在 Hadoop 生态使用 JuiceFS
JuiceFS 提供与 HDFS 接口高度兼容的 Java 客户端,Hadoop 生态中的各种应用都可以在不改变代码的情况下,平滑地使用 JuiceFS 存储数据。
环境要求
1. Hadoop 及相关组件
JuiceFS Hadoop Java SDK 同时兼容 Hadoop 2.x、Hadoop 3.x,以及 Hadoop 生态中的各种主流组件。
2. 用户权限
JuiceFS 默认使用本地的「用户/UID」及「用户组/GID」映射,在分布式环境下使用时,为了避免权限问题,请参考文档将需要使用的「用户/UID」及「用户组/GID」同步到所有 Hadoop 节点。也可以通过定义一个全局的用户和用户组文件使得集群中的所有节点共享权限配置,相关配置请查看这里。
3. 文件系统
通过 JuiceFS Java 客户端为 Hadoop 生态提供存储,需要提前创建 JuiceFS 文件系统。部署 Java 客户端时,在配置文件中指定已创建文件系统的元数据引擎地址。
创建文件系统可以参考 JuiceFS 快速上手指南。
如果要在分布式环境中使用 JuiceFS,创建文件系统时,请合理规划要使用的对象存储和数据库,确保它们可以被每个集群节点正常访问。
4. 内存资源
根据计算任务(如 Spark executor)的读写负载,JuiceFS Hadoop Java SDK 可能需要额外使用 4 * juicefs.memory-size 的堆外内存用来加速读写性能。默认情况下,建议为计算任务至少配置 1.2GB 的堆外内存。
5. Java 运行时版本
JuiceFS Hadoop Java SDK 默认使用 JDK 8 编译,如果需要在高版本的 Java 运行时中使用(如 Java 17),需在 JVM 参数中增加以下选项以允许使用反射 API:
--add-exports=java.base/sun.nio.ch=ALL-UNNAMED
更多关于以上选项的说明请参考官方文档。
安装与编译客户端
安装预编译客户端
请参考「安装」文档了解如何下载预编译的 JuiceFS Hadoop Java SDK。
手动编译客户端
不论为哪个系统环境编译客户端,编译后的 JAR 文件都为相同的名称,且只能部署在匹配的系统环境中,例如在 Linux 中编译则只能用于 Linux 环境。另外,由于编译的包依赖 glibc,建议尽量使用低版本的系统进行编译,这样可以获得更好的兼容性。
编译依赖以下工具:
- Go 1.15+(中国用户建议使用 Goproxy China 镜像加速)
- JDK 8+
- Maven 3.3+(中国用户建议使用阿里云镜像加速)
- Git
- make
- GCC 5.4+
Linux 和 macOS
克隆仓库:
git clone https://github.com/juicedata/juicefs.git
进入目录,执行编译:
cd juicefs/sdk/java
make
如果使用 Ceph 的 RADOS 作为 JuiceFS 的存储引擎,需要先安装 librados-dev 包。
cd juicefs/sdk/java
make ceph
编译完成后,可以在 sdk/java/target 目录中找到编译好的 JAR 文件,包括两个版本:
- 包含第三方依赖的包:
juicefs-hadoop-X.Y.Z.jar - 不包含第三方依赖的包:
original-juicefs-hadoop-X.Y.Z.jar
建议使用包含第三方依赖的版本。
Windows
用于 Windows 环境的客户端需要在 Linux 或 macOS 系统上通过交叉编译的方式获得,编译依赖 mingw-w64,需要提前安装。
与编译面向 Linux 和 macOS 客户端的步骤相同,比如在 Ubuntu 系统上,先安装 mingw-w64 包,解决依赖问题:
sudo apt install mingw-w64
克隆并进入 JuiceFS 源代码目录,执行以下代码进行编译:
cd juicefs/sdk/java
make win
部署客户端
让 Hadoop 生态各组件能够正确识别 JuiceFS,需要进行以下配置:
- 将编译好的 JAR 文件和
$JAVA_HOME/lib/tools.jar放置到组件的classpath内,常见大数据平台和组件的安装路径见下表。 - 将 JuiceFS 相关配置写入配置文件(通常是
core-site.xml),详见客户端配置参数。
建议将 JAR 文件放置在一个统一的位置,其他位置通过符号链接进行调用。
大数据平台
| 名称 | 安装路径 |
|---|---|
| CDH | /opt/cloudera/parcels/CDH/lib/hadoop/lib/opt/cloudera/parcels/CDH/spark/jars/var/lib/impala |
| HDP | /usr/hdp/current/hadoop-client/lib/usr/hdp/current/hive-client/auxlib/usr/hdp/current/spark2-client/jars |
| Amazon EMR | /usr/lib/hadoop/lib/usr/lib/spark/jars/usr/lib/hive/auxlib |
| 阿里云 EMR | /opt/apps/ecm/service/hadoop/*/package/hadoop*/share/hadoop/common/lib/opt/apps/ecm/service/spark/*/package/spark*/jars/opt/apps/ecm/service/presto/*/package/presto*/plugin/hive-hadoop2/opt/apps/ecm/service/hive/*/package/apache-hive*/lib/opt/apps/ecm/service/impala/*/package/impala*/lib |
| 腾讯云 EMR | /usr/local/service/hadoop/share/hadoop/common/lib/usr/local/service/presto/plugin/hive-hadoop2/usr/local/service/spark/jars/usr/local/service/hive/auxlib |
| UCloud UHadoop | /home/hadoop/share/hadoop/common/lib/home/hadoop/hive/auxlib/home/hadoop/spark/jars/home/hadoop/presto/plugin/hive-hadoop2 |
| 百度云 EMR | /opt/bmr/hadoop/share/hadoop/common/lib/opt/bmr/hive/auxlib/opt/bmr/spark2/jars |
社区开源组件
| 名称 | 安装路径 |
|---|---|
| Hadoop | ${HADOOP_HOME}/share/hadoop/common/lib/, ${HADOOP_HOME}/share/hadoop/mapreduce/lib/ |
| Spark | ${SPARK_HOME}/jars |
| Presto | ${PRESTO_HOME}/plugin/hive-hadoop2 |
| Trino | ${TRINO_HOME}/plugin/hive |
| Flink | ${FLINK_HOME}/lib |
| StarRocks | ${StarRocks_HOME}/fe/lib/, ${StarRocks_HOME}/be/lib/hadoop/common/lib |
客户端配置参数
请参考以下表格设置 JuiceFS 文件系统相关参数,并写入配置文件,一般是 core-site.xml。
核心配置
| 配置项 | 默认值 | 描述 |
|---|---|---|
fs.jfs.impl | io.juicefs.JuiceFileSystem | 指定要使用的存储实现,默认使用 jfs:// 作为 scheme。如想要使用其它 scheme(例如 cfs://),则修改为 fs.cfs.impl 即可。无论使用的 scheme 是什么,访问的都是 JuiceFS 中的数据。 |
fs.AbstractFileSystem.jfs.impl | io.juicefs.JuiceFS | 指定要使用的存储实现,默认使用 jfs:// 作为 scheme。如想要使用其它 scheme(例如 cfs://),则修改为 fs.AbstractFileSystem.cfs.impl 即可。无论使用的 scheme 是什么,访问的都是 JuiceFS 中的数据。 |
juicefs.meta | 指定预先创建好的 JuiceFS 文件系统的元数据引擎地址。可以通过 juicefs.{vol_name}.meta 格式为客户端同时配置多个文件系统。具体请参考「多文件系统配置」。 |
缓存配�置
| 配置项 | 默认值 | 描述 |
|---|---|---|
juicefs.cache-dir | 设置本地缓存目录,可以指定多个文件夹,用冒号 : 分隔,也可以使用通配符(比如 * )。请预先创建好这些目录,并给予 0777 权限,便于多个应用共享缓存数据。 | |
juicefs.cache-size | 0 | 设置本地缓存目录的容量,单位 MiB,默认为 0,即不开启缓存。如果配置了多个缓存目录,该值代表所有缓存目录容量的总和。 |
juicefs.cache-full-block | true | 是否缓存所有读取的数据块,false 表示只缓存随机读的数据块。 |
juicefs.free-space | 0.1 | 本地缓存目录的最小可用空间比例,默认保留 10% 剩余空间。 |
juicefs.open-cache | 0 | 缓存打开的文件元数据(单位:秒),0 表示关闭 |
juicefs.attr-cache | 0 | 目录和文件属性缓存的过期时间(单位:秒) |
juicefs.entry-cache | 0 | 文件项缓存的过期时间(单位:秒) |
juicefs.dir-entry-cache | 0 | 目录项缓存的过期时间(单位:秒) |
juicefs.discover-nodes-url | 指定发现集群缓存节点列表的方式,每 10 分钟刷新一次。
|
I/O 配置
| 配置项 | 默认值 | 描述 |
|---|---|---|
juicefs.max-uploads | 20 | 上传数据的最大连接数 |
juicefs.max-downloads | 200 | 下载连接的最大数量 |
juicefs.max-deletes | 10 | 删除数据的最大连接数 |
juicefs.get-timeout | 5 | 下载一个对象的超时时间,单位为秒。 |
juicefs.put-timeout | 60 | 上传一个对象的超时时间,单位为秒。 |
juicefs.memory-size | 300 | 读写数据的缓冲区最大空间,单位为 MiB。 |
juicefs.prefetch | 1 | 预读数据块的线程数 |
juicefs.upload-limit | 0 | 上传带宽限制,单位为 Mbps,默认不限制。 |
juicefs.download-limit | 0 | 下载带宽限制,单位为 Mbps,默认不限制。 |
juicefs.io-retries | 10 | IO 失败重试次数 |
juicefs.writeback | false | 是否后台异步上传数据 |
其它配置
| 配置项 | 默认值 | 描述 |
|---|---|---|
juicefs.bucket | 为对象存储指定跟格式化时不同的访问地址 | |
juicefs.debug | false | 是否开启 debug 日志 |
juicefs.access-log | 访问日志的路径。需要所有应用都有写权限,可以配置为 /tmp/juicefs.access.log。该文件会自动轮转,保留最近 7 个文件。 | |
juicefs.superuser | hdfs | 超级用户 |
juicefs.supergroup | supergroup | 超级用户组 |
juicefs.users | null | 用户名以及 UID 列表文件的地址,比如 jfs://name/etc/users。文件格式为 <username>:<UID>,一行一个用户。 |
juicefs.groups | null | 用户组、GID 以及组成员列表文件的地址,比如 jfs://name/etc/groups。文件格式为 <group-name>:<GID>:<username1>,<username2>,一行一个用户组。 |
juicefs.umask | null | 创建文件和目录的 umask 值(如 0022),如果没有此配置,默认值是 fs.permissions.umask-mode。 |
juicefs.push-gateway | Prometheus Pushgateway 地址,格式为 <host>:<port>。 | |
juicefs.push-auth | Prometheus 基本认证信息,格式为 <username>:<password>。 | |
juicefs.push-graphite | Graphite 地址,格式为 <host>:<port>。 | |
juicefs.push-interval | 10 | 指标推送的时间间隔,单位为秒。 |
juicefs.push-labels | 指标额外标签,格式为 key1:value1;key2:value2。 | |
juicefs.fast-resolve | true | 是否开启快速元数据查找(通过 Redis Lua 脚本实现) |
juicefs.no-usage-report | false | 是否上报数据。仅上版本号等使用量数据,不包含任何用户信息。 |
juicefs.block.size | 134217728 | 单位为字节,同 HDFS 的 dfs.blocksize,默认 128 MB |
juicefs.file.checksum | false | DistCp 使用 -update 参数时,是否计算文件 Checksum |
juicefs.no-bgjob | false | 是否关闭后台任务(清理、备份等) |
juicefs.backup-meta | 3600 | 自动将 JuiceFS 元数据备份到对象存储间隔(单位:秒),设置为 0 关闭自动备份 |
juicefs.backup-skip-trash | false | 备份元数据时忽略回收站中的文件和目录。 |
juicefs.heartbeat | 12 | 客户端和元数据引擎之间的心跳间隔(单位:秒),建议所有客户端都设置一样 |
juicefs.skip-dir-mtime | 100ms | 修改父目录 mtime 间隔。 |
juicefs.subdir | 仅允许访问此目录的子路径。可以指定多个路径,使用逗号分隔。所有其他路径,包括根目录或同级目录,都将被拒绝访问。 |
多文件系统配置
当需要同时使用多个 JuiceFS 文件系统时,上述所有配置项均可对特定文件系统进行指定,只需要将文件系统名字放在配置项的中间,比如下面示例中的 jfs1 和 jfs2:
<property>
<name>juicefs.jfs1.meta</name>
<value>redis://jfs1.host:port/1</value>
</property>
<property>
<name>juicefs.jfs2.meta</name>
<value>redis://jfs2.host:port/1</value>
</property>
配置示例
以下是一个常用的配置示例,请替换 juicefs.meta 配置中的 {HOST}、{PORT} 和 {DB} 变量为实际的值。
<property>
<name>fs.jfs.impl</name>
<value>io.juicefs.JuiceFileSystem</value>
</property>
<property>
<name>fs.AbstractFileSystem.jfs.impl</name>
<value>io.juicefs.JuiceFS</value>
</property>
<property>
<name>juicefs.meta</name>
<value>redis://{HOST}:{PORT}/{DB}</value>
</property>
<property>
<name>juicefs.cache-dir</name>
<value>/data*/jfs</value>
</property>
<property>
<name>juicefs.cache-size</name>
<value>1024</value>
</property>
<property>
<name>juicefs.access-log</name>
<value>/tmp/juicefs.access.log</value>
</property>
Hadoop 环境配置
请参照前述各项配置表,将配置参数加入到 Hadoop 配置文件 core-site.xml 中。
CDH6
如果使用的是 CDH 6 版本,除了修改 core-site 外,还需要通过 YARN 服务界面修改 mapreduce.application.classpath,增加:
$HADOOP_COMMON_HOME/lib/juicefs-hadoop.jar
HDP
除了修改 core-site 外,还需要通过 MapReduce2 服务界面修改配置 mapreduce.application.classpath,在末尾增加(变量无需替换):
/usr/hdp/${hdp.version}/hadoop/lib/juicefs-hadoop.jar
Flink
将配置参数加入 conf/flink-conf.yaml。如果��只是在 Flink 中使用 JuiceFS, 可以不在 Hadoop 环境配置 JuiceFS,只需要配置 Flink 客户端即可。
在阿里云实时平台 Flink SQL 使用 JuiceFS
-
创建 Maven 项目,根据 Flink 不同版本引入如下依赖
<dependencies>
<dependency>
<groupId>io.juicefs</groupId>
<artifactId>juicefs-hadoop</artifactId>
<version>{JUICEFS_HADOOP_VERSION}</version>
</dependency>
<!-- for flink-1.13 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime-blink_2.12</artifactId>
<version>1.13.5</version>
<scope>provided</scope>
</dependency>
<!-- for flink-1.15 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.15.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.15.2</version>
<scope>provided</scope>
</dependency>
</dependencies> -
创建一个 Java class
public class JuiceFileSystemTableFactory extends FileSystemTableFactory {
@Override
public String factoryIdentifier() {
return "juicefs";
}
} -
Flink table connector 是使用 Java’s Service Provider Interfaces (SPI) 加载自定义实现。 在 resources 按照如下结构创建文件
## for flink-1.13
src/main/resources
├── META-INF
│ └── services
│ └── org.apache.flink.table.factories.Factoryorg.apache.flink.table.factories.Factory文件内容:{YOUR_PACKAGE}.JuiceFileSystemTableFactory -
将填写有 JuiceFS 配置的 core-site.xml 放到 src/main/resources 内:
<configuration>
<property>
<name>fs.juicefs.impl</name>
<value>io.juicefs.JuiceFileSystem</value>
</property>
<property>
<name>juicefs.meta</name>
<value>redis://xxx.redis.rds.aliyuncs.com:6379/0</value>
</property>
...
</configuration>注意由于
jfs://scheme 被阿里其他文件系统占用,所以需要配置fs.juicefs.impl类为 JuiceFS 的实现类,并在后续路径使用juicefs://协议。 -
打包,确保 JAR 内包含 resources 目录下内容
-
通过阿里云实时计算平台控制台->应用->作业开发->connectors 界面上传 JAR 文件
-
测试,将如下 SQL 上线运行,可以在 JuiceFS 的
tmp/tbl目录下发现写入内容CREATE TEMPORARY TABLE datagen_source(
name VARCHAR
) WITH (
'connector' = 'datagen',
'number-of-rows' = '100'
);
CREATE TEMPORARY TABLE jfs_sink (name string)
with (
'connector' = 'juicefs', 'path' = 'juicefs://{VOL_NAME}/tmp/tbl', 'format' = 'csv'
);
INSERT INTO jfs_sink
SELECT
name
from datagen_source;
Hudi
Hudi 自 v0.10.0 版本开始支持 JuiceFS,请确保使用正确的版本。
请参考「Hudi 官方文档」了解如何配置 JuiceFS。
Kafka Connect
可以使用 Kafka Connect 和 HDFS Sink Connector(HDFS 2、HDFS 3)将数据落盘存储到 JuiceFS。
首先需要将 JuiceFS 的 SDK 添加到 Kafka Connect 的 classpath 内,如 /usr/share/java/confluentinc-kafka-connect-hdfs/lib。
在新建 Connect Sink 任务时,做如下配置:
- 指定
hadoop.conf.dir为包含core-site.xml配置文件的目录,若没有运行在 Hadoop 环境,可创建一个单独目录,如/usr/local/juicefs/hadoop,然后将与 JuiceFS 相关的配置添加到core-site.xml。 - 指定
store.url为以jfs://开头的路径
举例:
# 省略其他配置项...
hadoop.conf.dir=/path/to/hadoop-conf
store.url=jfs://path/to/store
HBase
JuiceFS 适合存储 HBase 的 HFile,但不适合用来保存它的事务日志(WAL),因为将日志持久化到对象存储的时间会远高于持久化到 HDFS 的 DataNode 的内存中。
建议部署一个小的 HDFS 集群来存放 WAL,HFile 文件则存储在 JuiceFS 上。
新建 HBase 集群
修改 hbase-site.xml 配置:
<property>
<name>hbase.rootdir</name>
<value>jfs://{vol_name}/hbase</value>
</property>
<property>
<name>hbase.wal.dir</name>
<value>hdfs://{ns}/hbase-wal</value>
</property>
修改原有 HBase 集群
除了修改上述配置项外,由于 HBase 集群已经在 ZooKeeper 里存储了部分数据,为了避免冲突,有以下两种方式解决:
-
删除原集群
通过 ZooKeeper 客户端删除
zookeeper.znode.parent配置的 znode(默认/hbase)。注意此操作将会删除原有 HBase 上面的所有数据
-
使用新的 znode
保留原 HBase 集群的 znode,以便后续可以恢复。然后为
zookeeper.znode.parent配置一个新的值:hbase-site.xml<property>
<name>zookeeper.znode.parent</name>
<value>/hbase-jfs</value>
</property>
重启服务
当需要使用以下组件访问 JuiceFS 数据时,需要重启相关服务。
在重启之前需要保证 JuiceFS 配置已经写入配置文件,通常可以查看机器上各组件配置的 core-site.xml 里面是否有 JuiceFS 相关配置。
| 组件名 | 服务名 |
|---|---|
| Hive | HiveServer Metastore |
| Spark | ThriftServer |
| Presto | Coordinator Worker |
| Impala | Catalog Server Daemon |
| HBase | Master RegionServer |
HDFS、Hue、ZooKeeper 等服务无需重启。
若访问 JuiceFS 出现 Class io.juicefs.JuiceFileSystem not found 或 No FilesSystem for scheme: jfs 错误,请参考 FAQ。
回收站
JuiceFS Hadoop Java SDK 同样也有和 HDFS 一样的回收站功能,需要通过设置 fs.trash.interval 和 fs.trash.checkpoint.interval 开启,请参考 HDFS 文档了解更多信息。
环境验证
JuiceFS Java 客户端部署完成以后,可以采用以下方式验证部署是否成功。
Hadoop CLI
hadoop fs -ls jfs://{JFS_NAME}/
这里的 JFS_NAME 是创建 JuiceFS 文件系统时指定的名称。
Hive
CREATE TABLE IF NOT EXISTS person
(
name STRING,
age INT
) LOCATION 'jfs://{JFS_NAME}/tmp/person';
Java/Scala 项目
-
新增 Maven 或 Gradle 依赖:
- Maven
- Gradle
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>{HADOOP_VERSION}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>io.juicefs</groupId>
<artifactId>juicefs-hadoop</artifactId>
<version>{JUICEFS_HADOOP_VERSION}</version>
<scope>provided</scope>
</dependency>dependencies {
implementation 'org.apache.hadoop:hadoop-common:${hadoopVersion}'
implementation 'io.juicefs:juicefs-hadoop:${juicefsHadoopVersion}'
} -
使用以下示例代码验证:
package demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class JuiceFSDemo {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.jfs.impl", "io.juicefs.JuiceFileSystem");
conf.set("juicefs.meta", "redis://127.0.0.1:6379/0"); // JuiceFS 元数据引擎地址
Path p = new Path("jfs://{JFS_NAME}/"); // 请替换 {JFS_NAME} 为正确的值
FileSystem jfs = p.getFileSystem(conf);
FileStatus[] fileStatuses = jfs.listStatus(p);
// 遍历 JuiceFS 文件系统并打印文件路径
for (FileStatus status : fileStatuses) {
System.out.println(status.getPath());
}
}
}
监控指标收集
请查看「监控」文档了解如何收集及展示 JuiceFS 监控指标
从 HDFS 迁移数据到 JuiceFS
从 HDFS 迁移数据到 JuiceFS,一般是使用 DistCp 来拷贝数据,它支持数据校验 (Checksum) 来保证数据的正确性。
DistCp 是使用 HDFS 的 getFileChecksum() 接口来获得文件的校验码,然后对比拷贝后的文件的校验码来确保数据是一样的。
Hadoop 默认使用的 Checksum 算法是 MD5-MD5-CRC32, 严重依赖 HDFS 的实现细节。它是根据文件目前的分块形式,使用 MD5-CRC32 算法汇总每一个数据块的 Checksum(把每一个 64K 的 block 的 CRC32 校验码汇总,再算一个 MD5),然后再用 MD5 计算校验码。如果 HDFS 集群的分块大小不同,就没法用这个算法进行比较。
为了兼容 HDFS,JuiceFS 也实现了该 MD5-MD5-CRC32 算法,它会将文件的数据读一遍,用同样的算法计算得到一个 checksum,用于比较。
因为 JuiceFS 是基于对象存储实现的,后者已经通过多种 Checksum 机制保证了数据完整性,JuiceFS 默认没有启用上面的 Checksum 算法,需要通过 juicefs.file.checksum 配置来启用。
因为该算法依赖于相同的分块大小,需要通过 juicefs.block.size 配置将分块大小设置为跟 HDFS 一样(默认值是 dfs.blocksize,它的默认值是 128MB)。
另外,HDFS 里支持给每一个文件设置不同的分块大小,而 JuiceFS 不支持,如果启用 Checksum 校验的话会导致拷贝部分文件失败(因为分块大小不同),JuiceFS Hadoop Java SDK 对 DistCp 打了一个热补丁(需要 tools.jar)来跳过这些分块不同的文件(不做比较,而不是抛异常)。
基准测试
以下提供了一系列方法,使用 JuiceFS 客户端内置的压测工具,对已经成功部署了客户端环境进行性能测试。
1. 本地测试
元数据性能
-
create
hadoop jar juicefs-hadoop.jar nnbench create -files 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench -local此命令会 create 10000 个空文件
-
open
hadoop jar juicefs-hadoop.jar nnbench open -files 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench -local此命令会 open 10000 个文件,并不读取数据
-
rename
hadoop jar juicefs-hadoop.jar nnbench rename -files 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench -local -
delete
hadoop jar juicefs-hadoop.jar nnbench delete -files 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench -local -
参考值
操作 TPS 时延(ms) create 644 1.55 open 3467 0.29 rename 483 2.07 delete 506 1.97
I/O 性能
-
顺序写
hadoop jar juicefs-hadoop.jar dfsio -write -size 20000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/DFSIO -local -
顺序读
hadoop jar juicefs-hadoop.jar dfsio -read -size 20000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/DFSIO -local如果多次运行此命令,可能会出现数据被缓存到了系统缓存��而导致读取速度非常快,只需清除 JuiceFS 的本地磁盘缓存即可
-
参考值
操作 吞吐(MB/s) write 647 read 111
如果机器的网络带宽比较低,则一般能达到网络带宽瓶颈
2. 分布式测试
以下命令会启动 MapReduce 分布式任务程序对元数据和 IO 性能进行测试,测试时需要保证集群有足够的资源能够同时启动所需的 map 任务。
本项测试使用的计算资源:
- 服务器:3 台 4 核 32 GB 内存的云服务器,突发带宽 5Gbit/s。
- 数据库:阿里云 Redis 5.0 社区 4G 主从版
元数据性能
-
create
hadoop jar juicefs-hadoop.jar nnbench create -maps 10 -threads 10 -files 1000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench此命令会启动 10 个 map task,每个 task 有 10 个线程,每个线程会创建 1000 个空文件,总共 100000 个空文件
-
open
hadoop jar juicefs-hadoop.jar nnbench open -maps 10 -threads 10 -files 1000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench此命令会启动 10 个 map task,每个 task 有 10 个线程,每个线程会 open 1000 个文件,总共 open 100000 个文件
-
rename
hadoop jar juicefs-hadoop.jar nnbench rename -maps 10 -threads 10 -files 1000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench此命令会启动 10 个 map task,每个 task 有 10 个线程,每个线程会 rename 1000 个文件,总共 rename 100000 个文件
-
delete
hadoop jar juicefs-hadoop.jar nnbench delete -maps 10 -threads 10 -files 1000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/NNBench此命令会启动 10 个 map task,每个 task 有 10 个线程,每个线程会 delete 1000 个文件,总共 delete 100000 个文件
-
参考值
-
10 并发
操作 IOPS 时延(ms) create 4178 2.2 open 9407 0.8 rename 3197 2.9 delete 3060 3.0 -
100 并发
操作 IOPS 时延(ms) create 11773 7.9 open 34083 2.4 rename 8995 10.8 delete 7191 13.6
-
I/O 性能
-
连续写
hadoop jar juicefs-hadoop.jar dfsio -write -maps 10 -size 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/DFSIO此命令会启动 10 个 map task,每个 task 写入 10000MB 的数据
-
连续读
hadoop jar juicefs-hadoop.jar dfsio -read -maps 10 -size 10000 -baseDir jfs://{JFS_NAME}/tmp/benchmarks/DFSIO此命令会启动 10 个 map task,每个 task 读取 10000MB 的数据
-
参考值
操作 平均吞吐(MB/s) 总吞吐(MB/s) write 198 1835 read 124 1234
3. TPC-DS
测试数据集 100GB 规模,测试 Parquet 和 ORC 两种文件格式。
本次测试仅测试前 10 个查询。
使用 Spark Thrift JDBC/ODBC Server 开启 Spark 常驻进程,然后通过 Beeline 连接提交任务。
测试硬件
| 节点类型 | 机器型号 | CPU | 内存 | 磁盘 | 数量 |
|---|---|---|---|---|---|
| Master | 阿里云 ecs.r6.xlarge | 4 | 32GiB | 系统盘:100GiB | 1 |
| Core | 阿里云 ecs.r6.xlarge | 4 | 32GiB | 系统盘:100GiB 数据盘:500GiB 高效云盘 x 2 | 3 |
软件配置
Spark Thrift JDBC/ODBC Server
${SPARK_HOME}/sbin/start-thriftserver.sh \
--master yarn \
--driver-memory 8g \
--executor-memory 10g \
--executor-cores 3 \
--num-executors 3 \
--conf spark.locality.wait=100 \
--conf spark.sql.crossJoin.enabled=true \
--hiveconf hive.server2.thrift.port=10001
JuiceFS 缓存配置
Core 节点的 2 块数据盘挂载在 /data01 和 /data02 目录下,core-site.xml 配置如下:
<property>
<name>juicefs.cache-size</name>
<value>200000</value>
</property>
<property>
<name>juicefs.cache-dir</name>
<value>/data*/jfscache</value>
</property>
<property>
<name>juicefs.cache-full-block</name>
<value>false</value>
</property>
<property>
<name>juicefs.discover-nodes-url</name>
<value>yarn</value>
</property>
<property>
<name>juicefs.attr-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.entry-cache</name>
<value>3</value>
</property>
<property>
<name>juicefs.dir-entry-cache</name>
<value>3</value>
</property>
测试
任务提交的命令如下:
${SPARK_HOME}/bin/beeline -u jdbc:hive2://localhost:10001/${DATABASE} \
-n hadoop \
-f query{i}.sql
结果
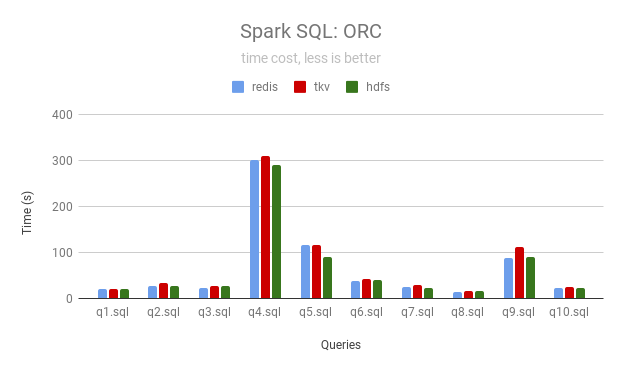
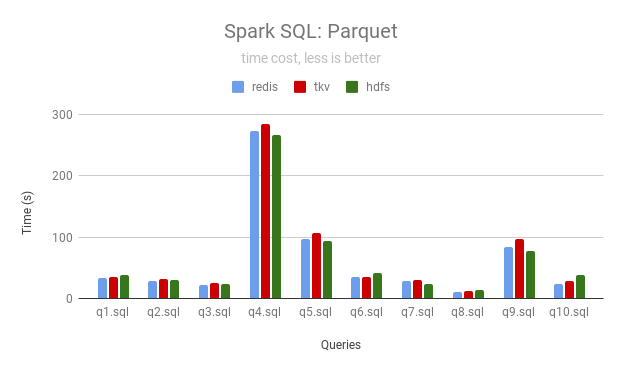
JuiceFS 可以使用本地磁盘作为缓存加速数据访问,以下数据是分别使用 Redis 和 TiKV 作为 JuiceFS 的元数据引擎跑 4 次后的结果(单位秒)。
ORC
| Queries | JuiceFS (Redis) | JuiceFS (TiKV) | HDFS |
|---|---|---|---|
| q1 | 20 | 20 | 20 |
| q2 | 28 | 33 | 26 |
| q3 | 24 | 27 | 28 |
| q4 | 300 | 309 | 290 |
| q5 | 116 | 117 | 91 |
| q6 | 37 | 42 | 41 |
| q7 | 24 | 28 | 23 |
| q8 | 13 | 15 | 16 |
| q9 | 87 | 112 | 89 |
| q10 | 23 | 24 | 22 |
Parquet
| Queries | JuiceFS (Redis) | JuiceFS (TiKV) | HDFS |
|---|---|---|---|
| q1 | 33 | 35 | 39 |
| q2 | 28 | 32 | 31 |
| q3 | 23 | 25 | 24 |
| q4 | 273 | 284 | 266 |
| q5 | 96 | 107 | 94 |
| q6 | 36 | 35 | 42 |
| q7 | 28 | 30 | 24 |
| q8 | 11 | 12 | 14 |
| q9 | 85 | 97 | 77 |
| q10 | 24 | 28 | 38 |
使用 Apache Ranger 进行权限管控( v1.3支持 )
JuiceFS 当前支持对接 Apache Ranger 的 HDFS 模块进行路径的权限管控。仅 Hadoop Java SDK 支持该功能。
1. 相关配置
Apache Ranger 的配置统一放在 META 数据库内。可以通过以下方法开启 Ranger 的权限管控:
# format 的时候指定 ranger 配置
juicefs format META-URL NAME --ranger-rest-url http://localhost:6080 --ranger-service jfs
# 已有的文件系统增加 ranger 配置
juicefs config META-URL --ranger-rest-url http://localhost:6080 --ranger-service jfs
# 关闭 ranger
juicefs config META-URL --ranger-rest-url "" --ranger-service jfs ""
2. 环境及依赖
考虑到使用的方便性,JuiceFS 将 Ranger 所有依赖的包均打包到 JuiceFS 的 SDK 中。如果遇到 Apache Ranger 的版本冲突问题,可能需要修改版本重新编译。
3. 配置 Kerberos
开启 Kerberos 会导致业务使用的 JuiceFS 客户端无法下载 Ranger 安全规则,你需要在 Ranger Admin Web UI - HDFS Service 配置 policy.download.auth.users 和 tag.download.auth.users 来为指定的用户赋予下载安全规则的权限,多个用户用逗号','隔开。
配置完成以后,你还需要使用该用户来更新 JuiceFS 中保存的规则。
更新安全规则文件的命令如下(建议配置成定时任务自动更新),注意将 {PRINCIPAL} 替换为 policy.download.auth.users 配置的用户:
hadoop jar juicefs-hadoop-{version}.jar ranger \
--fs jfs://{VOL_NAME}/ \
--keytab /path/to/keytab \
--principal {PRINCIPAL}
4. 使用提示
4.1 Ranger版本
当前代码测试基于Ranger2.3和Ranger2.4版本,因除HDFS模块鉴权外并未使用其他特性,理论上其他版本均适用。
4.2 Ranger Audit
当前仅支持鉴权功能,Ranger Audit功能已关闭。
4.3 Ranger其他参数
为提升使用效率,当前仅开放连接 Ranger 最核心的参数。
4.4 安全性问题
因项目代码完全开源,无法避免用户通过替换ranger-rest-url等参数的方式扰乱安全管控。如需更严格的管控,建议自主编译代码,通过将相关安全参数进行加密处理等方式解决。
Kerberos 支持( v1.4支持 )
JuiceFS 支持使用 Kerberos 进行用户认证,不过仅限于 Hadoop Java SDK。
1. 相关配置
Kerberos 的配置统一放在 META 数据库内,可以通过 JuiceFS 命令行进行管理。
# format 的时候开启 Kerberos
juicefs format META-URL --kerberos-config-file kerb.cfg
# 或者对已有文件系统开启 Kerberos
./juicefs config META-URL --kerberos-config-file kerb.cfg
# 关闭 Kerberos
./juicefs config META-URL --kerberos-config-file ""
kerbero 配置文件
# kerberos keytab, encode with BASE64
# base64 -w 0 meta.keytab
{VOL_NAME}.keytab={BASE64 KEYTAB}
# delegation token
{VOL_NAME}.token.life=604800
{VOL_NAME}.token.renew=86400
# superuser and supergroup
{VOL_NAME}.superuser=hadoop
{VOL_NAME}.supergroup=supergroup
# Mapping from Kerberos principals to OS user accounts
# https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SecureMode.html#Mapping_from_Kerberos_principals_to_OS_user_accounts
{VOL_NAME}.mechanism=hadoop
{VOL_NAME}.rule=DEFAULT
# proxy user settings
# https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SecureMode.html#Proxy_user
# users: user1,user2 or *
{VOL_NAME}.proxy.client.users=foo
# groups: group1,group2 or *
{VOL_NAME}.proxy.client.groups=foogrp
# hosts: host1,host2 or 192.168.1.1,192.168.1.2 or 192.168.1.1/32 or *
{VOL_NAME}.proxy.client.hosts=*
core-site 配置
<property>
<name>juicefs.server-principal</name>
<value>{YOUR_SPN}</value>
</property>
FAQ
1. 出现 Class io.juicefs.JuiceFileSystem not found 异常
出现这个异常的原因是 juicefs-hadoop.jar 没有被加载,可以用 lsof -p {pid} | grep juicefs 查看 JAR 文件是否被加载。需要检查 JAR 文件是否被正确地放置在各个组件的 classpath 里面,并且保证 JAR 文件有可读权限。
另外,在某些发行版 Hadoop 环境中,需要修改 mapred-site.xml 中的 mapreduce.application.classpath 参数,添加 juicefs-hadoop.jar 的路径。
2. 出现 No FilesSystem for scheme: jfs 异常
出现这个异常的原因是 core-site.xml 配置文件中的 JuiceFS 配置没有被读取到,需要检查组件配置的 core-site.xml 中是否有 JuiceFS 相关配置。
3. JuiceFS 与 HDFS 的用户权限管理有何相同和不同之处?
JuiceFS 也是使用「用户/用户组」的方式管理文件权限,默认使用的是本地的用户和用户组。为了保证分布式计算时不同节点的权限统一,可以通过 juicefs.users 和 juicefs.groups 配置全局的「用户/UID」和「用户组/GID」映射。
4. 数据删除后都是直接存储在 JuiceFS 的 .trash 目录,虽然文件都在但是很难像 HDFS 那样简单通过 mv 命令就能恢复数据,是否有某种办法可以达到类似 HDFS 回收站的效果?
在 Hadoop 应用场景下,仍然保留了类似于 HDFS 回收站的功能。需要通过 fs.trash.interval 以及 fs.trash.checkpoint.interval 配置来显式开启,请参考文档了解更多信息。
5. 设置 juicefs.discover-nodes-url 这个参数有什么好处?
在 HDFS 里面,每个数据块会有 BlockLocation 信息,计算引擎会利用此信息尽量将计算任务调度到数据所存储的节点。JuiceFS 会通过一致性哈希算法为每个数据块计算出对应的 BlockLocation,这样第二次读取相同的数据时,计算引擎有可能将计算任务调度到相同的机器上,就可以利用第一次计算时缓存在本地磁盘的数据来加速数据访问��。
此算法需要事先知道所有的计算节点信息,juicefs.discover-nodes-url 参数就是用来获得这些计算节点信息的。
6. 对于采用 Kerberos 认证的 CDH 集群,社区版 JuiceFS 目前能否支持呢?
不支持。JuiceFS 不会校验 Kerberos 用户的合法性,但是可以使用通过 Kerberos 认证的用户名。


