















Founded in 2018, Metabit Trading is a technology-driven quantitative investment firm harnessing the power of AI and machine learning. In April 2023, our assets under management reached about USD 1.4 billion. We place a high priority on building foundational infrastructure and have a strong research infrastructure team. The team uses cloud computing to overcome the limitations of standalone development, aiming to develop a more efficient and secure toolchain.
Driven by the unique demands of quantitative research, we switched to cloud-native storage. After our evaluation, we chose JuiceFS, a distributed file system, for its POSIX compatibility, cost-effectiveness, and high performance. It’s an ideal fit for our diverse and bursty compute tasks. The deployment of JuiceFS has enhanced our ability to handle large-scale data processing, optimize storage costs, and protect intellectual property (IP) in a highly dynamic research environment.
In this article, we’ll deep dive into characteristics of quantitative research, storage requirements of our quantitative platform, and our storage solution selection.
What quantitative trading research does
As a newly established quantitative trading firm, our infrastructure storage platform selection was influenced by two factors:
- Our preference for modern technology stacks, given our lack of historical technical baggage
- The specific characteristics of machine learning scenarios in quantitative trading analytics
The diagram below shows the research model most closely associated with machine learning in our scenario:
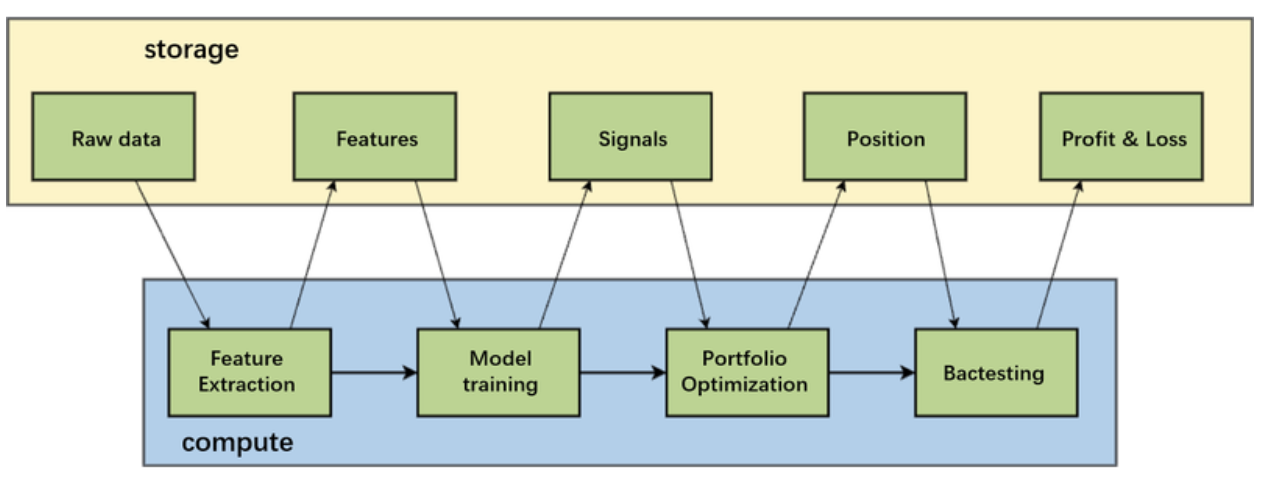
Initially, feature extraction must be performed on the raw data before model training. Financial data has a particularly low signal-to-noise ratio, and using raw data directly for training would result in a very noisy model.
Raw data includes market data such as stock prices and trading volumes, as well as non-quantitative data like research reports, financial reports, news, social media, and other unstructured data. Researchers extract features from this data through various transformations and then train AI models.
Model training yields models and signals. Signals predict future price trends, and their strength indicates the strategic orientation. Quantitative researchers use this information to optimize portfolios, forming real-time trading positions. This process also involves horizontal dimension information (stocks) for risk control, such as avoiding excessive positions in a particular sector. After forming a position strategy, researchers simulate orders to understand the strategy’s performance through the resulting profit and loss information.
Characteristics of quantitative research
Bursty tasks: high elasticity
Quantitative research generates a lot of bursty tasks due to researchers validating their ideas through experiments. As new ideas emerge, the computing platform generates numerous bursty tasks. This requires high elasticity in compute.
Diverse research tasks: flexibility
The entire process includes a wide variety of compute tasks. For example:
- Feature extraction: Computations on time-series data
- Model training: Classical machine learning scenario
- Portfolio optimization: Tasks involving optimization problems
- Trading strategy backtesting: Simulating strategy performance with historical data
The diversity of tasks demands varied compute requirements.
Protecting research content: modularity and isolation
Quantitative research content is critical IP. To protect it, the research platform abstracts each strategy segment into modules with standardized inputs, outputs, and evaluation methods. For example, model research involves standardized feature values as inputs and signals and models as outputs. This modular isolation effectively safeguards IP. The storage platform must be designed to accommodate this modularity.
Data characteristics of quantitative research
The input for many tasks comes from the same data source. For example, as mentioned above, quantitative researchers need to perform extensive backtesting on historical strategies. They test the same positions with different parameters to observe their performance. Feature extraction often involves combining basic and new features, with much of the data coming from the same source.
Take raw data of 100 TB as an example. In the era of big data, this is not a particularly large amount of data. However, when a large number of compute tasks simultaneously access this data, it imposes specific requirements on data storage.
In addition, the quantitative research process involves many sudden tasks. The research team wants to store the results of these tasks. This generates a large amount of archive data, although the access frequency of this data is low.
Characteristics of quantitative research compute tasks
Based on the above characteristics, it’s difficult to meet our compute needs using traditional data centers. Therefore, moving compute tasks to the cloud is a suitable technical choice for us.
High frequency of burst tasks and high elasticity
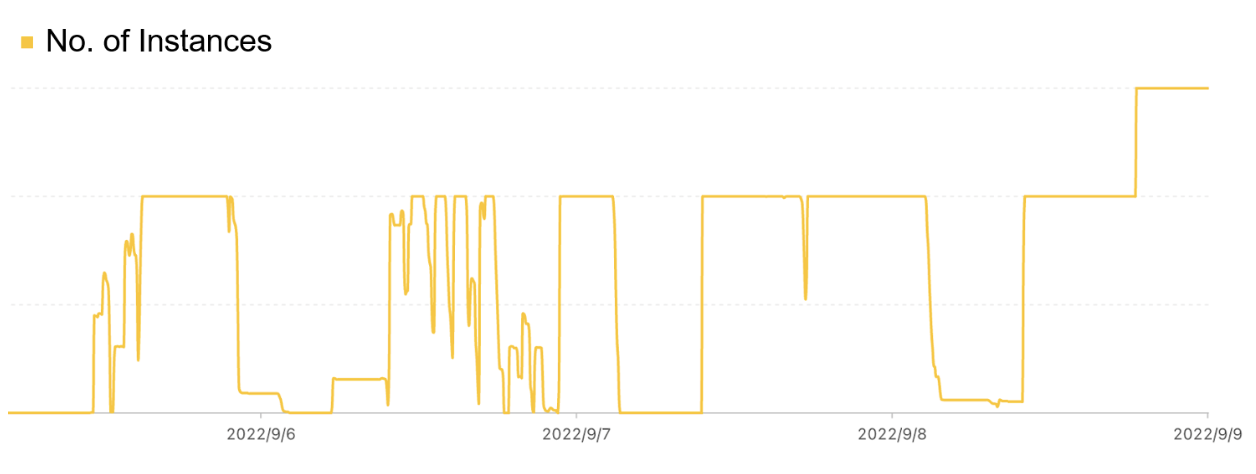
The figure below shows the running instances of one of our clusters. We can see there were multiple periods where the entire cluster's instances were fully utilized. At the same time, there were moments when the entire cluster scaled down to zero. The compute tasks of a quantitative institution are closely tied to the research progress of its researchers. The peaks and valleys in demand are significant, which is a hallmark of offline research tasks.
Technology development and the challenge of predicting compute needs
Our research methods and compute needs can experience explosive growth. Accurately predicting these changes in compute demand is challenging. In early 2020, both our actual and forecasted usage were quite low. However, when the research team introduced new methods and ideas, there was a sudden, substantial increase in the demand for compute resources. Capacity planning is crucial when setting up traditional data centers, but it becomes particularly tricky under these circumstances.
Modern AI ecosystem built on cloud-native platforms
The modern AI ecosystem is almost entirely built on cloud-native platforms. We’ve tried many innovative technologies, including the popular machine learning operations, to streamline the entire pipeline and build machine learning training pipelines. Many distributed training tasks now support cloud-native development, making it a natural choice for us to move our compute tasks to the cloud.
Quantitative platform storage requirements
Based on the above application and compute needs, our storage platform requirements include:
- Imbalance between compute and storage: As mentioned earlier, compute tasks could surge significantly, reaching very high levels. However, the growth of hot data was not so fast. Therefore, the separation of compute and storage was required.
- High throughput access for hot data: For example, market data requires high throughput access when hundreds of tasks simultaneously access the data.
- Low-cost storage for cold data: Quantitative research generates a large amount of archive data that needs to be stored at a low cost.
- Diverse file types/requirements and POSIX compatibility: We have various compute tasks with diverse file type requirements, such as CSV and Parquet. Some research scenarios also require flexible custom development, making POSIX compatibility a critical consideration when selecting a storage platform.
- IP protection: data sharing and isolation. Our need to protect IP requires isolation in compute tasks and data. At the same time, researchers need easy access to public data like market data.
- AI ecosystem and task scheduling on cloud platforms: This is a basic requirement, so storage also needs good support for Kubernetes.
- Modularity, namely intermediate result storage/transmission: The modularity of compute tasks requires storage and transmission of intermediate results. For example, during feature calculation, large amounts of feature data are generated, which are immediately used by training nodes. We need an intermediate storage medium for caching.
Storage solution selection
Non-POSIX compatible solutions
Initially, we tried many object storage solutions, which were non-POSIX solutions. Object storage offers strong scalability and low cost but has obvious drawbacks. The biggest issue is the lack of POSIX compatibility. The use of object storage differs significantly from file systems, making it difficult and inconvenient for researchers to use directly.
In addition, many cloud providers have request limits on object storage. For example, Alibaba Cloud limits the bandwidth of the entire OSS account. While this is acceptable for typical application scenarios, burst tasks generate significant bandwidth demand in an instant. Therefore, it’s challenging to support these scenarios with just object storage.
Another option was HDFS. However, we didn't test HDFS extensively. Our tech stack did not heavily rely on Hadoop. HDFS does not particularly support AI training products well. Moreover, HDFS lacks full POSIX compatibility, which limits its use in our scenarios.
POSIX-compatible solutions on the cloud
Based on the application characteristics mentioned above, we required strong POSIX compatibility. Since our technology platform is based on the public cloud, we focused on POSIX-compatible cloud solutions.
Cloud providers offer solutions like Alibaba Cloud NAS and AWS EFS. Another category includes Alibaba Cloud Cloud Parallel File Storage (CPFS) and Amazon FSx. The throughput of these file systems is strongly tied to capacity—greater capacity means greater throughput, directly related to NAS storage properties.
Such solutions are not very friendly when dealing with small amounts of hot data and require extra optimization for better performance. In addition, CPFS or Alibaba Cloud's high-speed NAS are good for low-latency reads but have high costs.
Compared with high-performance NAS product costs, JuiceFS' overall cost is much lower, because its underlying storage is object storage. JuiceFS costs include object storage fees, JuiceFS Cloud Service fees, and SSD cache costs. Overall, JuiceFS' total cost is much lower than NAS and other solutions.
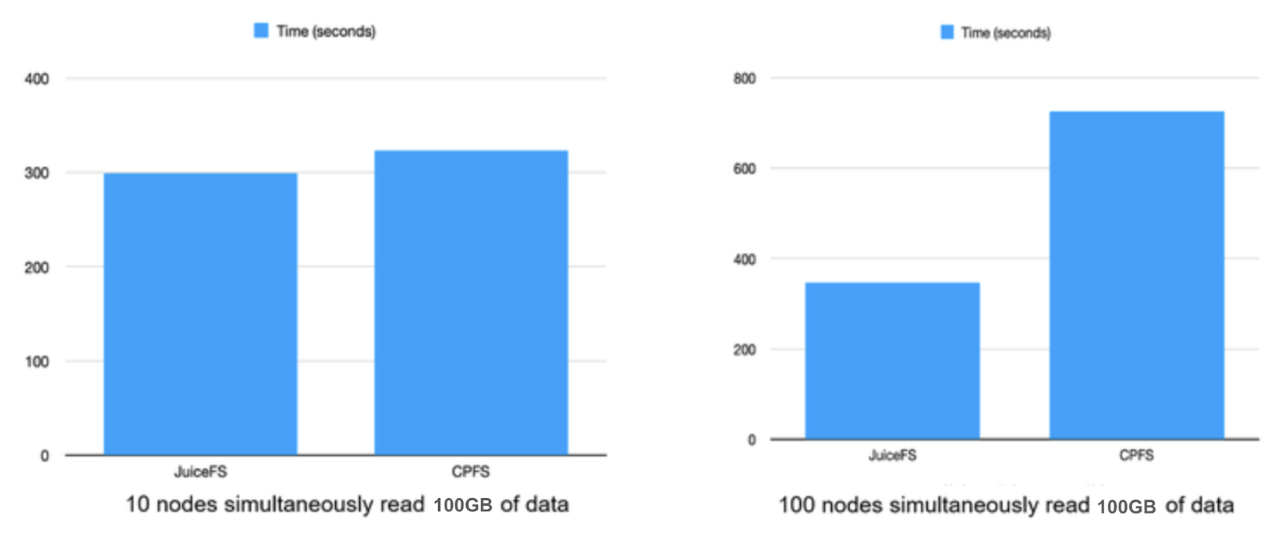
Regarding throughput, early tests showed no significant performance difference between CPFS and JuiceFS, when there were not many nodes. However, as the number of nodes increased, NAS file systems faced bandwidth limitations. This lengthened reading time. In contrast, JuiceFS, with a well-deployed cache cluster, handled this effortlessly with minimal overhead.
Besides cost and throughput, JuiceFS supports the mentioned functionalities well:
- Full POSIX compatibility
- Permission control
- Quality of service
- Kubernetes support
Notably, JuiceFS' cache cluster capability allows flexible cache acceleration. Initially, we used compute nodes for local caching—a common approach. With compute-storage separation, we wanted some data to be localized to compute nodes. JuiceFS supports this well, with features for space occupancy and percentage limits.
We deployed an independent cache cluster to serve hot data, warming up the cache before use. During use, we noticed significant differences in resource utilization across compute clusters. Some high-bandwidth servers were primarily used for single-node computations. This meant their network resources were largely unused. We deployed cache nodes on these servers, using idle network bandwidth. This resulted in a high-bandwidth cache cluster within the same cluster.
JuiceFS in production scenarios
Currently, we use JuiceFS in the following production scenarios:
- File systems for compute tasks, applied to hot data input.
- Log/artifact output.
- Pipeline data transfer: After feature generation, data needs to be transferred to model training. During training, data transfer needs arise, with Fluid + JuiceFS Runtime serving as an intermediate cache cluster.
In the future, we’ll continue exploring cloud-native and AI technologies to develop more efficient, secure toolchains and foundational technology platforms.
If you have any questions for this article, feel free to join JuiceFS discussions on GitHub and their community on Slack.