















Note: This post was published on DZone.
Zhejiang Lab is a top research institute in China, focusing on intelligent sensing, AI, computing, and networks. We specialize in various scientific fields, like materials, genetics, pharmaceuticals, astronomy, and breeding. Our aim is to become a global leader in basic research and innovation.
Finding a storage solution for our ultra-heterogeneous computing cluster was challenging. We tried two solutions: object storage with s3fs + network-attached storage (NAS) and Alluxio + Fluid + object storage, but they had limitations and performance issues.
Finally, we chose JuiceFS, an open-source POSIX-compatible distributed file system, as it offers easy deployment, rich metadata engine options, atomic and consistent file visibility across clusters, and caching capability for reduced pressure on underlying storage. Our test shows that JuiceFS excelled over s3fs in sequential reads/writes, with sequential reads 200% faster. Now we use it in general file storage, storage volumes, and data orchestration.
In this article, we’ll dive into our storage challenges, why we chose JuiceFS over s3fs and Alluxio, how we use it, and the issues we encountered and their solutions. We hope this post can help you choose a suitable storage system based on your application needs.
Our storage challenges
We built an ultra-heterogeneous computing cluster
Our lab is developing an intelligent operating system, which consists of two components:
- A general-purpose computing platform solution that supports various applications in domains such as computing materials, pharmaceuticals, and astronomy.
- A heterogeneous resource aggregation solution for managing multiple clusters, including CPU, GPU, and high performance computing (HPC) resources.
At our computing and data center, we deployed multiple sets of heterogeneous clusters. These clusters are abstracted and managed using Kubernetes (K8s) for unified control. A meta-scheduler allocates application instructions and jobs based on scheduling policies like computing and performance priorities. Now we’ve integrated about 200 PFLOPS of AI computing power and 7,000 cores of HPC computing power.
Storage requirements for computing power
The heterogeneous nature of computing resources and the diverse system architectures and instruction sets employed led to software incompatibility. This impeded efficient computing power usage. To address this issue, we consolidated various heterogeneous computing resources into a vast computing pool.
Our computing power storage requirements included:
- Abstraction and unification of the storage layer: Many computing scenarios, such as HPC and AI training, utilize the POSIX interface. Therefore, we wanted an interface to provide unified services at this layer.
- Generalization of the storage solution: Our integrated computing power clusters are heterogeneous, requiring a solution that can be applied to different types of clusters.
- Data arrangement conditions: We have both hot and cold data. During task computation, the data being actively used is hot data. As time passes or after a few days, the data becomes cold, resulting in fewer reads and operations.
- High performance for storage: Efficient data read and write performance, particularly for hot data reads, is crucial. In computing power clusters, computing resources are valuable, and slow data reading leading to CPU and GPU idle waiting would result in significant waste.
Why we rejected s3fs and Alluxio
Before JuiceFS, we tried two solutions, but they were not ideal.
Solution 1: Object storage with s3fs + NAS
Advantages of this solution:
- Simple architecture
- Easy deployment
- Out-of-the-box usability
Disadvantages of this solution:
- Directly using object storage had poor performance.
- The s3fs mount point for object storage frequently got lost. Once the mount point was lost, containers could not access it, and restoring the mount point required restarting the entire container. This caused significant disruption to user operations.
As the cluster gradually scaled and the number of nodes expanded from initially 10+ to 100+, this solution did not work.
Solution 2: Alluxio + Fluid + object storage
Advantage of this solution: Better performance compared to object storage with s3fs + NAS.
Disadvantages of this solution:
- Complex architecture with multiple components.
- Alluxio was not a file system with strong consistency but rather a caching glue layer. We operate in a highly heterogeneous multi-cluster environment, where metadata consistency is critical. Given the diverse range of user applications and the need to avoid interfering with their usage patterns, inconsistent data across clusters could lead to severe issues.
- The underlying object storage posed challenges on metadata performance. As the data scale grew, operations like metadata synchronization and cache layer initialization in new clusters faced significant performance bottlenecks.
- Alluxio's compatibility and client performance did not meet our expectations. While Alluxio provides unified access to different data sources for reading, it may not be ideal for frequent writes or updates.
Why we chose JuiceFS
JuiceFS is an open-source, high-performance, distributed file system designed for the cloud.
The following figure shows its architecture:
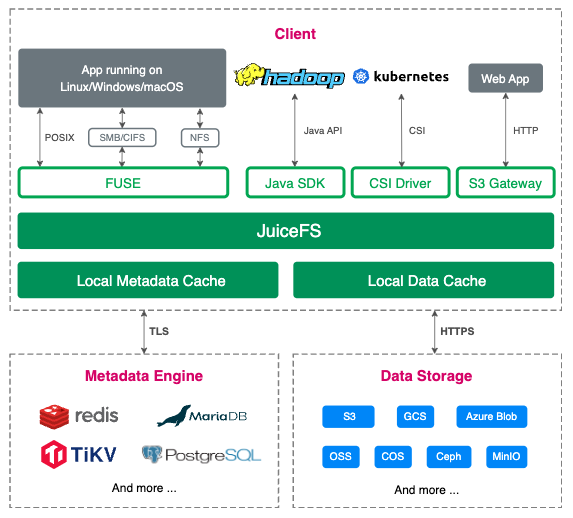
Advantages of JuiceFS
JuiceFS has these advantages:
- Easy deployment: JuiceFS provides detailed community documentation, making it user-friendly for quick setup. It performed exceptionally well in our test clusters and final production deployment. JuiceFS supports CSI for containerized deployment, making it our chosen storage foundation for computing power.
- Rich metadata engine options: JuiceFS offers various metadata engines such as Redis and TiKV, resulting in excellent metadata performance. Currently, we use a three-node TiKV setup as the metadata engine in our lab. However, as the performance is no longer sufficient, we plan to gradually enhance it. Initially, we considered using Redis as the metadata engine, but it lacked horizontal scalability. Using TiKV allows us to incrementally scale as the file system grows, which is indeed better.
- Atomic and consistent file visibility across clusters: JuiceFS enables atomicity and consistency of files in a cross-cluster environment. Files written in Cluster A are immediately visible in Cluster B.
- Caching capability: JuiceFS supports client-side caching, allowing for reduced pressure on underlying storage in computing clusters.
- Excellent POSIX compatibility: JuiceFS has strong compatibility with the POSIX interface.
- An active community: JuiceFS benefits from a vibrant and engaged community.
JuiceFS outperforms s3fs and NAS in I/O performance
We conducted performance tests on JuiceFS, s3fs, and NAS using the following tools:
- Flexible I/O Tester (FIO) with 16 threads
- 4 MB block size
- 1 GB of data
The test results are as follows:
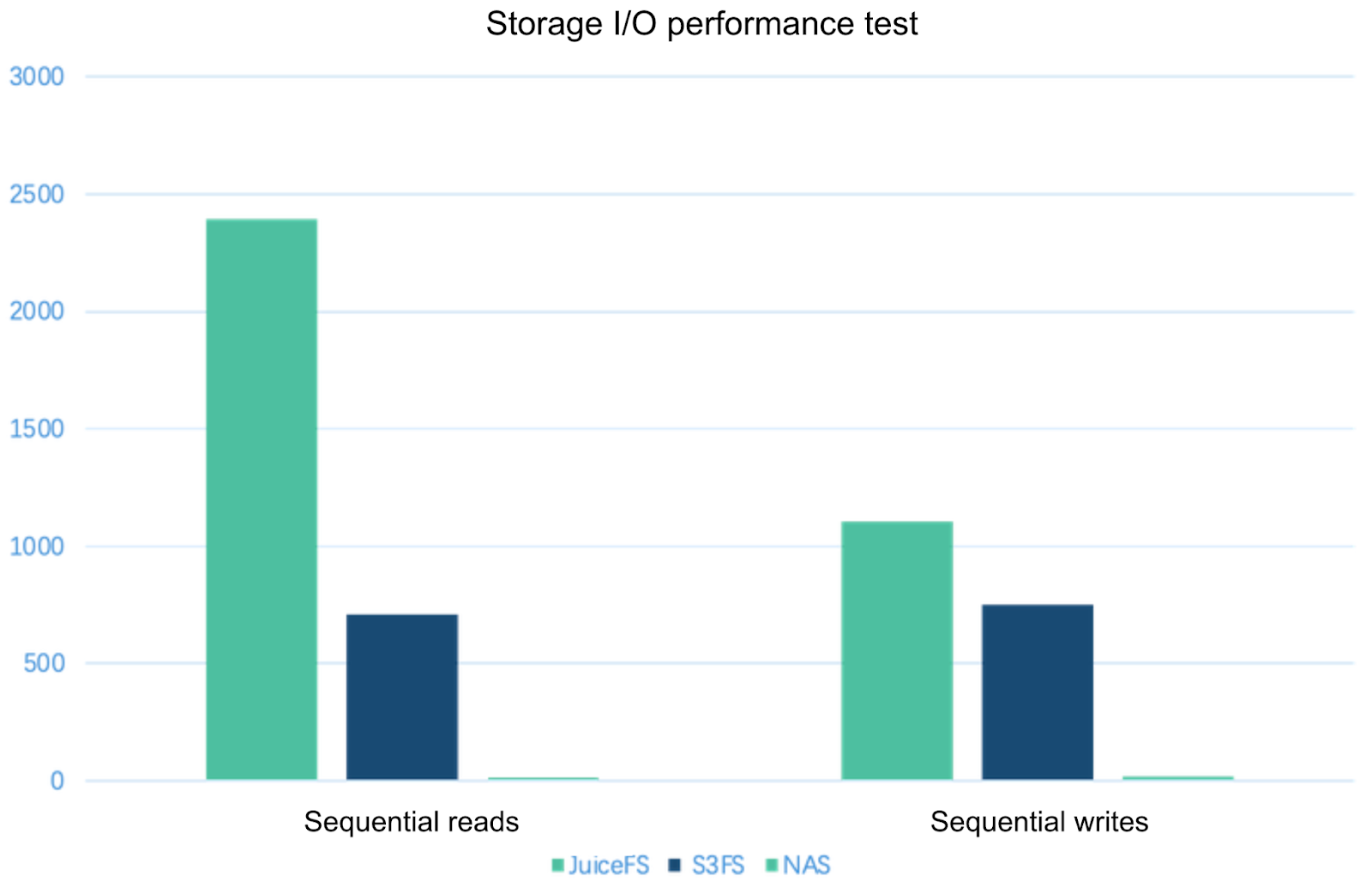
The test results show that:
- JuiceFS outperformed both s3fs and NAS in terms of I/O performance.
- JuiceFS excelled over s3fs in sequential read/write performance, with sequential reads 200% faster.
During the evaluation, NAS was still providing services in a production environment, with approximately seventy-plus nodes running concurrently. The limited bandwidth severely affected its performance.
Evolution of our storage-compute decoupled architecture
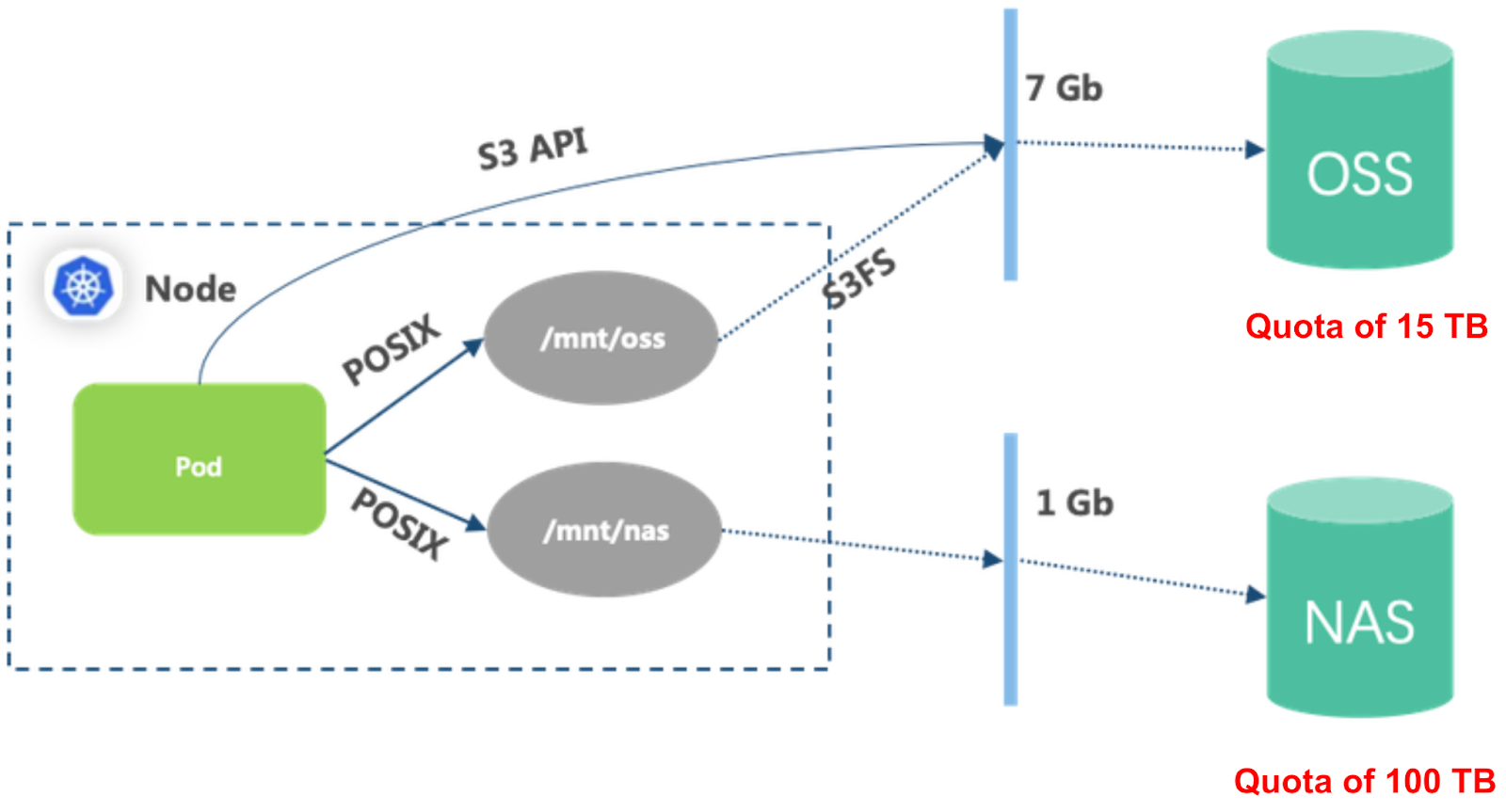
Initially, the high-performance computing process consisted of multiple stages, with data scattered across different storage systems, posing challenges in efficiency and convenience. To simplify data management and flow, we implemented a unified storage infrastructure as the foundation. This storage foundation prioritizes high reliability, low cost, and high throughput, leading us to choose object storage. Storing data in object storage allows for seamless data tiering, optimizing storage space.
However, using object storage directly within the computing cluster presented certain issues:
- Poor metadata performance, especially when dealing with a large number of files in the same directory, resulting in lengthy operations.
- High bandwidth consumption due to the data lake's reliance on a regular IP network rather than a high-speed remote direct memory access (RDMA) network, leading to limited overall bandwidth.
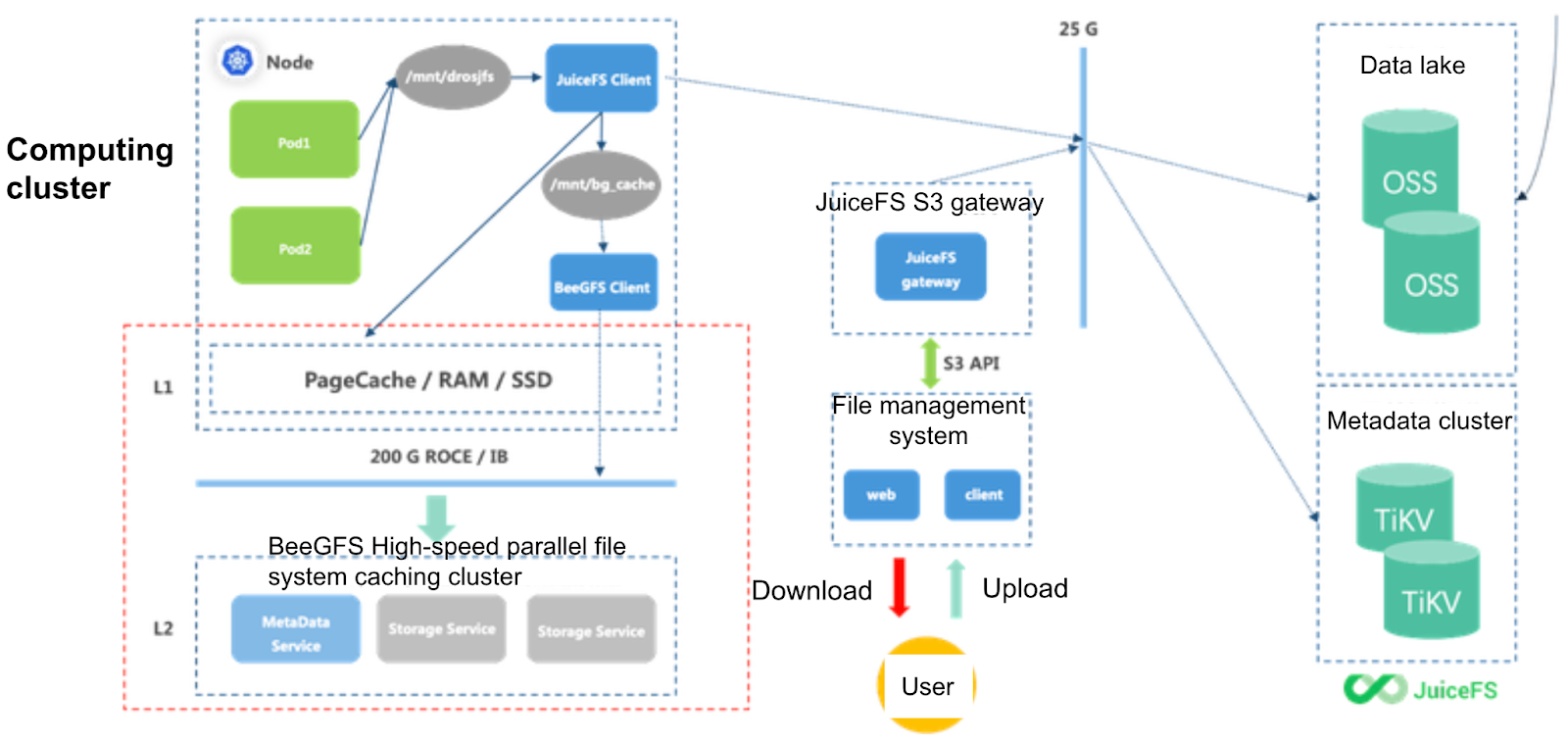
By adhering to the following principles, our evolving architecture ensures efficient storage and compute separation while optimizing data flow and performance:
- Alongside object storage, we established a metadata cluster utilizing the TiKV database. Building upon object storage and TiKV, we developed the JuiceFS distributed file system. The computing clusters access the file system by installing the JuiceFS client on nodes. Therefore, we enhanced metadata performance, reduced bandwidth consumption, and overcame the limitations of object storage.
- To enable efficient data flow, we introduced a file management system, powered by the JuiceFS S3 gateway, enabling file upload and download operations.
- To facilitate seamless data flow between computing clusters and the object storage data lake foundation, we deployed a high-speed caching cluster within the computing clusters. This cluster focuses on achieving optimal I/O performance. Users can seamlessly access data without being concerned about its location, whether in object storage or the high-speed caching cluster.
- The computing system manages data flow, utilizing a 200 G RDMA high-speed network connection between the computing clusters and the high-speed caching cluster. The high-speed caching cluster incorporates the BeeGFS high-performance parallel file system, mounted as a directory on the computing clusters. This allows for straightforward utilization of the caching system as if it were a local directory.
How we’re using JuiceFS
Storage requirements and performance metrics vary across different application scenarios. To efficiently serve users, we proposed the concept of productizing storage capabilities. JuiceFS is currently being applied in the following storage product categories.
General file storage
JuiceFS stores data in a designated directory and generates a unique access path based on the user's organizational structure. By directly mounting this path to containers, data isolation is achieved. Users can upload and download files through the web interface or perform file operations using our provided commands and tools.
Storage volumes
During the initial development phase, general file storage faced scalability issues in terms of capacity. The underlying object storage cluster had limited capacity, preventing users from obtaining additional storage space. To address this, we introduced the concept of storage volumes.
Storage volumes can be likened to cloud drives, where different volumes represent different types of cloud drives. For scenarios involving frequent read and write operations on numerous small files, a storage product with low latency and high throughput is required. To meet this demand, we repurposed our high-speed caching cluster into a high-speed storage volume. Users can directly access the file system directory, experiencing the performance advantages of high-speed storage without relying on JuiceFS.
For users who need to store large amounts of data with infrequent access, we offer a standard storage volume that combines JuiceFS and object storage. This provides larger storage capacity and acceptable throughput performance while enabling network connectivity across clusters, unlike high-speed storage volumes.
Some users have higher performance requirements, such as needing local disk products while ensuring data persistence. In Kubernetes environments, writing data to local disks carries the risk of data loss due to unexpected restarts or physical node issues. In such cases, a persistent solution is necessary. We allocate a portion of storage space from the affected node's local disk as a local storage volume and schedule tasks to designated nodes based on user-specified storage volumes. This solution balances performance and data persistence.
Additionally, different storage products vary in capacity, throughput, and inter-cluster connectivity capabilities. For example:
- High-speed storage enables communication within a cluster but lacks cross-cluster capabilities.
- Storage products also differ in capacity and cost.
- High-speed storage uses all-flash clusters, resulting in higher construction costs, while object storage has relatively lower construction costs and larger storage capacities.
By packaging different storage hardware capabilities into various storage products, we can cater to diverse user business scenarios.
Data orchestration
We implemented data orchestration functionality for JuiceFS. Administrators can upload commonly used datasets to a specific directory within the file system, abstracted as publicly accessible datasets. Different users can mount these datasets when creating jobs. Ordinary users can also upload their private datasets and utilize JuiceFS' warm-up feature to optimize access to these datasets.
In the computing clusters, we established a high-speed caching cluster. By using the warmup command, users' datasets can be warmed up from both ends to the high-speed caching cluster on computing nodes. This enables users to directly interact with their self-built high-performance clusters when performing extensive model training, eliminating the need for remote object storage cluster interaction and improving overall performance.
Moreover, this setup helps alleviate network bandwidth pressure on the object storage foundation. The entire cache eviction process is automatically managed by the JuiceFS client, as the capacity limit for access directories can be configured. For users, this functionality is transparent and easy to use.
Issues encountered and solutions
Slow file read performance
Issue:
We conducted internal tests and collaborated with our algorithm team to evaluate the file read performance. The test results showed that JuiceFS had significantly slower read performance compared to NAS. We investigated the reasons behind this performance disparity.
Workaround:
When we used TiKV as the metadata engine, we discovered that certain API operations, such as directory listing, were random and did not guarantee a consistent order like NAS or other file systems. This posed a challenge when algorithms relied on random file selection or assumed a fixed order. It led to incorrect assumptions about the selected files.
We realized that we needed to manually index the directory in specific scenarios. This is because processing a large number of small files incurred high metadata overhead. Without caching the metadata in memory, fetching it from the metadata engine for each operation resulted in high performance overhead. For algorithms that handled hundreds of thousands or even millions of files, maintaining consistency during training required treating these files as index files forming their own index directory tree. By reading the index files instead of invoking the list dir operation, the algorithm training process ensured consistency in the file directory tree.
Response from the JuiceFS team:
The JuiceFS team found that the slow read performance primarily depended on the user's specific application scenario. They did not make adjustments to the random directory read functionality after evaluation. If you encounter similar issues, contact the JuiceFS team by joining their discussions on GitHub and community on Slack.
TiKV couldn't perform garbage collection (GC)
Issue:
We found that TiKV couldn't perform GC while using JuiceFS. Despite a displayed capacity of 106 TB and 140 million files, TiKV occupied 2.4 TB. This was abnormal.
Solution:
We found that the lack of GC in TiKV's metadata engine might be the cause. The absence of GC metrics in the reports raised concerns. This issue arose because we deployed only TiKV without TiDB. However, TiKV's GC relies on TiDB, which can be easily overlooked.
Response from the JuiceFS team:
The JuiceFS team addressed this issue by incorporating a background GC task for TiKV in pull requests (PRs) #3262 and #3432. They’ve been merged in v1.0.4.
High memory usage of the JuiceFS client
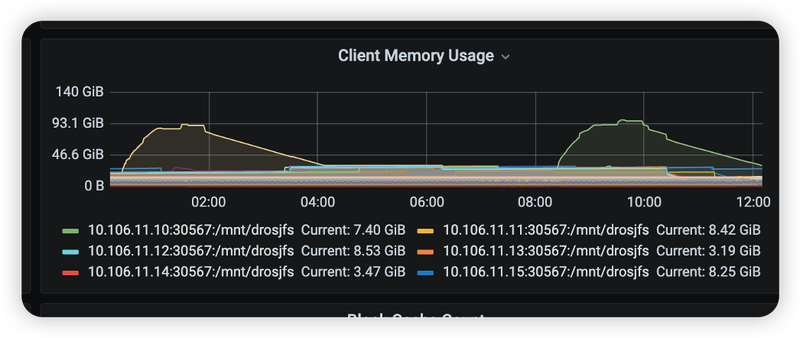
Issue:
When mounting the JuiceFS client, we configured the cache cluster as the storage directory with a capacity of up to 50 TB. The JuiceFS client periodically scanned the cache directory and built an in-memory index to track data in the cache. This resulted in high memory consumption. For directories with a large number of files, we recommend disabling this scanning feature.
Solution:
During testing, we found acceptable performance for random I/O on small files. However, we encountered a significant issue with sequential I/O. For example, when using the dd command to create a 500 MB file, we noticed that JuiceFS generated an excessive number of snapshots. This indicated that the storage and operations on the object storage far exceeded what should be expected for creating a 500 MB file.
Further investigation revealed that enabling the -o writeback_cache parameter transformed sequential writes into random writes, thereby reducing overall sequential write performance. This parameter is only suitable for exceptionally advanced scenarios involving high randomness. Using this parameter outside of such scenarios can lead to serious issues.
Response from the JuiceFS team:
This issue primarily pertains to scenarios where NAS is used as a cache. It has been addressed and optimized in JuiceFS 1.1 beta. The memory footprint during scanning has been significantly reduced, resulting in improved speed. JuiceFS introduced the - -cache-scan-interval option in PR #2692, allowing users to customize the scan interval and choose whether to perform scanning only once during startup or completely disable it. If you use local disks as cache, you do not need to make any adjustments.
Our future plans: expanded range of storage products
A broader range of software and hardware products
We are dedicated to offering a wider variety of software and hardware products and tailoring these capabilities into different storage volumes to meet the diverse storage requirements of users in various scenarios.
Improved data isolation
- We plan to adopt the container storage interface (CSI) mode with customized path configurations to ensure effective data isolation. Currently, there are concerns regarding data security, as all user data is stored within a single large-scale file system and mounted on bare metal machines via hostpath. This setup presents a potential risk where users with node login permissions can access the entirety of the file system's data.
- We’ll introduce a quota management feature, providing users with a means to enforce storage capacity limits and gain accurate insights into their actual consumption. The existing method of using the
ducommand to check capacity incurs high overhead and lacks convenience. The quota management functionality will resolve this concern. - We'll improve our capacity management capabilities. In metering and billing scenarios, it’s vital to track user-generated traffic, power consumption, and bill users based on their actual storage usage.
Monitoring and operations
- When we use JuiceFS, we mount it on bare metal servers and expose a monitoring port. Our production cluster interacts with these ports, establishing a monitoring system that collects and consolidates all pertinent data.
- We’ll enhance our data resilience and migration capabilities. We’ve encountered a common scenario where existing clusters lack sufficient capacity, necessitating the deployment of new clusters. Managing data migration between old and new clusters, along with determining suitable migration methods for different data types, while minimizing disruptions to production users, remains a challenging task. Consequently, we’re seeking solutions to enhance these capabilities.
- We’re developing a versatile capability based on JuiceFS and CSI plugins to facilitate dynamic mounting across diverse storage clients. In production environments, users often require adjusting mounting parameters to cater to various application products. However, directly modifying mounting parameters may lead to disruptions across the entire physical node. Therefore, enabling dynamic mounting capability would empower users to make appropriate switches to their applications without the need for restarts or other disruptive operations.
Conclusion
We use JuiceFS as a storage layer for our ultra-heterogeneous computing cluster, as it offers easy deployment, rich metadata engine options, atomic and consistent file visibility across clusters, caching capability, and excellent POSIX compatibility. Compared to other solutions like s3fs and Alluxio, JuiceFS outperforms them in I/O performance. Now we use JuiceFS for general file storage, storage volumes, and data orchestration.
If you have any questions or would like to learn more, feel free to join JuiceFS discussions on GitHub and their community on Slack.