















Hai Robotics is a technology company specializing in the development and design of tote-based warehouse robotic systems. Our simulation platform uses digital modeling to replicate real-world warehouse environments and equipment. By importing data such as maps, orders, inventory, and strategy configurations, the platform validates and optimizes warehouse solutions, ensuring the efficiency and reliability of designs. Today, our HaiPick Systems are supporting facilities in 40+ countries and regions through 1,300+ systems.
Initially, the simulation platform ran in a standalone environment. However, as data volumes increased, operational challenges emerged. We needed to migrate to a private cloud Kubernetes (K8s) environment and search for a distributed file system compatible with K8s.
The platform processes a lot of small files, supports concurrent writes, and works in a cross-cloud architecture. After evaluating systems like Longhorn and Ceph, we chose JuiceFS, an open-source cloud-native distributed file system. Currently, the platform manages 11 million files in total, with 6,000+ files written daily, averaging 3.6 KB per file. There are more than 50 mount points in use.
In this article, we’ll deep dive into our challenges in simulation platform storage, why we chose JuiceFS over CephFS and Longhorn, the lessons learned while using JuiceFS, and our future plans.
Challenges in simulation platform storage
The simulation platform is a tool based on a discrete event engine. It performs digital simulations to integrate with upper-layer application systems, achieving functionality equivalent to physical devices without requiring physical hardware. Simply put, the platform creates a virtual warehouse where all simulations are conducted.

Traditional companies often rely on commercial software, but such tools struggle with large-scale scheduling and efficient resource utilization. Therefore, we developed our own simulation platform, incorporating IaaS and PaaS services. Unlike commercial software that relies on GPU-based simulations, this platform simplifies computing steps and optimizes event abstraction, significantly reducing computing overhead. Remarkably, it achieves accelerated simulations using only CPUs. The simulation system consists of several key components:
- Core simulation: This includes robot simulations, such as movement, rotation, and speed logic.
- System integration: The simulation integrates directly with our custom scheduling system and Warehouse Management System (WMS), features not typically available in commercial software.
- Operational analysis: The simulation generates significant event data stored in small files. These files are processed on separate nodes to enable storage-compute separation for efficient data extraction and analysis. This approach allows us to effectively identify operational efficiency and potential issues from the simulation data, further optimizing system performance.
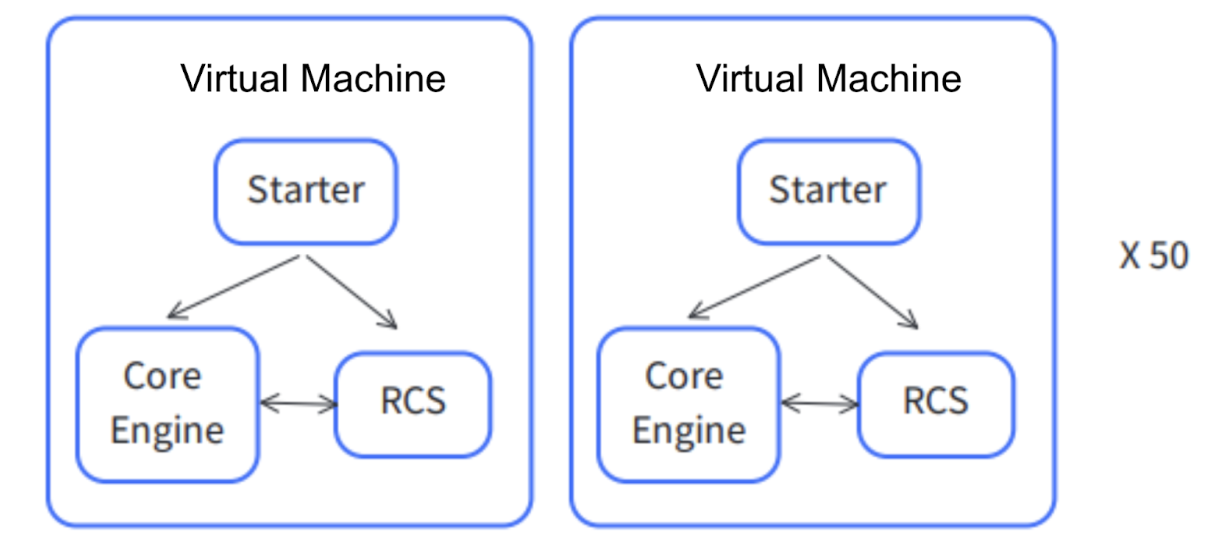
Initially, our simulation platform was a standalone system. This standalone version primarily consisted of a starter, a core engine (similar to a game engine), and real communication protocols that connected it with actual application systems like the Robot Control System (RCS), thereby closely replicating real-world scenarios.
However, the standalone system had some drawbacks. For example, the original core engine was written in Python, which was inadequate for handling high-concurrency I/O operations on a single machine. In addition, as the system expanded to 50 virtual machines, operations and maintenance became increasingly challenging. Given the size of our team, managing such a scale of operations posed a significant challenge.
Migrating the simulation platform to the cloud: From private to hybrid cloud
After two years of operating as a standalone system, growing data volumes and operational complexities required a migration to a Kubernetes architecture. The team adopted a Software-as-a-Service (SaaS) model, deploying all components in a K8s environment, which raised the challenge of selecting suitable storage for K8s.
Storage selection for K8s: JuiceFS vs. CephFS vs. Longhorn
Performance was not the primary criterion for storage selection. Instead, the focus was on enabling cross-cloud networking. A brief evaluation revealed:
- Longhorn supports file sharing only within a single cluster. This requires complex networking configurations for multi-cloud clusters, increasing operational costs.
- CephFS posed high maintenance requirements, unsuitable for a small team.
| Feature | JuiceFS | CephFS | Longhorn |
|---|---|---|---|
| Official Helm chart | ✓ | ✓ | ✓ |
| Mounting anywhere | ✓ | ✓ | ✗ |
| Post-failure maintenance cost | Medium | High | Medium |
| Data compression | ✓ | ✓ | Backup-only compression |
Ultimately, we chose JuiceFS for the following reasons:
- It’s easy to operate and maintain, suitable for a small team.
- It’s beginner-friendly. JuiceFS’ plug-and-play design makes it easy to use without significant operational risks.
- Since deployment, it has run without any incidents. This shows its reliability.
JuiceFS usage highlights:
- Over the past six months, the system managed approximately 11 million files.
- We perform data cleaning every six months to delete unnecessary data, ensuring that the total data volume does not continue to grow.
- On average, approximately 6.4k files are written daily, with the total number of files reaching about 60,000 per day. File sizes range from 5 KB to 100 KB.
- Daily data writes amount to approximately 5 GB, peaking at 8 GB.
- Current concurrent write capacity supports 50 streams, with plans to expand further.
- We plan to gradually scale the concurrent write capacity to 50.
Building the simulation platform in a private cloud
In mid-2023, we began to deploy the simulation platform in a K8s environment. As the system scaled to 1,000 robots, Python’s I/O performance became a bottleneck. Switching to Go significantly improved I/O efficiency, enabling a single instance to support over 10,000 concurrent robots.
The system is characterized by high-concurrency writes of small files, with the current concurrency level at 50. This effectively meets our requirements.
Recently, we transitioned our system from a monolithic architecture to a microservices architecture. This change resolved issues of code entanglement and coupling within the team, ensuring the independence of code between services. The result has been improved maintainability and scalability of the system.
We also implemented a storage-compute separation strategy. Simulation nodes write small files of simulation process data using JuiceFS and rename them to .fin files upon completion. Analysis nodes monitor for .fin files in real time and begin computations immediately. This separation of simulation and analysis prevents CPU contention, ensuring accurate simulation processes.
Hybrid cloud SaaS simulation services
In our private cloud K8s environment, we manage numerous components, such as MySQL and Alibaba Cloud's OSS. To address resource and focus challenges, we began transitioning to a hybrid cloud SaaS solution in January 2024, migrating storage services to Alibaba Cloud.
For small teams, leveraging public cloud services, particularly for storage, is highly recommended when possible. Data security is a fundamental requirement, and public cloud providers typically offer robust solutions.
We adopted OSS and MySQL services for data sharing across two clusters. This setup has improved data processing efficiency while providing cost and flexibility benefits. For example, when local data center resources are insufficient, JuiceFS’ cross-cloud storage capabilities allow seamless scaling by renting machines from any cloud provider. This reduces costs and enhances elasticity.
Lessons learned using JuiceFS
Overly large default cache leading to Pod evictions
The default cache size is set to 100 GB, while standard Alibaba Cloud servers typically have only 20 GB of disk space. This mismatch caused Pods to be evicted due to excessive cache demands exceeding available disk space.
Bucket configuration issues in hybrid cloud scenarios
When enabling cross-cloud functionality, despite official recommendations to use intranet addresses, our experience with the Container Storage Interface (CSI) suggests using external addresses instead. During the initial format Pod operation, configuration parameters are written to the database. If other nodes rely on this database configuration without explicitly specifying a bucket, using intranet addresses can cause failures when accessed externally.
Discrepancy between object storage space usage and actual data
Although we had 6 TB of storage space under our Alibaba Cloud account, the actual data stored was only about 1.27 TB. Object storage usage significantly increased, likely due to a lack of automated garbage collection (GC). We had to perform manual GC regularly to reduce unnecessary storage overhead.
What’s next
Our future plans include enabling elastic scaling in the cloud, adopting a hybrid platform strategy, and introducing a high-speed service version. Currently, our high-efficiency simulations in machine learning have achieved a 100x simulation speedup.
To further enhance efficiency, we aim to establish comprehensive closed-loop system management. With the large volumes of data generated by our simulation systems, we plan to harness this data for machine learning training to optimize the system. This approach will maximize data utilization, significantly enhancing system intelligence and automation.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and community on Slack.