














正文
AI 企业为什么选择 JuiceFS?
千亿文件规模
JuiceFS 能在单一卷中管理高达千亿个文件,这一能力已在多家企业的生产环境中得到验证,适用于处理各类大规模 AI 数据集。
云原生设计
JuiceFS 专为云环境设计,可以在全球公有云上部署,并无缝集成到现有云基础设施中,适应不同的云平台和区域要求。
高吞吐、低延迟
在模型训练中,JuiceFS 可提供数百 GiB/s 的读吞吐量,支持每秒读取数十万个文件,并具有毫秒级的元数据响应时间。通过灵活的缓存配置,JuiceFS 能够提供无限的聚合吞吐能力,显著减少 GPU 的等待时间,从而提高整体的计算效率。
可支持混合云、多云架构
在跨多区域使用 GPU 资源时,JuiceFS 能保证数据在全球范围内的就近访问和一致性。有效减轻了跨区域访问的成本负担,并优化了数据调度与分发,适用于混合云、多云架构。
安全性
JuiceFS 可为不同团队共享存储系统提供数据隔离和安全性保障:基于访问令牌(Token)的挂载和访问控制、Linux 文件权限(File Permission)、POSIX ACL、子目录挂载、容量与 Inode 配额、流量 QoS 等能力。
成本优势
自动驾驶领域数据增长迅速,JuiceFS 通过对象存储作为底层存储,实现了容量的弹性扩展,并有效降低了存储成本。同时,JuiceFS 的灵活架构有助于降低学习、维护和迁移成本。
相关产品特性
案例: Lepton AI 如何构建多租户、低延迟云存储平台
基于 JuiceFS,Lepton AI 利用其高性能的缓存机制显著加速了文件操作,显著降低了由于对象存储引发的延迟问题,并与此前使用的 AWS EFS 相比,存储成本降低了 30 到 50 分之一。[详情]
方案:AI 平台存储方案选型与最佳实践
在 AI 场景下,存储的挑战具体有哪些?市场上有哪些解决方案?为何选择 JuiceFS ?【详情】
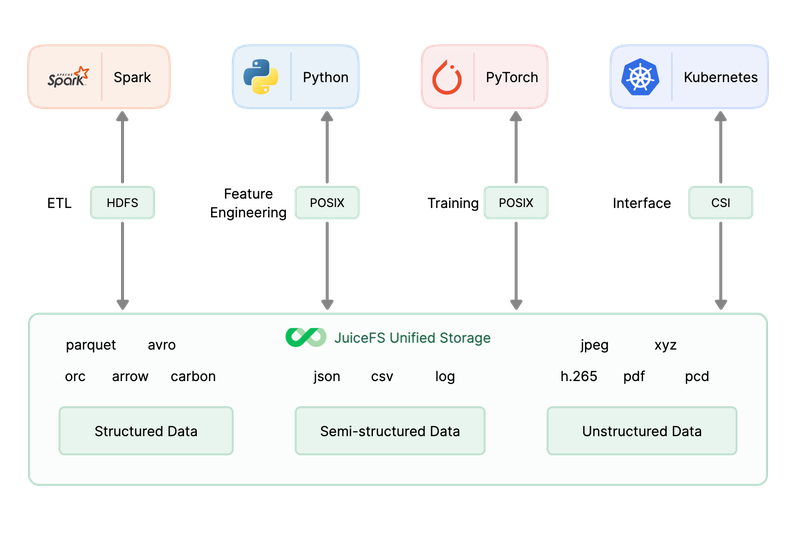
JuiceFS 被应用于多个行业的 AI 应用中

















