















Note: This post was published on DZone.
Unisound is an AI unicorn startup, specializing in speech recognition and artificial intelligence (AI) services. Our high-performance computing (HPC) platform, Atlas, supports the company with powerful computing capabilities in various AI domains. Its deep learning computing power exceeds 57 PFLOPS (570 million times per second).
However, finding a suitable storage system was challenging for us. After trying CephFS, Lustre, and Alluxio+Fluid, we found that JuiceFS, an open-source cloud-native distributed file system, outperformed Lustre in system performance and was easy to maintain.
In our test, JuiceFS achieved read performance improvements of 36% and 25% in text recognition and noise suppression, respectively. Therefore, we adopted it in our production environment and applied its multi-level cache in text recognition, speech noise suppression, and speech recognition.
In this post, I’ll share our storage challenge, the solution we chose, benefits we've experienced, lessons we learned from comparing Lustre and JuiceFS, and our future plans. I hope this post can help you choose a suitable storage system based on your application needs and storage scale.
Our storage challenge
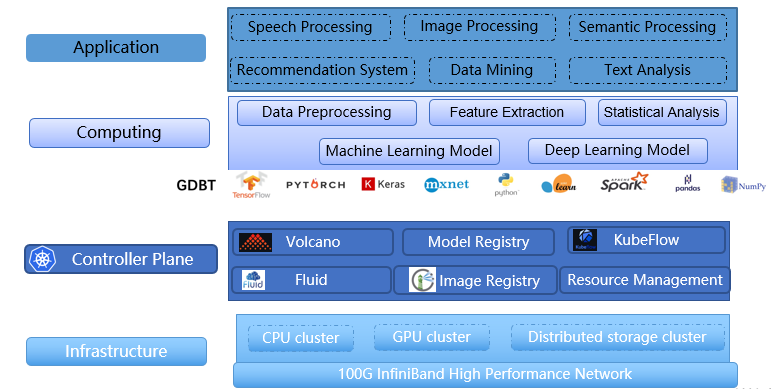
As an HPC platform, Atlas requires powerful computing capabilities and an efficient storage system. Our storage system must meet the following requirements:
- Support for multiple types of structured and unstructured data storage
- Compatibility with POSIX
- High performance in scenarios with massive numbers of small files
Previously, we tried CephFS, Lustre, and Alluxio+Fluid, but they were not ideal:
- When there were tens of millions of small files, CephFS had serious performance problems. When users operated files, the system would be unresponsive or even freeze, especially in high I/O scenarios.
- Lustre had performance bottlenecks under high concurrent requests. It could not meet the needs of scenarios with high bandwidth and IOPS requirements.
Troubleshooting was also difficult, because the Lustre code ran in the Linux kernel. Most of these operations required restarting the operating system.
Lustre did not support file system-level redundancy (FLR). It could only resist hard drive failure through hardware RAID.
- Alluxio+Fluid reduced the total storage system bandwidth despite speeding up our AI model training with its distributed cache for I/O acceleration.
Therefore, we looked for a storage system that met the following requirements:
- Easy operations and maintenance. It should be easy to use, scale out and troubleshoot.
- Reliable data. Data is a valuable asset for AI companies, and data that algorithm engineers use must be stable and safe.
- Multi-level client caching. To build a cost-effective large-scale data storage system (of petabyte-scale or above), we store the majority of the data on HDDs. To automatically distinguish between hot and cold data and fully utilize the near-terabyte memory and independent SSDs of our GPU servers, we require multi-level automatic caching capabilities within the client to handle intensive I/O read and write scenarios.
- An active community, which leads to fast responses in terms of feature updates and bug fixes.
A distributed file system as the solution
JuiceFS is an open-source, high-performance, distributed file system designed for the cloud, compatible with POSIX, HDFS, and S3 API. Our proof of concept (PoC) test demonstrated that JuiceFS outperformed Lustre in terms of performance. Additionally, it is easy to operate and maintain, making it a great fit for our application. Therefore, we deployed JuiceFS in our production environment.
The JuiceFS architecture
JuiceFS consists of:
- A metadata engine
- An object storage
- A JuiceFS client
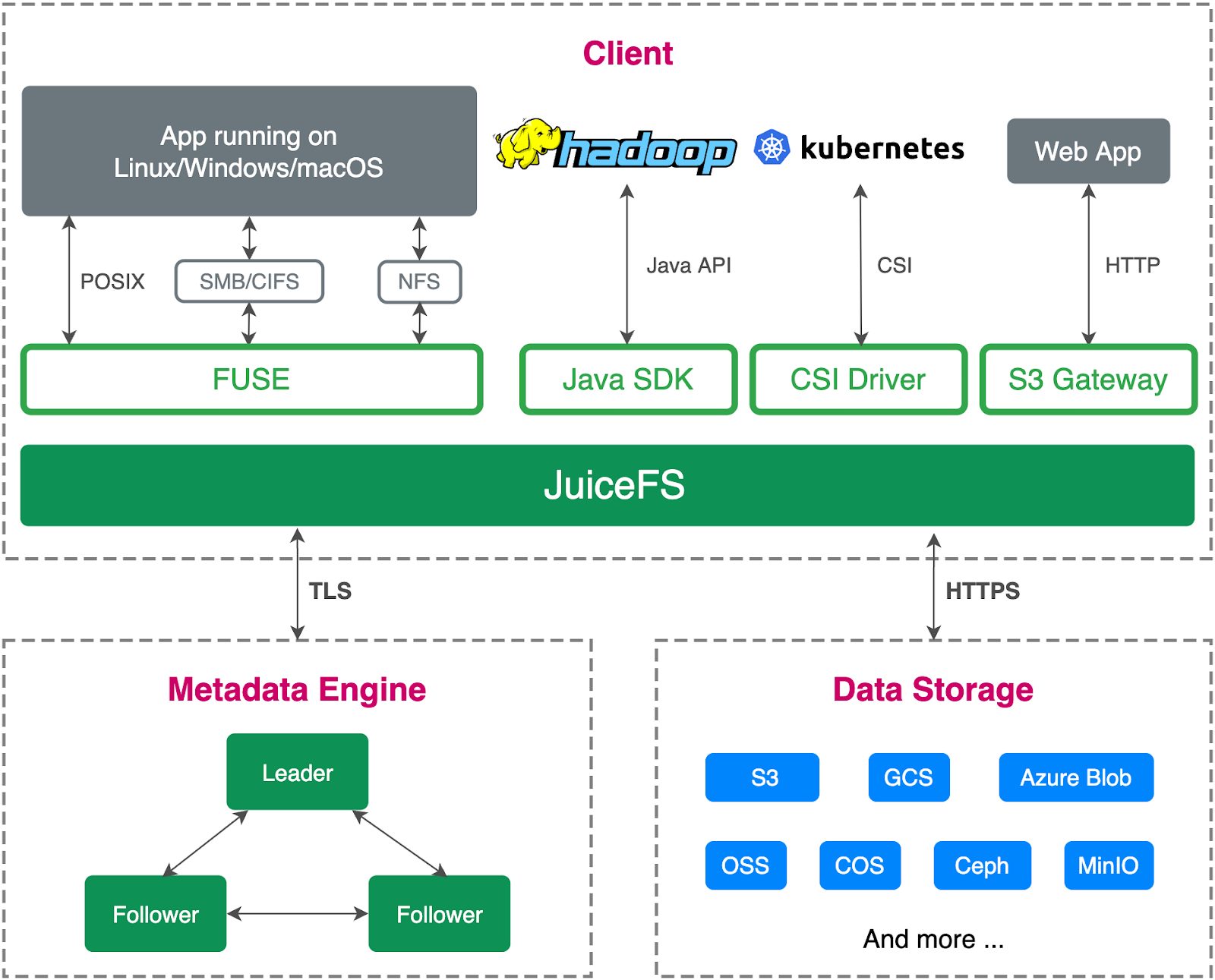
JuiceFS separates data and metadata storage. Files are split into chunks and stored in object storage like Amazon S3, and the corresponding metadata can be stored in various databases such as Redis, MySQL, TiKV, and SQLite, based on the scenarios and requirements.
JuiceFS advantages
- Many proven solutions for metadata engine and object storage.
- Fully managed services available out-of-the-box on public cloud.
- Automatic metadata backup, recycle bin, and other features guarantee data reliability to avoid data loss.
- Local caching automatically caches frequently accessed data in memory and on disks, and also caches file metadata.
JuiceFS vs. Lustre in our PoC test
We conducted a PoC to test its product features, operations and maintenance, and its feasibility to interface with upstream scheduling and application frameworks.
The PoC environment was a single-node Redis plus 3-node Ceph object storage cluster. We connected the JuiceFS client to Redis and Ceph easily.
We found that JuiceFS was suitable for our application:
- It was fully compatible with POSIX, so our upper layer application could seamlessly switch to it. The application was transparent to users.
- JuiceFS supported CSI Driver, which fit in with our technology stack.
To test JuiceFS performance, we trained the text recognition model in the test environment with:
- The server version of the Chinese recognition model
- The ResNet-18 backbone
- 98 GB of data stored in LMDB format
We conducted the following 3 tests on 6 NVIDIA Tesla V100 and got the results as shown in the figure below:
- Reads in Lustre (“Lustre” in the figure below)
- Reads in JuiceFS with 200 GB memory cache (“jfs-mem” in the figure below)
- Reads in JuiceFS with 960 GB SSD cache (“jfs-ssd” in the figure below)
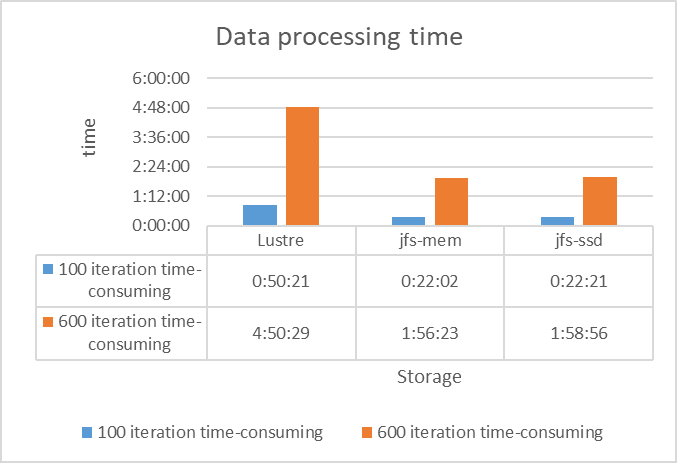
The tests showed that JuiceFS' data read performance was over twice that of Lustre due to its client's multi-level caching capability.
How we benefit from JuiceFS
We apply the JuiceFS client’s multi-level cache in text recognition, speech noise suppression, and speech recognition scenarios. AI model training usually involves frequent reads and infrequent writes. Therefore, we fully leverage the JuiceFS client cache to accelerate I/O reads.
Benefit #1: accelerating AI model training
In the noise suppression scenario
The data used in the noise reduction test were unmerged raw files. Each data file was a small audio file of less than 100 KB in WAVE format. We focused on testing the data loading I/O performance of JuiceFS client nodes, which have a memory cache of 512 GB. We conducted the tests using a batch size of 40, with a dataset of 500 hours.
The following figure shows the results:
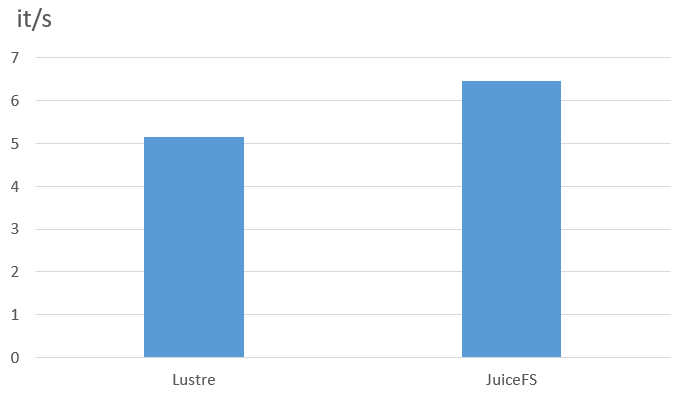
According to the test results, JuiceFS demonstrated a 25% performance improvement in data reading efficiency for small WAV files, achieving a speed of 6.45 it/s compared to Lustre's 5.15 it/s. This effective acceleration with JuiceFS contributed to our end-to-end model training and significantly reduced our model output time.
In the text recognition scenario
The test environment for the text recognition scenario was as follows:
| Model | CRNN with MobileNetV2 backbone |
|---|---|
| Deep learning framework | PyTorch |
| Data size | 50G LMDB data generated from 3*32*320 images |
| Data type | LMDB |
| GPU server | 6 * NVIDIA Tesla V100 / 512G MEM / 56 CPU Cores |
| Cache | 200 GB |
| Batch size | 6*400 |
This figure shows the test results:
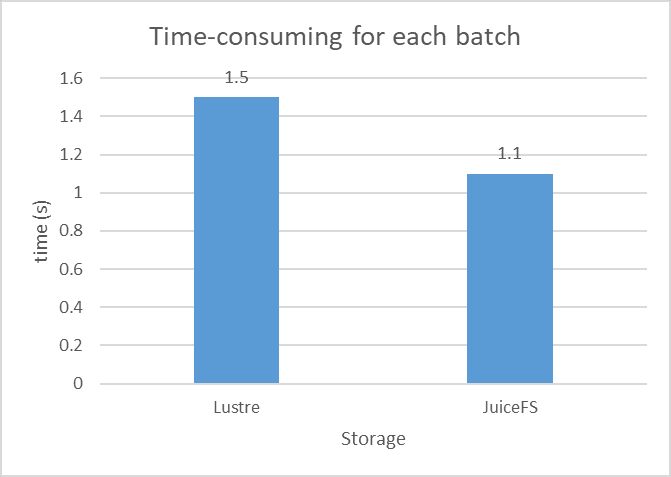
According to the test results, JuiceFS read each batch faster than Lustre, taking 1.1 s and 1.5 s respectively, a 36% performance improvement. Moreover, JuiceFS reduced the model's convergence time from 96 hours on Lustre to 86 hours on JuiceFS, a 10-hour decrease in CRNN model output time.
Benefit #2: accelerating AI model development
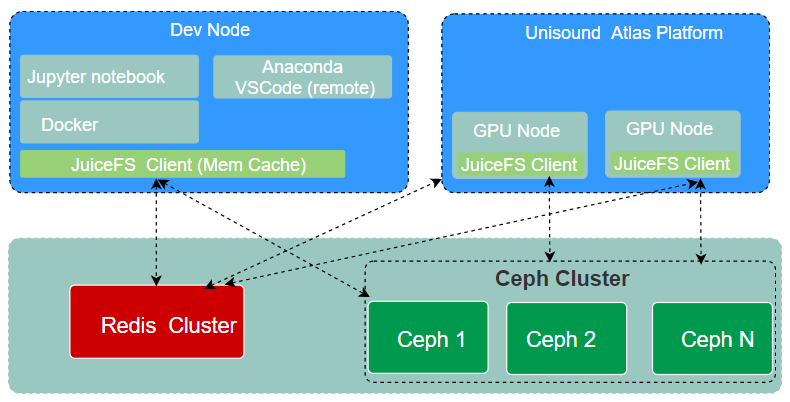
The debugging environment
Before submitting an AI model training task to a HPC cluster, an algorithm engineer must extensively debug the model. To aid this process, we provide a debugging environment for users. The Dev Node shares the same storage as the formal Atlas training cluster. It has a JuiceFS client mounted, allowing seamless migration of changes made on the development machine to the Atlas training cluster.
Users can choose their development environment, either by using Anaconda on the host for remote debugging or by running the development environment in a container.
Debugging platforms
PyTorch and TensorFlow are the most commonly used platforms for debugging. But frequent imports of Python packages such as numpy and torch, which are composed of a large number of small files, can cause significant delays. Under the old storage system, this process could take several seconds or even tens of seconds.
Challenges
Algorithm engineers reported that the model debugging efficiency was low. To address these issues, the Dev Node needed high throughput and the ability to quickly handle a large number of small files, including:
- Installation package imports
- Code compilation
- Log reading and writing
- Sample downloading
JuiceFS as the solution
To solve these problems, we introduced JuiceFS, which offers the following benefits:
- Metadata caching: file attributes are automatically cached in the client's memory when the JuiceFS client opens a file using the `open()` operation. Subsequent `getattr()` and `open()` operations immediately return results from the memory cache as long as the cache is not invalidated. The chunk and slice information of the file is also cached in the client memory when the `read()` operation is performed.
- Data caching: we use memory as the cache medium, which caches all Python packages debugged by the user in memory after the first import. This enables the files to be read directly from the memory cache during the second debugging.
JuiceFS helped us achieve an overall speedup of 2-4 times. This significantly improved debugging efficiency and user experience.
Lessons learned: Lustre vs. JuiceFS
We made a comparison between Lustre and JuiceFS and summarized their advantages and disadvantages for your reference. You can make your own choice based on your business needs, operation and maintenance capability, and storage scale.
Lustre
Advantages:
- It has years of experience in production environments as a storage system in the area of HPC, powering many of the world's largest supercomputing systems.
- It is compliant with the POSIX standard and supports various high-performance, low-latency networks.
- It allows RDMA access.
Disadvantages:
- It is not well adapted to cloud-native scenarios and can only be integrated with HostPath Volume.
- It runs on top of the Linux kernel, which has high demands on operations and maintenance staff.
JuiceFS
Advantages:
- As a distributed storage system in the cloud-native area, JuiceFS provides CSI Driver and Fluid to enable better integration with Kubernetes.
- It provides users with more flexible options. Users can choose either on the cloud or on-premises deployment. It’s easy to maintain and scale storage capacity.
- It is fully compatible with POSIX, allowing seamless migration of deep learning applications.
Disadvantage:
- It may have a high latency in random writes, due to its object storage characteristics. To solve this issue in read-only scenarios, we use the client's multi-level cache to accelerate reads.
What’s next
Our future plans for JuiceFS at the Atlas platform:
- Metadata engine upgrade: TiKV is suitable for scenarios with more than 100 million files (up to 10 billion files) and high requirements for performance and data security. We have completed our tests on TiKV and will migrate the metadata engine to TiKV.
- Directory (project) based quotas: The JuiceFS community edition does not support directory based quotas. Our departments are in different directories of JuiceFS, and we need to make restrictions on directory quotas. The JuiceFS community edition plans to implement directory based quotas, which will be released in the version later than v1.0.0.
If you have any questions or would like to learn more, feel free to join our discussions on GitHub and community on Slack.