















vivo is a multinational technology company that designs and develops smartphones, smartphone accessories, software and online services. We serve 400 million+ users in 60+ countries and regions.
As a key module of vivo AI computing platform, VTraining is a general training platform built on Kubernetes clusters. It supports large-scale distributed training across multiple frameworks and is equipped with petabyte-scale distributed storage. Currently, VTraining serves 700+ users, covering mission-critical applications such as recommendations, speech, vision, NLP, and imaging. The platform boasts a GPU compute power of 300 PFLOPS, a cluster with 3,000+ nodes, and 5+ PB of storage data.
In this post, we'll deep dive into how VTraining overcame storage challenges by transitioning from GlusterFS to the XuanYuan file storage system, developed with JuiceFS, a cloud-native distributed file system. We'll explore the significant performance improvement brought by high-performance distributed metadata services, flexible caching strategies, and effective capacity load balancing.
Early pain points of VTraining storage system
In the early stages of VTraining's development, the storage setup encountered several challenges. Our underlying storage system migrated from GlusterFS to XuanYuan. Here are some key pain points we encountered with GlusterFS.
Performance limitations for training needs
GlusterFS was designed primarily for large file storage scenarios. The training scenarios in VTraining were quite complex, and performance storage bottlenecks may affect training tasks in various situations. Common issues included:
-
Inefficient traversal of directories containing a massive number of files GlusterFS employs elastic hash instead of traditional centralized or distributed metadata services in distributed file systems. This access method allows for very fast lookup and positioning when the file name is known. However, performance significantly degrades when listing directories (
lsorls -l) without prior knowledge of the file names. VTraining required large numbers of files for many training tasks, such as images. This led to frequent scenarios with massive file directories. During data loading for training, directory traversal was necessary. This severely impacted training task efficiency. In extreme cases, it could even cause training tasks to freeze. -
Low access performance of small files The low performance of accessing small files has always been a recognized challenge in both industry and academia. Typically, optimizations for this issue focus on metadata management, caching mechanisms, and file consolidation. GlusterFS itself does not implement optimizations specifically for small files. Consequently, when dealing with a massive number of small files, GlusterFS is passive. However, scenarios involving massive small files are common in deep learning training. Without additional optimizations, training efficiency could be severely low.
-
Storage performance issues during large-scale training As the user base of VTraining grew and the number of tasks increased, the I/O pressure on remote distributed storage clusters increased. Concurrent access by multiple clients led to traffic competition. Without effective rate limiting strategies, GlusterFS clients may starve I/O resources. This resulted in prolonged inefficiencies for some training tasks. Simultaneously, direct access from a lot of clients to distributed storage servers burdened them heavily, causing high I/O latency. This slowed down client access and could also potentially overwhelm the storage cluster, making storage unavailable.
Typically, to address such issues, designs often use caching between clients and storage clusters to alleviate server pressure. GlusterFS clients’ cache rely on memory-based storage. This is inadequate for platforms handling petabytes of training data.
Capacity load balancing issues
While scaling GlusterFS was easy, its capacity load balancing lacked automation, intelligence, and parallel execution. After scaling, we needed to manually balance loads. It didn’t consider the current system load, which potentially affected normal application operations.
During capacity balancing, data was distributed using a hash algorithm. When nodes were added or removed, it caused widespread data migration. This severely impacted overall cluster performance. However, if we didn’t implement capacity load balancing, older nodes might get overloaded. This would result in local performance issues. To minimize the effects of data balancing after scaling, VTraining scaled the cluster. But it brought increased management costs.
Difficulties in troubleshooting and development
GlusterFS integrates the client, metadata, and data. There were few colleagues familiar with GlusterFS as a whole, and recruiting skilled individuals was challenging. This situation made troubleshooting difficult and posed barriers to custom development for specific functionalities.
VTraining's storage system requirements
The storage system requirements of VTraining focused on the following aspects:
- Shared storage: To avoid frequent data copying between nodes, we needed a shared storage space to collect and store data. Typically, the industry separates computing and storage and uses remote distributed storage for training data.
- High performance: Deep learning tasks require vast amounts of data to train models. Therefore, storage systems need high bandwidth to ensure data flows quickly enough to meet demands. This becomes particularly critical as GPU computing power increases, often exacerbating performance bottlenecks in storage systems.
- Ease of management: Simplified data management and easy maintenance of storage clusters, with convenient capacity scaling in or out.
About the XuanYuan file storage system
The XuanYuan file storage system is a high-performance file system designed for cloud-native environments, jointly developed by the storage teams of vivo's Internet infrastructure platform and the JuiceFS team. It features a separated storage architecture for data and metadata, enabling distributed file system design.
The figure below shows the architecture of the XuanYuan file storage system:
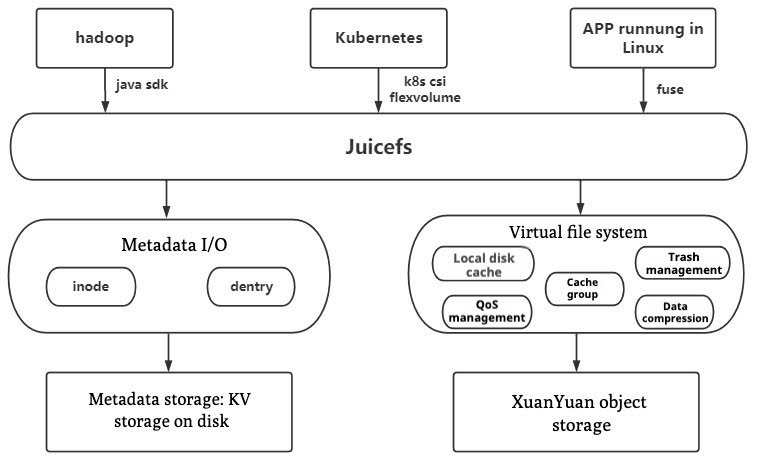
The XuanYuan file storage system’s architecture includes three main components:
-
The JuiceFS client The JuiceFS client offers rich APIs compatible with most mainstream application platforms. It seamlessly integrates with big data, machine learning, and AI platforms. This provides massive, scalable, cost-effective, high-performance storage. Its pluggable architecture for data storage and metadata engine allows integration with various object storage solutions. This caters to diverse user needs. In addition, JuiceFS offers flexible caching strategies to significantly enhance storage performance. For more details on JuiceFS, see JuiceFS documentation.
-
The metadata engine The metadata engine in JuiceFS is pluggable. It allows users to choose high-performance databases such as Redis or TiKV to accelerate metadata access. XuanYuan's metadata engine, developed by vivo, is a distributed disk key-value database known for its high performance, stability, and support for multiple data models. While not matching the speed of Redis, it significantly reduces cost pressures and is tailored for various AI-driven application scenarios.
-
The data storage engine The data storage engine uses vivo's self-developed XuanYuan object storage, providing solutions with massive storage capacity, security, low cost, high performance, and reliability. It includes SDKs in multiple languages for rapid integration into storage clusters and seamless connectivity with the JuiceFS client.
How XuanYuan file storage solved VTraining’s pain points
Object storage as persistent data layer
In the selection of storage systems, object storage is capable of handling tens of billions of files. However, traditional object storage solutions are not suitable for deep learning platforms, especially in scenarios involving massive small file training. This is because traditional object storage solutions lack native directory support and POSIX compliance, and they have weak metadata performance. The JuiceFS client can use any object storage as a persistent data layer. XuanYuan file storage ensures compatibility with POSIX, HDFS, and S3 protocols. This approach supports all machine learning and deep learning frameworks. As long as the metadata performance issues are addressed, using object storage as the data persistence layer for computing platforms is highly suitable for XuanYuan file storage.
High-performance distributed metadata service
Unlike GlusterFS' elastic hash algorithm, XuanYuan file storage employs a metadata and data separation architecture. It uses high-performance distributed metadata services to significantly enhance access efficiency. Moreover, to further boost metadata storage performance, we use high-speed nonvolatile memory express (NVMe) disks as storage media.
Proper cache configuration
The JuiceFS client offers diverse caching capabilities. Data accessed by clients can be cached on specified storage media. This strategic use of JuiceFS caching reduces remote network access overhead, speeds up data retrieval, greatly improves training efficiency, and significantly reduces API calls from clients to remote storage clusters. This alleviates I/O pressure on storage servers and reduces server loads for healthier storage clusters. Similarly, metadata is automatically cached in client memory to enhance metadata access performance.
Flexible rate limiting strategy
The JuiceFS client supports read and write speed limiting. This effectively resolves client I/O contention issues in multi-user access scenarios and reduces starvation.
Effective capacity load balancing mechanism
XuanYuan file storage distributes metadata and data through a unified central architecture. Compared to hash-based GlusterFS, it naturally excels in capacity load balancing. XuanYuan file storage's capacity load balancing considers automation, intelligence, and parallelism, minimizing impacts on current application operations to the maximum extent.
Our experience demonstrates after adopting the XuanYuan file storage system, VTraining has greatly improved or resolved its previous pain points.
XuanYuan file storage platform integration
VTraining is built on a Kubernetes cluster, and JuiceFS offers support through two plugins: Container Storage Interface (CSI) and FlexVolume. They facilitate data access via Kubernetes' native storage solutions and ensure compatibility with the Kubernetes ecosystem. Currently, VTraining uses FlexVolume. Its architecture is as follows:
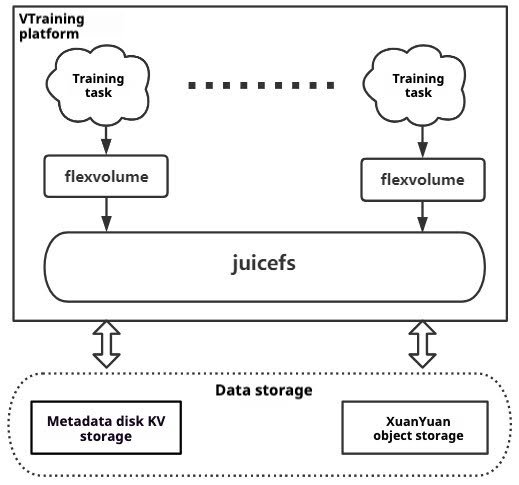
VTraining chose FlexVolume instead of CSI due to the following reasons:
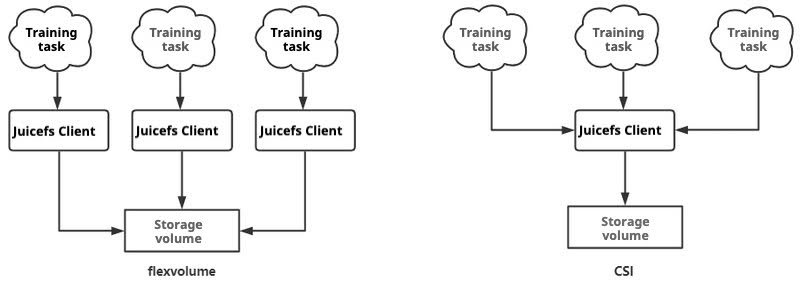
- Monitoring: The JuiceFS client supports comprehensive runtime metric monitoring. When training tasks access storage via FlexVolume, they have exclusive access to the JuiceFS client. In contrast, with CSI, storage access is shared among tasks (on the same node, as shown in the figure below). Therefore, when using CSI, we cannot monitor the storage operation metrics of a task, because the client monitoring reflects the combined situation of multiple tasks. The inability to monitor the storage operation of individual tasks is something we hope to avoid seeing.
- Performance: Both JuiceFS CSI and FlexVolume mount the corresponding storage volumes to training nodes via the JuiceFS client for access by training tasks. Performance is only dependent on the JuiceFS client. CSI and FlexVolume merely differ in how they initiate the JuiceFS client program. Therefore, CSI does not have an advantage in this regard; in resource-abundant scenarios, CSI performance may be lower because multiple tasks share a single client (as shown in the figure below), resulting in suboptimal resource utilization for single processes.
- Fault impact: Because JuiceFS CSI uses a shared client (as shown below), any abnormality in the client affects all tasks on the current node that share it. In contrast, with a dedicated client in FlexVolume, only tasks using that specific client are affected. Furthermore, JuiceFS CSI integrates storage access into the Kubernetes cluster, requiring interaction with key Kubernetes components. If not designed properly, this integration could potentially impact the entire Kubernetes cluster.
- Management: JuiceFS CSI integrates access to JuiceFS storage into the Kubernetes cluster. Therefore, when accessing storage via CSI, it’s necessary to adhere to certain Kubernetes specifications, and corresponding PVs (PersistentVolume) and PVCs (PersistentVolumeClaims) resources must be generated. This requires additional strategies to manage these resources. In contrast, using FlexVolume involves directly calling the JuiceFS client program to mount storage for task pods. This is easy and has lower management costs.
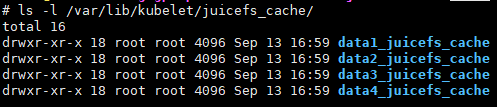
- Caching: JuiceFS CSI Driver 0.10.0 and later does not support the use of wildcards in the
--cache-dirmount option. However, wildcards are essential in the VTraining platform. Because cluster nodes consist of various types of servers with different cache disk resources, and each disk corresponds to a cache directory, the number of cache directories varies among different server types (as shown in the figure below). If the--cache-dirparameter does not support wildcards, it cannot be configured. This is because it’s uncertain which node a training task will be scheduled on and what cache directories exist on that node. In contrast, FlexVolume supports wildcard usage in mount parameters. This allows placing mount directories under the same parent directory and using corresponding wildcards based on directory names to accommodate all server types. For example, as shown in the code block below, setting--cache-dirto/var/lib/kubelet/juicefs_cache/*cacheenables the JuiceFS client to find the corresponding cache directory without concern for the node where the task is running.

VTraining currently has not switched from FlexVolume to CSI for XuanYuan file storage access. This does not mean that JuiceFS CSI is inferior to FlexVolume; rather, JuiceFS FlexVolume is more suitable for current operations in VTraining. For specific usage details of JuiceFS CSI and FlexVolume, see JuiceFS documentation.
Caching application of XuanYuan file storage
To enhance performance, the JuiceFS client for XuanYuan file storage has implemented multiple caching mechanisms aimed at reducing access latency and improving throughput. These mechanisms include metadata caching, data caching, and cache sharing among multiple clients. Due to these strong caching mechanisms, XuanYuan file storage has significantly boosted training efficiency of the VTraining platform.
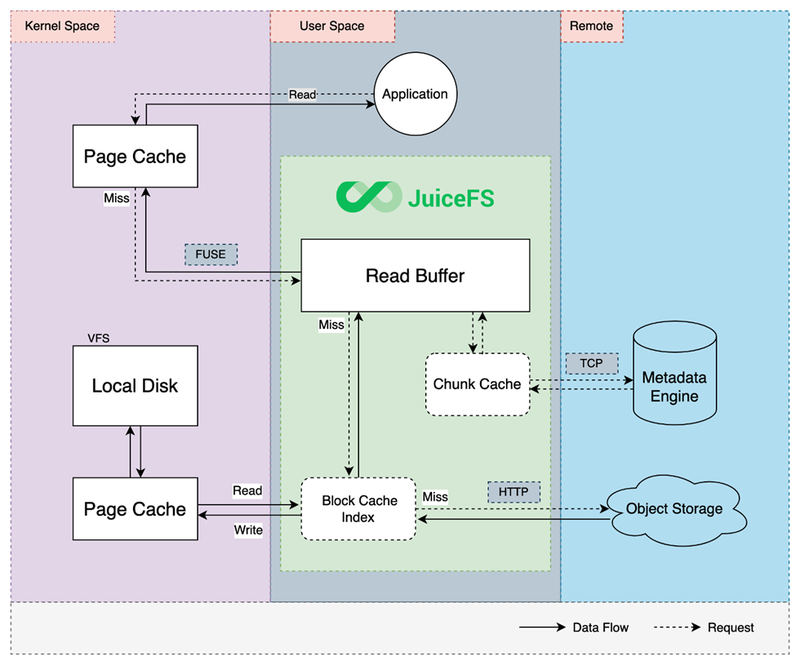
Metadata caching setting
JuiceFS supports caching metadata in both kernel and client memory to enhance metadata access performance.
In the kernel, attributes, file entries, and directory entries can be cached to improve lookup and getattr operations. The duration of caching for these three parameters is configured as follows:
-attrcacheto=10 Attribute cache time, 1 second by default. VTraining sets it to 10 seconds.
-entrycacheto=10 File entry cache time, 1 second by default. VTraining sets it to 10 seconds.
-direntrycacheto=10 Directory entry cache time, 1 second by default. VTraining sets it to 10 seconds.
To reduce frequent listing and querying operations between clients and metadata services, clients can cache frequently accessed directories entirely in client memory, using the following parameters settings:
-metacache Cache metadata in the client, enabled by default.
-metacacheto-5 Cache retention time, 5 minutes by default. vivo chooses the default setting.
Data caching configuration
The JuiceFS client offers a highly flexible data caching strategy where caching can use either memory or disk as the storage medium. For computing platforms dealing with data volumes reaching the petabyte level, caching in memory is impractical. On the VTraining platform, training tasks choose SSD disks as the caching medium, ensuring good caching I/O performance.
There are different caching strategies employed by VTraining based on specific application needs:
- Local cache
- Dedicated cache clusters
Local cache
Local cache involves both the training task and its cached data on the same node, as shown in the diagram below:
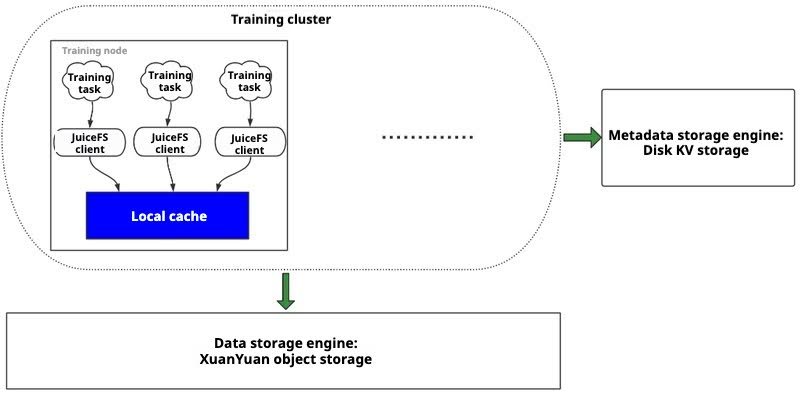
This mode minimizes network overhead from remote access and maximizes I/O performance for training tasks. When cache hit rates are high, training efficiency is significantly enhanced. After the caching strategy was fully launched, users of all applications have given good feedback, and the training efficiency has been significantly improved. The following figure shows the comparison of efficiency before and after using cache for image training tasks:
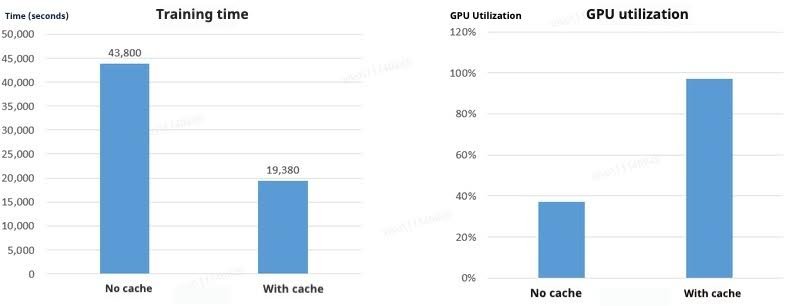
Although the efficiency of local cache has been significantly improved, there are still some problems in certain scenarios, especially for large dataset training:
- The cache disk capacity of each node is limited, and the cache data stored is limited. When the training tasks on the node require more data than the cache disk capacity, cache misses will inevitably occur. In extreme cases, the node cache will fail.
- The same training data may be shared by different training tasks, and these tasks are likely to be scheduled on different nodes. This will cause the caches of multiple nodes to contain the same cached data. The cache resource utilization rate is not high for the cluster, and the cached valid data becomes less. This will also aggravate the cache failure.
- In many cases, it’s necessary to warm up the dataset in advance to improve the performance when accessing the data for the first time. Local cache is not very friendly to warm-up. You don’t know which node the training task will be scheduled to (if no node scheduling is specified), and you don’t know which node to warm up. If the task changes nodes for the next training, it will have to be warmed up again.
JuiceFS provides features of cache groups and independent cache clusters to address these issues.
Cache groups and independent cache clusters
By using JuiceFS' cache data sharing feature, JuiceFS clients on different training nodes can form a cache group. Within this cache group, JuiceFS clients can share cached data. Therefore, if a training task wants to share the data of the cache group, its JuiceFS client must join the cache cluster. That is to say, when the node where the training task is located does not hit the cache, the data can be obtained through other nodes in the same cache group without requesting remote object storage.
However, the training task is not a static resource. Once the operation is completed, the corresponding JuiceFS client also ends. This causes the members of the cache group to be frequently updated. Although the cache group uses consistent hash to ensure that when cluster members change, as little data needs to be migrated as possible. However, the cache group members composed of JuiceFS client storage that relies on tasks change too fast. This cannot be used in practice unless your task never ends.
So what is the solution to this problem? This requires the unique "independent cache cluster" feature of JuiceFS. The same cache group can be divided into two roles:
- One does not participate in the cache group's data caching and only reads data from the cache group
- The other participates in the cache group's data caching.
We use the latter to form a cache cluster for the former. This cache cluster is an independent cache cluster of JuiceFS, as the figure below shows:
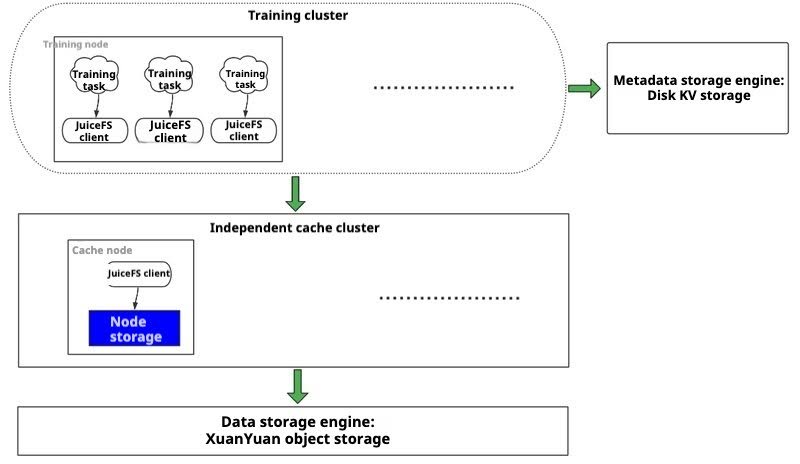
We can create a cache group by using the same mount parameter --cache-group={cache-group-name} for the JuiceFS clients in the training cluster and the independent cache cluster. Then, the JuiceFS clients in the training cluster should be mounted with the --no-sharing parameter to indicate that they do not participate in data caching. In this way, the clients for training tasks will not affect the cache group of the cache cluster while still being able to share cached data from the independent cache cluster to accelerate task training. Although this mode performs slightly worse than local caching, it perfectly solves the issues of local caching:
- The independent cache cluster essentially combines the disks of the nodes within the cluster into one large disk. With this setup, the same data only needs to be cached once within the cluster and can then be accessed by tasks on different nodes. This perfectly addresses the issues of insufficient cache disk space and low effective data utilization.
- It’s also very friendly for warming up data acceleration. As long as you warm up on any node of the independent cache cluster, the data can be warmed up to the cluster. No matter which node the task is scheduled to, there is no need to warm up for the second time.
JuiceFS also supports using local cache together with independent cache clusters to maximize performance. If you have any questions or would like to learn more, feel free to join JuiceFS discussions on GitHub and their community on Slack.
Acknowledgements
Special thanks to Rui Su, Davies, and Weiwei Zhu from the JuiceFS team, as well as Bo Xiao, Bing Gong, Xiangyang Yu, Jiang Han, and Min Chu from the storage team at vivo's Internet infrastructure platform, for their invaluable support in the design and implementation of XuanYuan file storage on the VTraining platform.