














As artificial intelligence (AI) technology rapidly develops, the scale and complexity of models, as well as the volume of data to be processed, are rising sharply. These trends make high-performance computing (HPC) increasingly necessary. HPC integrates powerful computing resources such as GPU and CPU clusters to provide the computing power needed to process and analyze large-scale data.
However, this also brings new challenges, especially in the storage system, including how to effectively handle large amounts of data and ensure efficient data access and operations costs.
Distributed file systems, as a high-cost, high-benefit solution, are gradually being widely adopted in AI and HPC storage. They distribute storage resources across multiple nodes, effectively handling and managing large datasets to meet HPC's high demands for data access speed.
Renmin University of China, one of the top universities in China, has conducted research in the fields of file systems for AI. Our HPC storage center provides strong support for scientific research. We’ve conducted preliminary performance evaluations of mainstream distributed file systems, including Lustre, Alluxio, and JuiceFS.
In this article, we’ll deep dive into the data patterns and characteristics of HPC, big data, and AI applications. Then, we’ll share common performance evaluation tools and our evaluation results of several file systems. We hope this post can provide valuable references for users choosing HPC and AI storage solutions.
Large-scale data application scenarios: HPC vs. AI
High-performance computing
HPC plays a critical role in scientific research and engineering applications, such as climate prediction, protein folding, and computational fluid dynamics. Unlike the methods employed by machine learning and AI, HPC often relies on simulation and scientific formulas to solve complex problems.
In HPC, tasks can be divided into compute-intensive and data-intensive. For example, weather forecasting requires a large amount of computing resources to simulate weather and also needs to process and analyze large volumes of data. Compute-intensive tasks such as molecular dynamics simulations are compute-intensive and less dependent on data.
The following figure (source: Introduction to HPC: What are HPC & HPC Clusters?) shows an HPC cluster architecture:
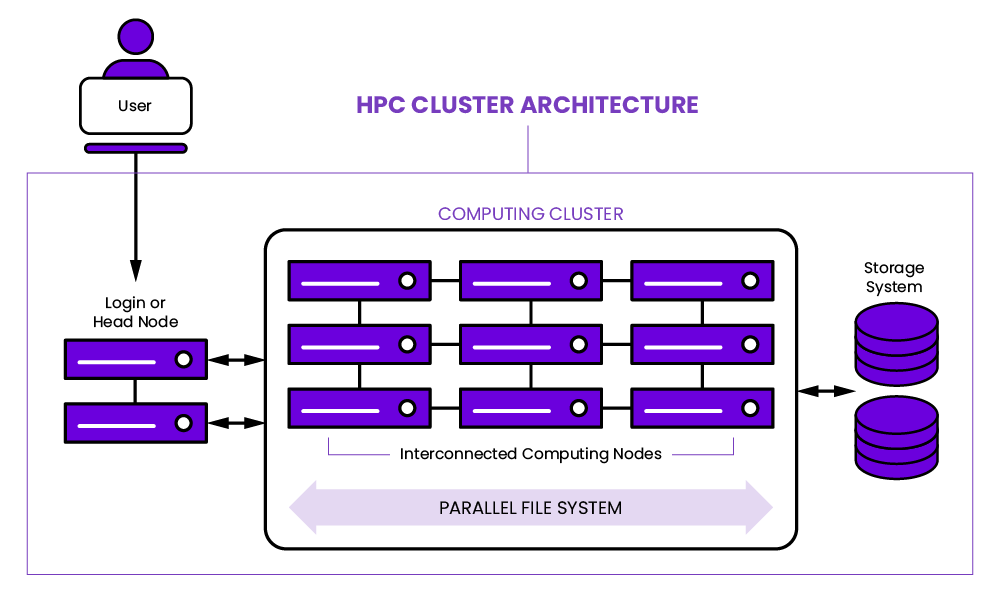
HPC storage typically uses high-bandwidth, low-latency networks such as InfiniBand to support fast data transfer. In terms of software configuration, efficient data communication between multiple nodes depends on standards like the message passing interface (MPI).
In addition, the application of GPUs in HPC is increasing, which accelerates various computing tasks. Compared to traditional data centers, HPC clusters significantly differ in their network configuration and use of shared file systems.
To see how JuiceFS is applied in HPC storage scenarios, refer to use cases:
- Accelerating HPC storage with JuiceFS: A Use Case from Unisound
- AI & HPC storage: DP Technology's Storage Challenges and Solutions
Artificial intelligence (AI)
In recent years, the development in the AI field has been widely acknowledged. Its workloads include training and inference. Particularly, with the emergence of large-scale models such as GPT and BERT, AI's dependence on HPC has deepened. These complex models urgently require robust computing resources to shorten training time; at the same time, they also bring challenges regarding efficient management of large datasets.
The following figure (source: ML Workflows: What Can You Automate?) shows an AI pipeline:
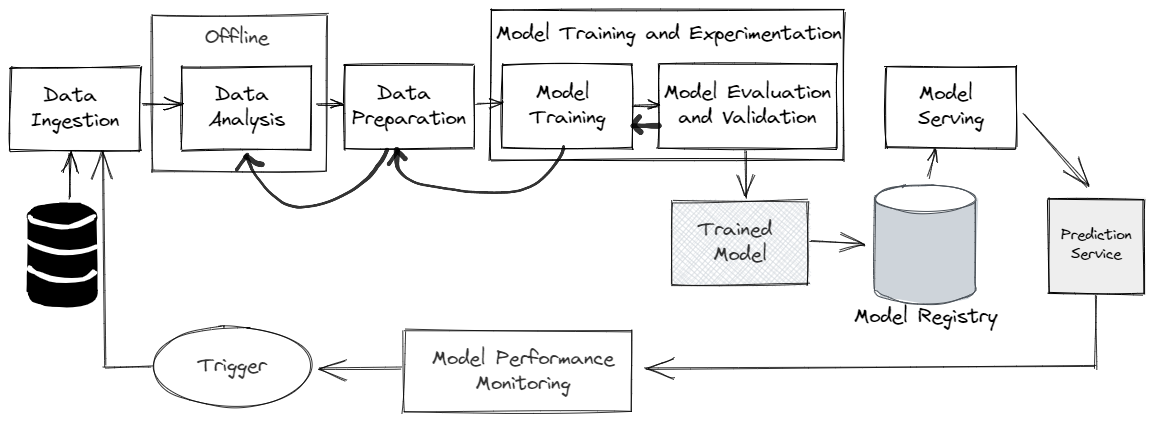
In this context, file systems face specific requirements, especially when handling numerous small image or video files. These files typically range from a few kilobytes to several megabytes, imposing high demands on IOPS.
There’s a notable characteristic during AI model training, that is, the same data would be used for multiple training jobs at the same time. Machine learning engineers and scientists would experiment with different hyper-parameters, modifying network architectures and trying various optimization techniques on the same data.
Therefore, AI model training is not only a compute-intensive task but also a process that requires meticulous adjustments and fine-tuning. This method of continuously adjusting parameters and model structures is key to achieving efficient and accurate AI models.
In this background, data preprocessing is particularly critical in AI model training. For example, Hugging Face’ Falcon demonstrates the importance of data preprocessing in handling large-scale models. They established a long processing pipeline for handling large model data, starting from raw external web data and undergoing multiple preprocessing steps such as URL filtering and deduplication.
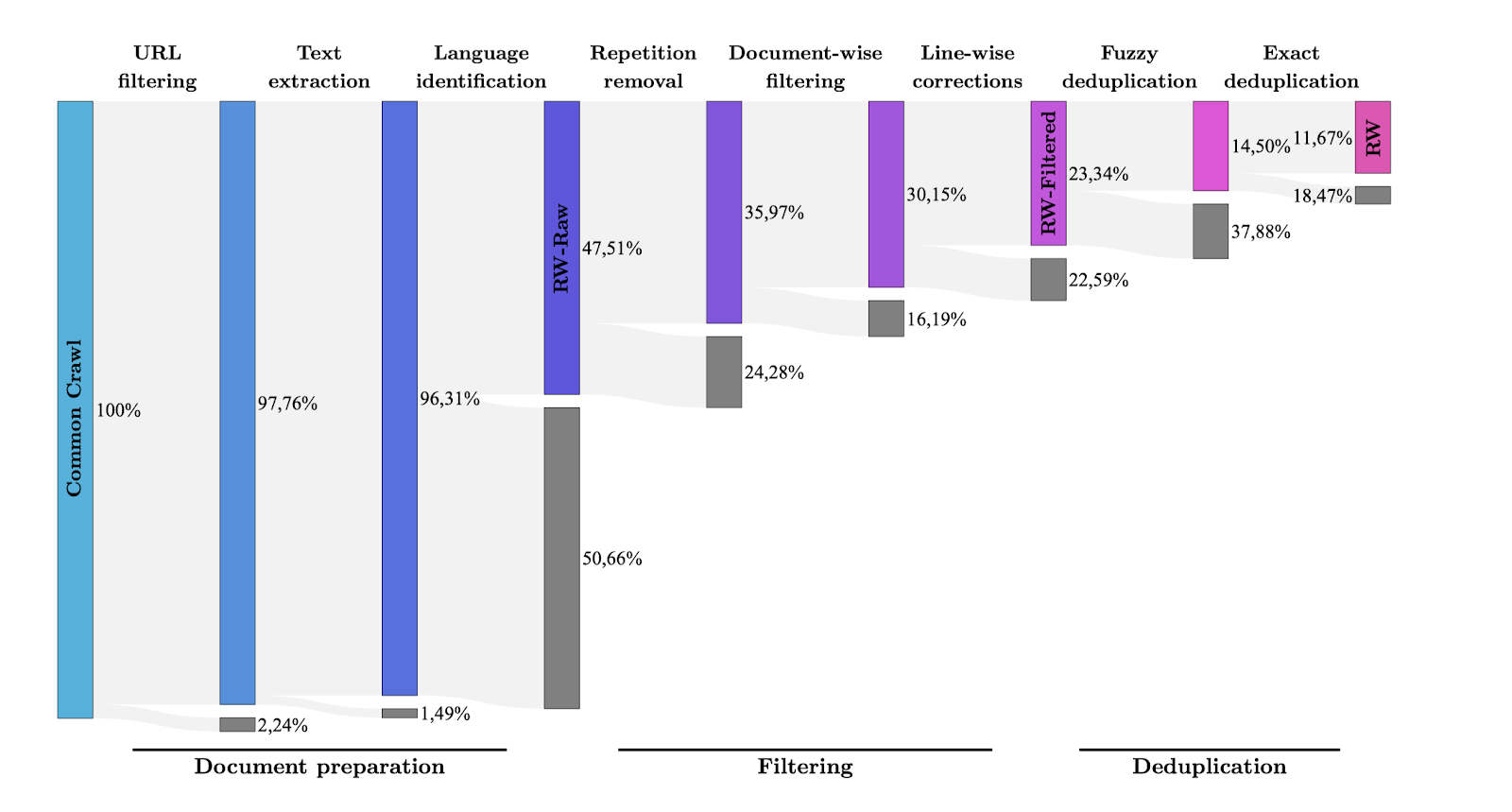
As the figure (source: The RefinedWeb Dataset for Falcon LLM: Outperforming Curated Corpora with Web Data, and Web Data Only) below shows, each step gradually reduces the dataset size. After several processing stages, less than 10% of the data remains suitable for training large language models (LLMs). Thus, we can see that data preprocessing constitutes a substantial portion of the work in training large models, involving tasks like data cleaning, HTML tag extraction, ad filtering, and text recognition. These steps are crucial for ensuring data quality and training results.
The role of distributed file systems in AI & HPC storage
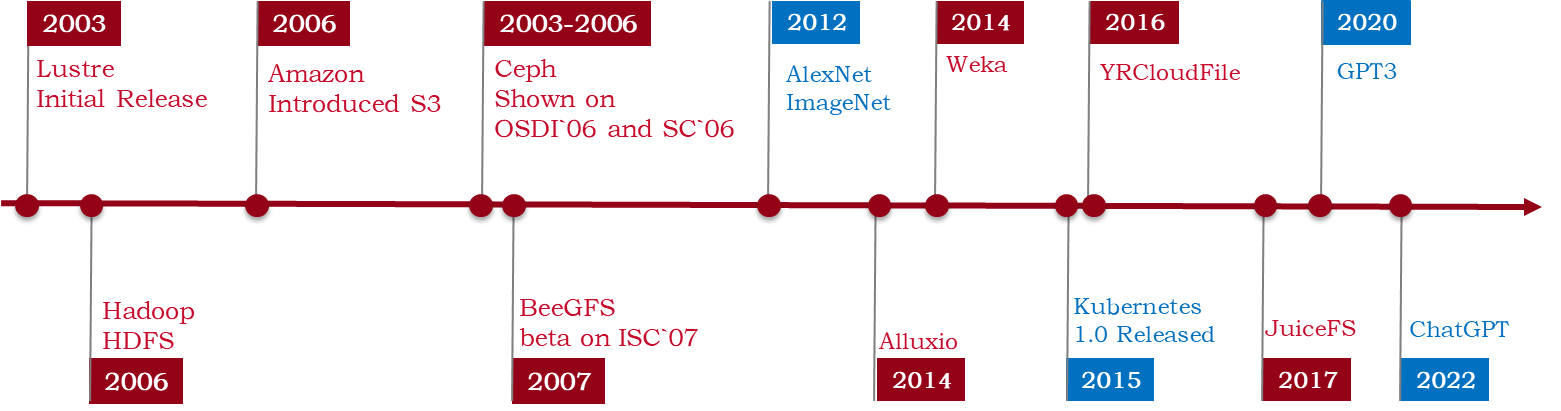
First, let's briefly review the evolution of file systems, where emerging needs at each stage have spurred the development of new-generation file systems.
- Lustre, one of the earliest distributed file systems, was designed for HPC and funded by the U.S. government.
- The emergence of file systems like Hadoop and S3 primarily addressed the explosive growth of internet data, along with big data processing-oriented file systems like Ceph. These systems aimed to support big data applications.
- With the advent of Kubernetes, cloud-native data management and applications have gradually become the focus. This leads to the development of various emerging data management systems and applications like JuiceFS.
As the foundational infrastructure for data storage and access, file systems directly impact the training and inference processes of AI models. When applying file systems to AI scenarios, they often face two key challenges:
- High IOPS: The primary challenge is processing datasets with large amounts of small files, such as images and videos. This places high demands on file systems’ IOPS. Bandwidth is usually sufficient, but file systems’ IOPS processing capability often limits performance.
- Portable: The complexity of AI workflows and collaboration across teams require file systems to have high portability and compatibility. This ensures support for various data processing and model training tools, facilitating the smooth exchange and processing of data between teams.
To improve performance, some solutions adopt high-performance storage media such as SSD or NVMe and implement local caching. Here's a brief introduction to a common concept in academia: burst buffer, which refers to a cache layer between the front-end computing processes and the back-end storage systems. Different file systems provide their unique solutions. We’ll introduce them one by one in the following text.
In addressing compatibility issues, providing POSIX interfaces ensures compatibility and portability and can also lower user learning costs. POSIX refers to a series of file interfaces in the Linux operating system, and POSIX-compatible file systems means users can work with distributed file systems just like with their local machines. However, from a development perspective, implementing POSIX compatibility may incur additional development costs and complexity. Products like HDFS and Amazon S3 do not adopt complete POSIX compatibility. They require developers or users to use their pre-defined APIs or tools. This may involve changing existing usage habits and learning new tools.
The table below compares POSIX and non-POSIX file systems:
| Category | Pros | Cons | File systems |
|---|---|---|---|
| POSIX | Devs, ops, and software rely on POSIX , Portable | Overhead | Lustre, JuiceFS |
| Non-POSIX | Low cost | Limited abilities , Additional code for users | HDFS, S3 |
Next, we’ll introduce several file systems suitable for AI scenarios to help you better understand the advantages and limitations of various file systems in AI applications.
Lustre
Lustre performs well in HPC scenarios because it was designed to meet the needs of supercomputers. Its support for the POSIX protocol and development using C and C++ makes Lustre very suitable for handling large-scale parallel computing tasks.
The figure below shows Lustre’s architecture:
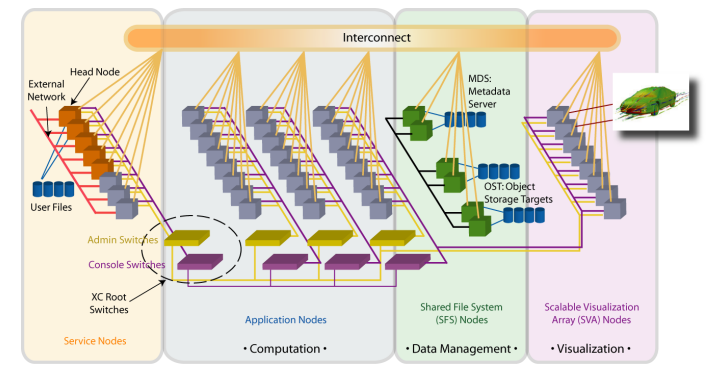
Lustre's architecture is particularly suitable for typical HPC cluster environments, which include high-speed data transmission using the InfiniBand network. The cluster contains multiple computing nodes (“Computation” in the figure) and storage nodes (“Data Management” in the figure). They’re used for processing metadata by the metadata server, while the actual data is stored on object storage (“Object Storage” in the figure). This design optimizes support for MPI applications. Especially MPI-IO, the ability for multiple processes to read and write to a file simultaneously, is particularly important for parallel computing and scientific research applications.
The direct application of MPI-IO might be less common in AI and machine learning workloads. This is primarily because file operations in these applications mainly involve writing checkpoints rather than complex distributed I/O. However, the characteristics of MPI-IO remain highly important for scientific computing applications that require parallel processing and complex data interaction.
In terms of caching, the Lustre file system recently introduced a feature called Lustre Persistent Cache on Client (PCC). However, in practice, it requires a lot of configuration by operations staff.
Click here to explore a detailed comparison between Lustre and JuiceFS architectures.
Alluxio
We attempted to deploy Alluxio as a data caching layer. Alluxio's design philosophy is mainly as a cache above underlying storage systems, such as HDFS or S3, to accelerate data access. Alluxio is particularly suitable for big data scenarios, such as using it with big data processing systems like Spark.
Tests in AI and machine learning scenarios have shown that its performance did not meet our expectations. In AI scenarios, especially when the initial request included datasets containing a large number of small files, this process on Alluxio was extremely slow. Taking the ImageNet dataset as an example, we noticed that it may take several hours for the data to be initially loaded into Alluxio. This severely affected performance. According to the latest news, Alluxio has also optimized for this issue, providing a storage solution designed specifically for AI. It is currently for commercial use only and not open source.
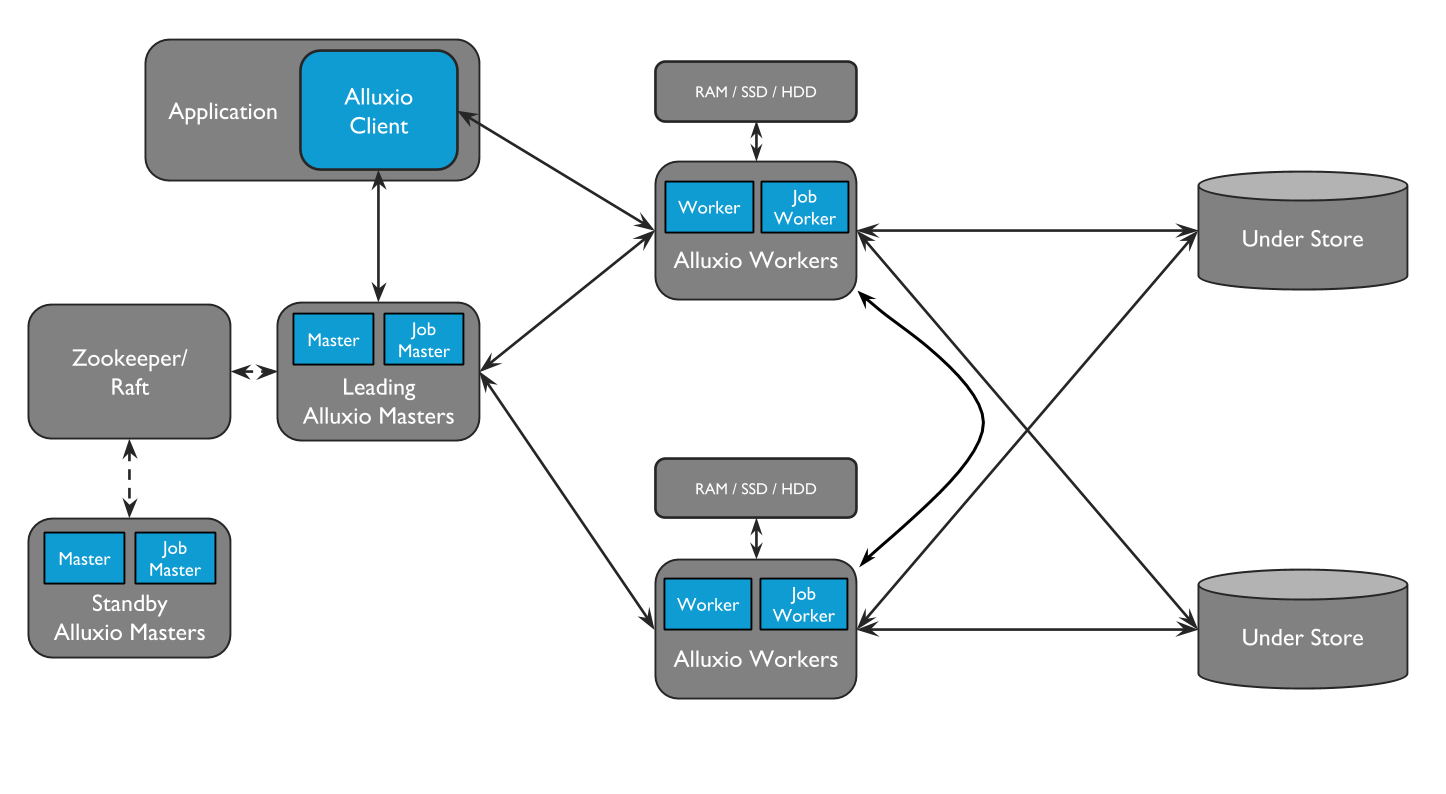
The following figure (source: Alluxio architecture) shows the Alluxio architecture:
JuiceFS
We conducted preliminary proof of concept (PoC) tests on JuiceFS Community Edition and have not yet fully deployed it in our production environment.
JuiceFS is a high-performance, cloud-native, distributed file system designed to provide efficient data storage and access in cloud environments.
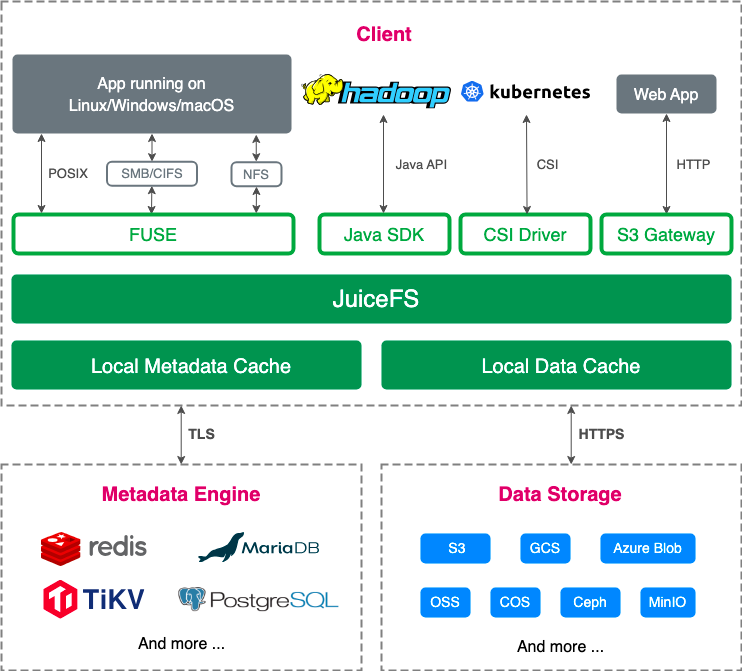
In JuiceFS, data is stored in chunks in object storage such as S3, while metadata is stored in database systems such as Redis, MySQL, or PostgreSQL. This design makes metadata management efficient and flexible. Clients access JuiceFS through mounting the Filesystem in Userspace (FUSE) interface. This enables it to seamlessly run on various operating systems. In addition, JuiceFS offers a POSIX file system interface, which is familiar to users. Moreover, JuiceFS' caching feature directly supports burst buffers.
The figure below shows the architecture of JuiceFS Community Edition:
From a cost perspective, JuiceFS' operating costs are much lower than traditional disk arrays. This is mainly due to its cloud-native design, which effectively utilizes cloud storage resources and reduces reliance on physical hardware.
Benchmark tools and PoC results
When evaluating file system performance, benchmark tools like IOzone, MDTest, and fio are widely used to test IOPS and bandwidth. However, standard benchmark tools cannot fully reflect the requirements and load characteristics of real-world application scenarios. To obtain performance evaluations closer to actual workloads, the MLPerf tool was designed.
MLPerf simulates real AI workloads for evaluation and provides a series of tests. In the computer vision field, it uses the residual neural network (ResNet) model for testing; in text processing, it uses GPT-3 or Bidirectional Encoder Representations from Transformers (BERT) models and test on Wikipedia or C4 datasets.
The following table outlines standard AI performance benchmarks in different domains, including vision, language processing, and recommendation systems. It specifies the datasets used in each test, the performance goals aimed at, such as accuracy and error rate, and the reference models for each test, like ResNet, BERT, and GPT-3. This provides a unified framework for evaluating and comparing AI model performance.
| Area | Benchmark | Dataset | Quality target | Reference implementation model |
|---|---|---|---|---|
| Vision | Image classification | ImageNet | 75.90% classification | ResNet-50 v1.5 |
| Vision | Image segmentation (medical) | KiTS19 | 0.908 Mean DICE score | 3D U-Net |
| Vision | Object detection (light weight) | Open Images | 34.0% mAP | RetinaNet |
| Vision | Object detection (heavy weight) | COCO | 0.377 Box min AP and 0.339 Mask min AP | Mask R-CNN |
| Language | Speech recognition | LibriSpeech | 0.058 Word Error Rate | RNN-T |
| Language | NLP | Wikipedia 2020/01/01 | 0.72 Mask-LM accuracy | BERT-large |
| Language | LLM | C4 | 2.69 log perplexity | GPT3 |
| Commerce | Recommendation | Criteo 4TB multi-hot | 0.8032 AUC | DLRM-dcnv2 |
We used fio to compare Lustre, JuiceFS, and XFS. Below are our preliminary test results:
- In terms of IOPS and bandwidth read performance, Lustre configured with full NVMe flash showed very high performance.
- In testing the ImageNet dataset on PyTorch, all file systems completed the task in similar times, with JuiceFS + S3 and XFS + local SSD sharing the lowest.
- During LLM checkpoint testing, Lustre + all flash took only 1 minute, much faster than the 10 minutes of Lustre + HDD.
| Item | Lustre + all flash | Lustre + HDD | JuiceFS + S3 | XFS + local SSD |
|---|---|---|---|---|
| Fio IOPS READ | 2,700k | 20k | 14k | 40k |
| Fio BW READ | 30 GB/s | 12 GB/s | 2.6 GB/s | 0.9 GB/s |
| ImageNet PyTorch | 1,600s | 1,640s | 1,570s | 1,570s |
| LLM checkpoint (LLaMA 70B) | 1 min | 10 min |
Conclusion: Optimizing storage for HPC and AI
Choosing the right HPC storage solution is critical for enterprises and research organizations looking to scale their computing resources. Solutions like JuiceFS, Lustre, and Alluxio provide the high performance, scalability, and data management efficiency required to meet the demands of both HPC and AI applications.
When selecting a storage solution, factors such as cost, performance, and compatibility with existing infrastructure must be considered. In addition, for large-scale AI tasks that leverage HPC infrastructure, a distributed file system that can handle large datasets efficiently is essential for ensuring that performance, cost, and scalability are optimized.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.



