成本非常高,尤其对于我们这样的小团队来说,处理这些复杂的运维任务显得尤为困难。
JuiceFS 有两个原生自带的特性非常符合我们的需求。首先是客户端数据缓存功能。对于我们的模型训练集群,通常会配备高性能的 NVMe 存储。如果能够充分利用客户端的缓存,便能显著加速模型训练,并减少对 JuiceFS 存储的压力。
其次,JuiceFS 对 S3 的兼容性对我们也至关重要。由于我们基于存储开发了一些可视化平台用于数据标注、整理和统计,S3 兼容性使得我们能够快速进行网页开发,支持可视化和数据统计操作等功能。
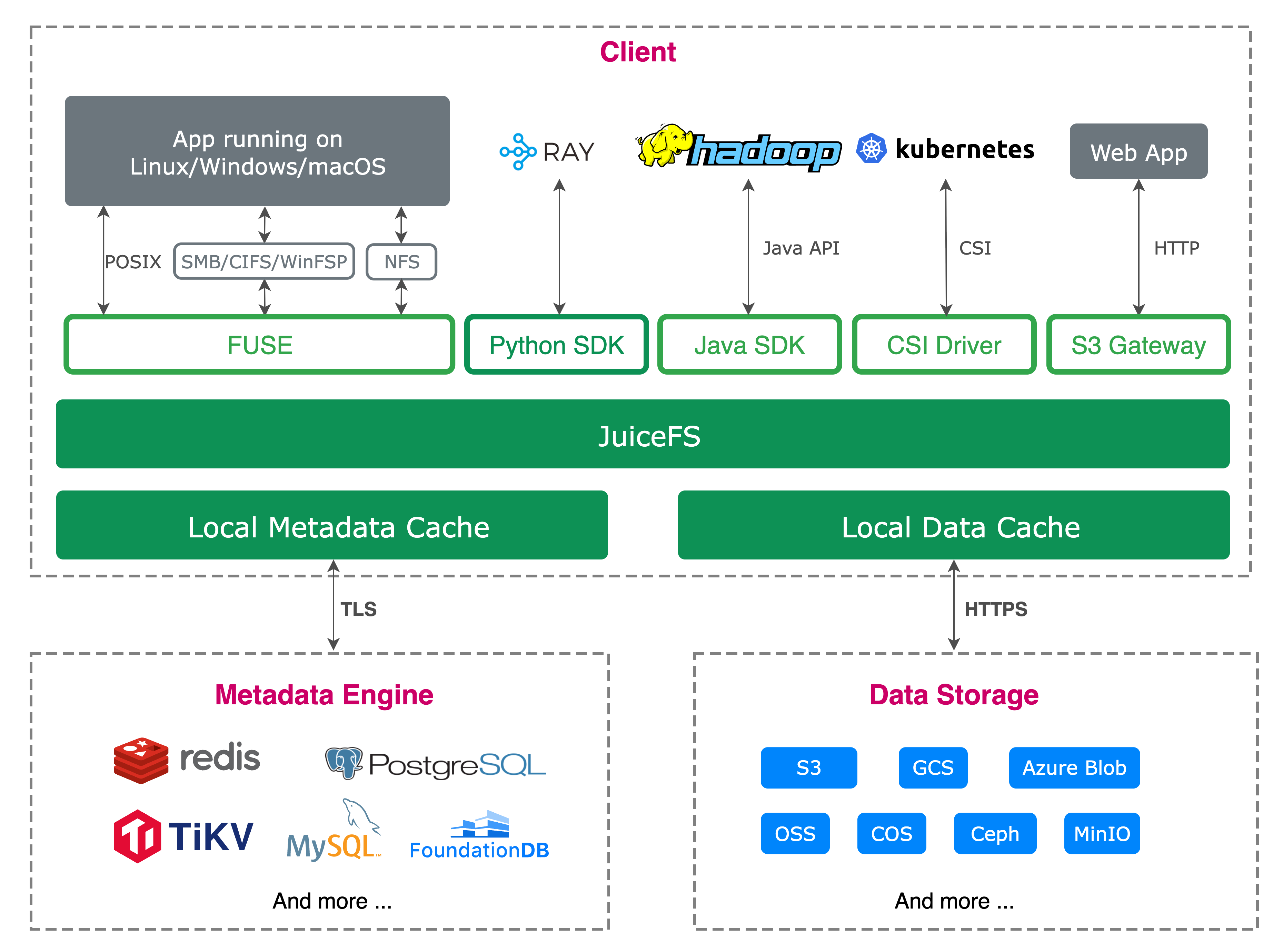
03 基于 JuiceFS 的存储平台实践
元数据引擎选择与拓扑
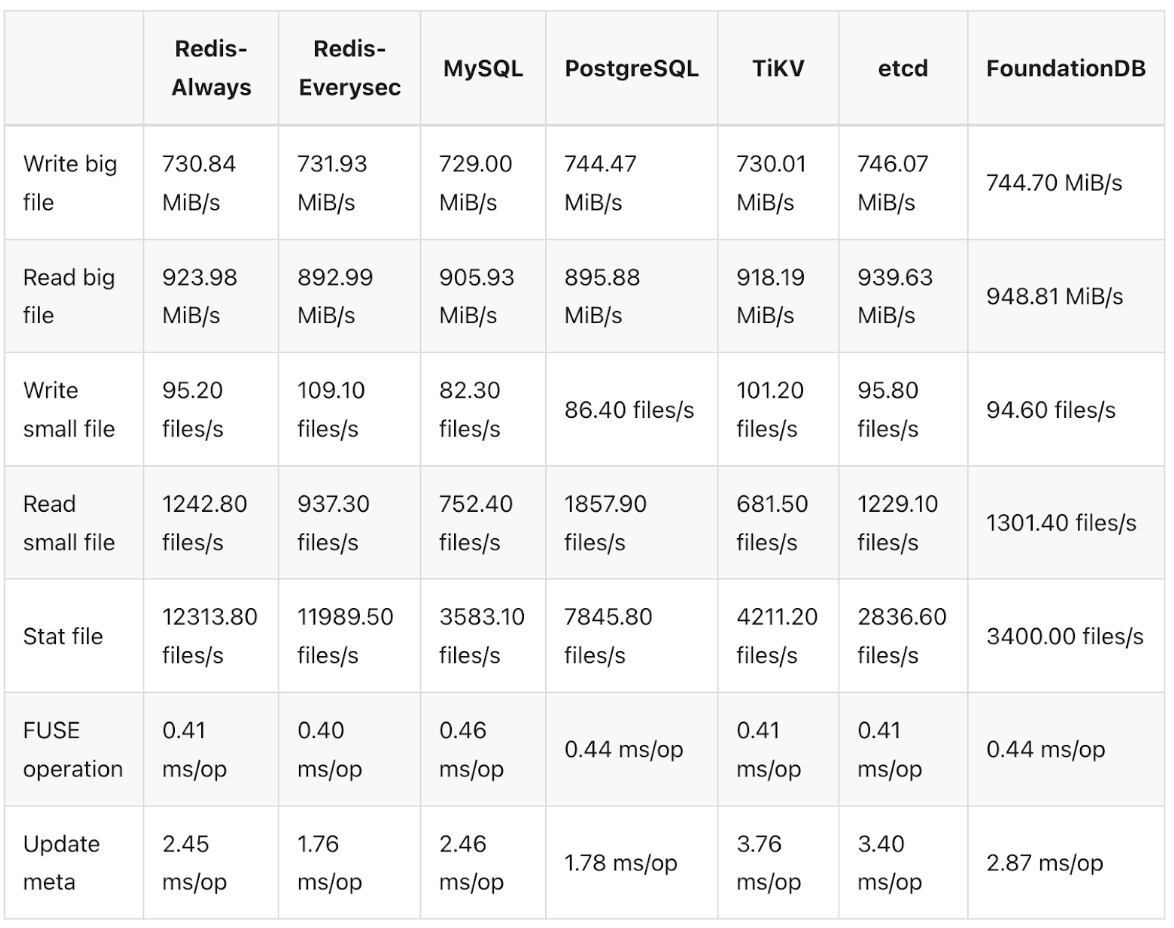
JuiceFS 采用的是元数据与数据分离的架构,有多种元数据引擎可供选择。我们首先快速验证了 Redis 存储方案,官方提供了详细的文档支持。Redis 的优势在于其轻量化,配置过程通常只需一天或半天时间,数据迁移也相对顺利。然而,当小文件数量超过 1 亿时,Redis 的速度和性能会显著下降。
正如之前提到的,每个模型可能会渲染出 100 张图片,再加上其他杂项文件,导致小文件的数量急剧增加。虽然我们可以通过打包小文件来减轻问题,但一旦打包后进行修改或可视化操作,复杂性就大大增加。因此,我们希望能够保留原始的小图片文件,以便后续处理。
随着文件数量的增加,很快超出 Redis 的处理能力,我们决定将存储系统迁移到 TiKV 和 Kubernetes 组合上。TiKV 与 K8s 的组合能够为我们提供更高可用的元数据存储方案。此外,通过基准测试我们发现,尽管 TiKV 的性能稍逊一筹,但差距并不显著,且相较于 Redis,它对小文件的支持更好。我们也咨询过 JuiceFS 的工程师,了解到 Redis 在集群模式下的扩展性较差,于是我们准备切换到 TiKV。
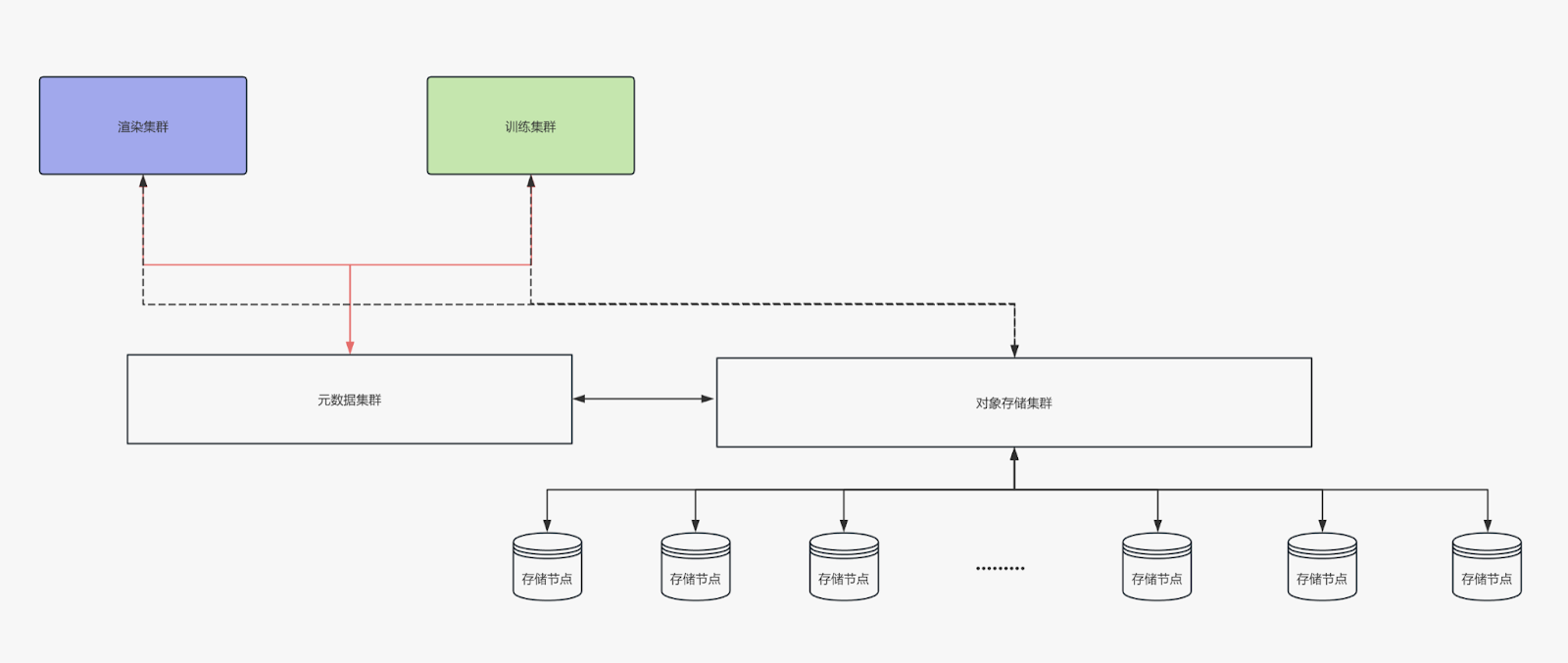
最新架构:JuiceFS + TiKV + SeaweedFS
我们使用了 JuiceFS 来管理对象存储。TiKV 和 K8s 来搭建元数据存储系统。对象存储部分使用了 SeaweedFS,这使得我们能够快速扩展存储规模,且无论是小数据还是大数据,访问速度都很快。此外,我们的对象存储分布在多个平台:包括本地存储、阿里云存储以及国外的 R2 和 Amazon 对象存储。通过 JuiceFS,我们能够将这些不同存储系统集成起来,并提供一个统一的接口。
为了更好地管理系统资源,我们在 K8s 上搭建了资源监控平台。当前系统由大约 60 台 Linux 机器和若干 Windows 机器组成,负责渲染和数据处理任务。我们对读取稳定性进行了监控,结果显示,即使是多台异构服务器同时进行读取操作,整个系统的 I/O 性能依然非常稳定,基本能够充分利用带宽资源。

实践中遇到的问题
在优化存储方案的过程中,我们最初尝试了 EC(纠删码) 存储方案,旨在减少存储需求并提升效率。然而,在大规模数据迁移中,EC 存储的计算速度较慢,并且在高吞吐量和频繁数据变化的场景下,性能表现不佳,尤其与 SeaweedFS 结合时,存在性能瓶颈。基于这些问题,我们决定放弃 EC 存储,转而采用副本存储方案。
我们设置了独立服务器并配置了定时任务,以进行大数据量的元数据备份。在 TiKV 中,我们实现了冗余副本机制,采用了多个副本方案来确保数据的完整性。同时,在对象存储方面,我们采用了双副本编码来进一步提高数据可靠性。虽然副本存储能够有效保证数据冗余和高可用性,但由于处理 PB 级数据和大量增量数据,存储成本依然较高。未来,我们可能会考虑进一步优化存储方案,以降低存储成本。
另外,我们也发现当使用全闪存服务器 + JuiceFS 并未带来显著的性能提升。瓶颈主要出现在网络带宽和延迟上。因此,我们计划在后期考虑使用 InfiniBand(IB)连接存储服务器和训练服务器,以最大化资源利用效率。
04 小结
在使用 GlusterFS 时,我们每天最多只能处理 20 万个模型;而切换到 JuiceFS 后,处理能力大幅提升,日均数据处理能力增加了 2.5 倍,小文件吞吐能力也显著提高,特别是在存储量达到 70% 后,系统仍能保持稳定运行。此外,扩容也非常便捷,而之前的架构,扩容过程非常繁琐,操作起来比较麻烦。
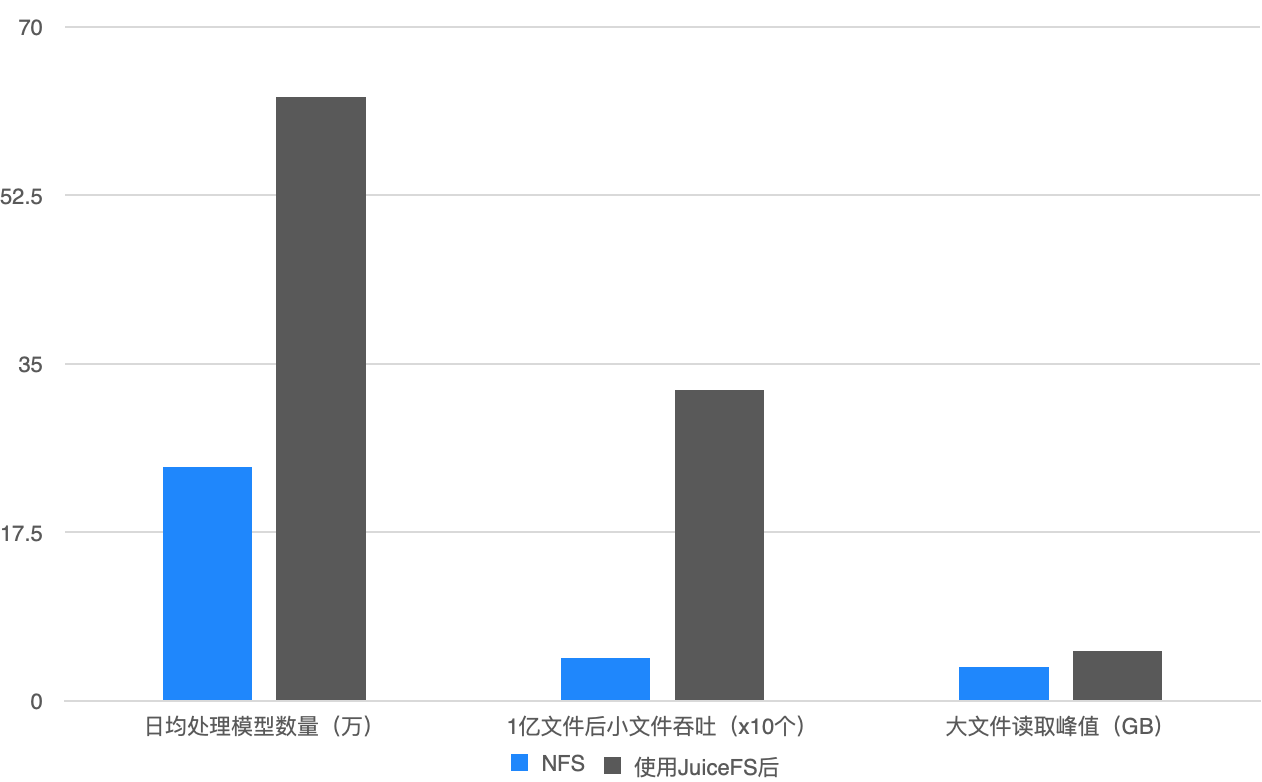
最后再总结一下 JuiceFS 在三维生成任务中表现出来的优势:
-
小文件性能: 小文件处理能力是一个关键点,JuiceFS 依然提供了一个较好的解决方案。
-
跨平台特性: 跨平台支持非常重要。我们发现有些数据只能在 Windows 软件中打开,因此需要同时在 Windows 和 Linux 系统上处理相同的数据,并在同一个挂载节点上进行读写。这种需求使得跨平台的特性尤为关键,JuiceFS 的设计很好地解决了这一问题。
-
低运维成本: JuiceFS 的运维成本极低。配置完成后,只需要进行一些简单的测试和节点的管理(例如,丢弃某些节点并监控鲁棒性)。我们在迁移数据时花费了大约半年的时间,到目前为止并未遇到太大的问题。
-
本地缓存机制: 之前,如果想使用本地缓存,我们需要手动在代码中实现本地缓存逻辑,但 JuiceFS 提供了非常方便的本地缓存机制,通过设置挂载参数来优化训练场景的性能。
-
迁移成本低: 尤其是在迁移小文件时,我们发现使用 JuiceFS 进行元数据和对象存储的迁移非常方便,节省了我们大量时间和精力。相比之下,之前使用其他存储系统迁移时,过程非常痛苦。
综上所述,JuiceFS 在大规模数据处理中的表现非常出色,提供了高效、稳定的存储解决方案。它不仅简化了存储管理和扩容过程,还大大提升了系统性能,让我们能够更加专注于核心任务的推进。
此外,官方提供一些工具也非常便捷,例如我们使用 Sync 在处理小文件迁移时,效率极高。在没有额外性能优化的情况下,我们成功迁移了 500TB 的数据,其中包含大量的小数据和图片文件,迁移时间不到 5 天,结果超出我们的预期。
