















“JuiceFS is an outstanding and stable product. Its Community Edition can address most issues, while its Enterprise Edition offers even greater stability and ease of use, effectively tackling more challenging problems in large language model (LLM) scenarios.”—Xiangjun Yang, Head of Zhihu Machine Learning Platform
Zhihu is a leading Quora-type Q&A site and news aggregator in China, with over 100 million monthly active users. The platform's search and recommendation services benefit from advanced AI algorithms. Hundreds of algorithm engineers perform massive data processing and algorithm training tasks based on the data platform and machine learning platform.
To improve system usability and flexibility, we’ve implemented a multi-cloud hybrid deployment architecture. This architecture allows transparent handling of files across different clouds and enables users to interact with files flexibly within containers, without concerning themselves with the specific storage locations of the files.
Facing the demand for multi-cloud hybrid deployment architecture, we introduced JuiceFS Community Edition, an open-source distributed file system, in 2022 to create a distributed file system usable across multiple public clouds. This system meets the performance requirements for large-scale read/write operations and real-time user interactions. For high-performance demand scenarios such as large-scale LLM training, we adopted JuiceFS Enterprise Edition to ensure checkpoint stability and enhance GPU efficiency.
Currently, we’ve stored 3.5 PB of data on JuiceFS Community Edition, primarily for machine learning applications, while we use the Enterprise Edition for tasks with higher performance requirements.
This article will share our experience in building the storage layer in a multi-cloud hybrid deployment architecture, ensuring LLM training stability, and migrating petabyte-scale data across clouds.
Machine learning platform requirements and challenges
Our platform architecture
Our machine learning platform serves hundreds of algorithm engineers from Zhihu and ModelBest, an AI startup. Relying on advanced data processing and machine learning technologies, this platform enables engineers to effectively handle massive data and conduct complex algorithm training and inference tasks.
Application layer: Our mission-critical promotional business covers homepage recommendations, advertisements, and search functions. As a rich text and image ecosystem, we require machine learning support in both visual and natural language processing (NLP) domains. Since last year, there has been a continuous increase in demand for LLMs.
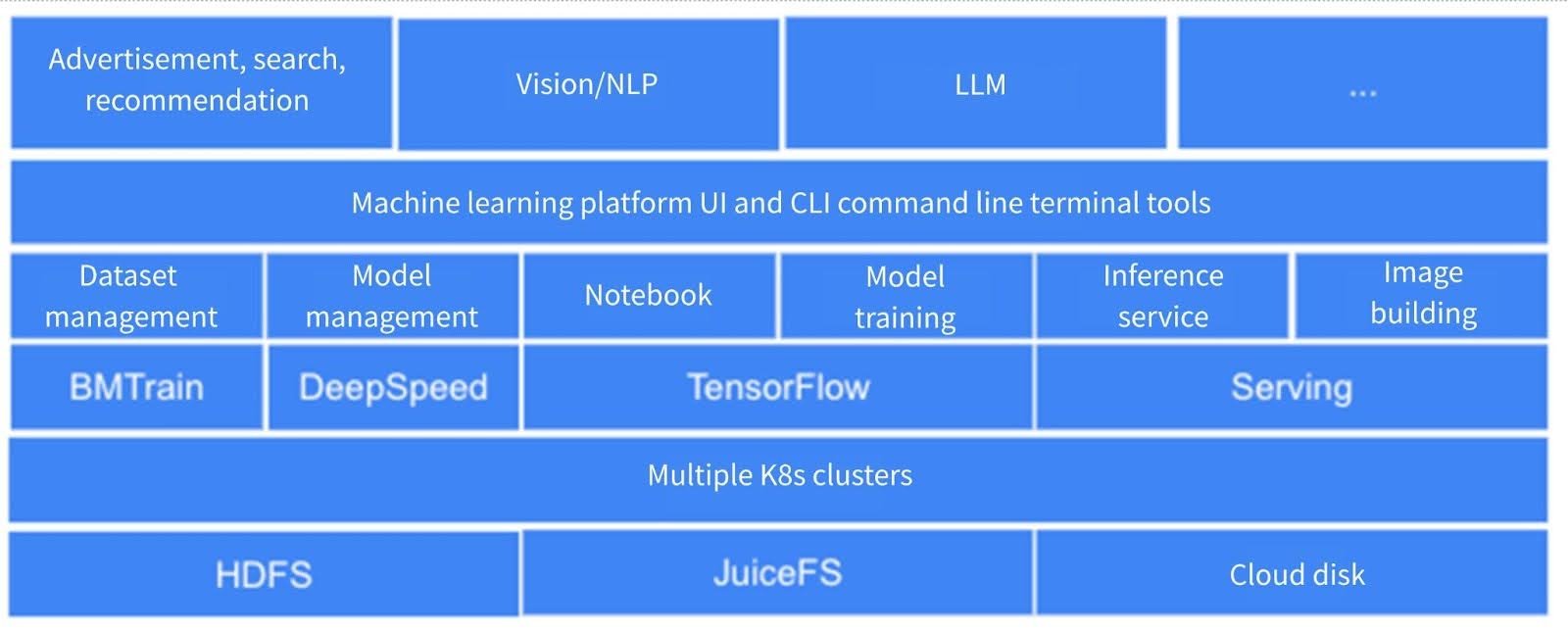
Internal organization of the machine learning platform: Users utilize various functionalities of the machine learning platform through interfaces (UI) and command-line tools. These functional modules cover dataset management, model training, notebooks, inference services, and image building.
We collaborate deeply with ModelBest in developing LLMs. ModelBest also operates the BMB community, which provides the BMTrain training engine specifically designed for LLM training, and some algorithm engineers use DeepSpeed. PyTorch and TensorFlow are extensively used in web search and recommendation scenarios. Currently, various online service components for model inference, including vLLM, NVIDIA Triton, and our independently developed CPM server, are deployed across multiple GPU clusters.
Underlying storage: We adopt HDFS, JuiceFS, and cloud disks as the foundational physical storage solutions, supporting the storage requirements of the entire machine learning platform.
Application requirements
We had the following requirements for our application:
-
POSIX protocol support: During model training, especially when we explored new models using notebooks, we often read and wrote large files, such as reading sample data and writing checkpoints. We usually used various open-source training engines or frameworks to read and write data directly from the file system. This made support for the POSIX protocol critical. This is why although we initially adopted HDFS, we did not continue to iterate on it due to its lack of POSIX protocol support.
To achieve POSIX protocol support, we expected to integrate the file system directly into containers through a simple mounting method, allowing programs to perform file operations via standard Linux I/O interfaces. This ensures not only the consistency of file content across all containers (even under weak consistency conditions) but also meets the requirements for random writes. These are crucial for our application scenarios. Additionally, from a system management perspective, we not only needed to implement quotas and permission controls but also aimed to provide observability metrics for troubleshooting.
-
Scalability: Scalability was a crucial factor in our considerations as the future scaling of LLMs or other potential changes remained unknown.
-
Performance and cost: In the current environment of cost reduction and efficiency enhancement, cost control became a key factor.
-
System management: We hoped that the file system supporting multiple tenants could effectively implement permission and quota management.
Technical challenge: concurrent access across multiple clouds
Because we didn’t have a self-built data center conducting large-scale model training, we had to rely on public cloud GPU resources. However, a single provider often couldn't meet our GPU quota needs, resulting in resource dispersion across multiple platforms. To prevent redundant data copying and address this urgent need, we looked for a file system capable of operating simultaneously across various cloud environments.
The ideal multi-cloud architecture must facilitate unified cluster storage and cross-platform data access and processing. Currently, we’re using resources from four public cloud service providers.
Exploration about JuiceFS
Deployment approach
In our selection process, we sought a solution suitable for cloud-native deployment. In this regard, JuiceFS has demonstrated notable advantages. In addition, we examined some competitors of JuiceFS and found that deployment based on the container storage interface (CSI) were not mature, while JuiceFS implementation was quite good.
System observability
JuiceFS offers a feature-rich internal metrics monitoring dashboard. This simplifies viewing system performance. JuiceFS Community Edition encompasses crucial global statistical indicators, including throughput, I/O operations, and latency. JuiceFS Enterprise Edition provides even more detailed monitoring indicators to enable comprehensive tracking of performance indicators for each cache service and client. This feature holds particular value for troubleshooting and performance monitoring.
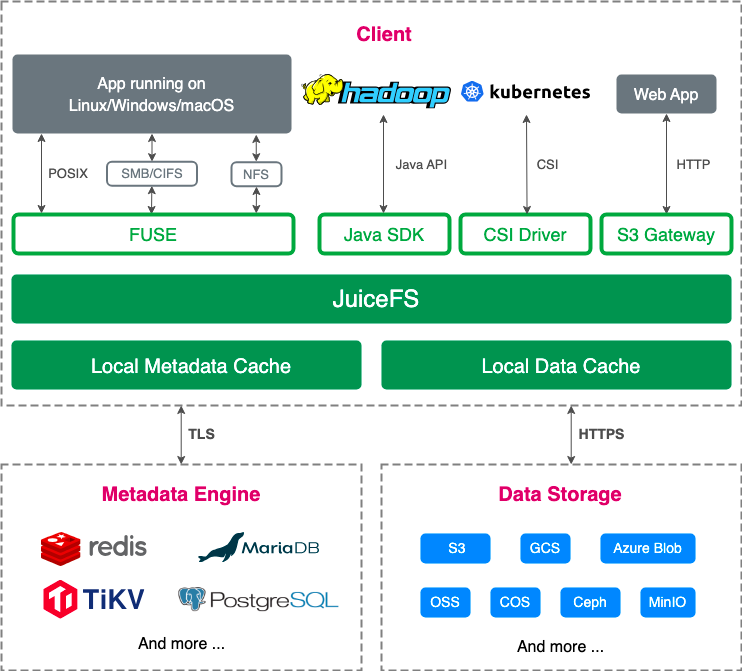
Architecture design for multi-cloud hybrid deployment
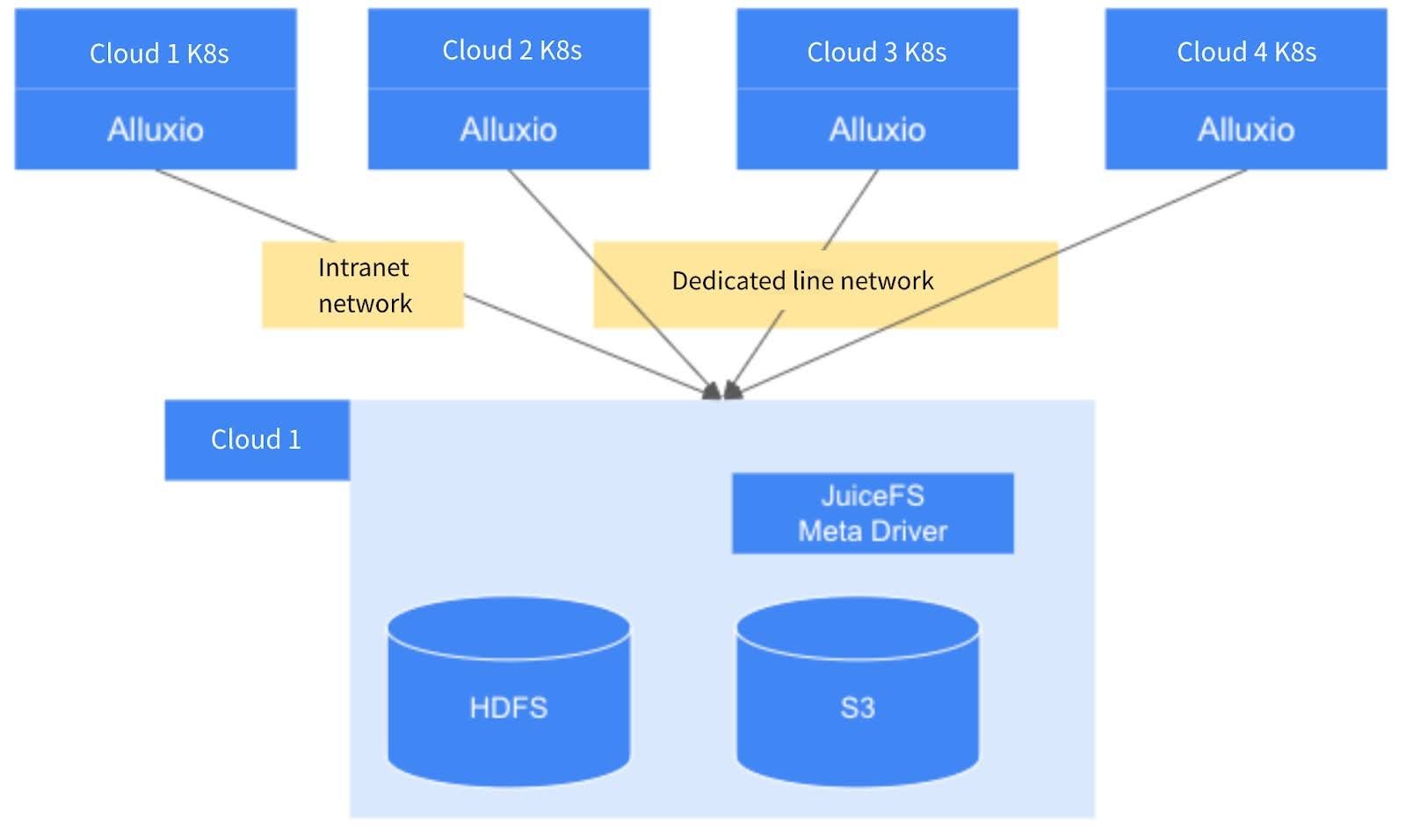
Currently, we manage four different cloud environments, each hosting its Kubernetes cluster. Our data is divided into two parts:
- One is stored in HDFS.
- The other consists of JuiceFS Meta Driver and S3, forming the JuiceFS cluster.
Different clusters can access JuiceFS and HDFS via the network. To optimize access speed, we deploy JuiceFS and HDFS within the same cloud environment to implement internal network access, while other cloud environments connect via dedicated lines. This deployment strategy has a certain impact on performance when the cloud environment is deployed across geographical regions. For example, if the first three clouds are deployed in northern regions, performance tends to be better. Conversely, deploying the fourth cloud in the southwest region may lead to higher latency.
The clusters cater to two main requirements:
- Offline training tasks
- Tasks equipped with interactive notebooks
These tasks are directly mounted via JuiceFS CSI Driver in Kubernetes. This ensures an efficient and elegant process. Although Alluxio utilizes local storage, which is straightforward, it is feasible. The key consideration lies in disaster recovery capability—ensuring stable operation of processes on bare metal servers. This is critically important. Poor stability may result in service unavailability.
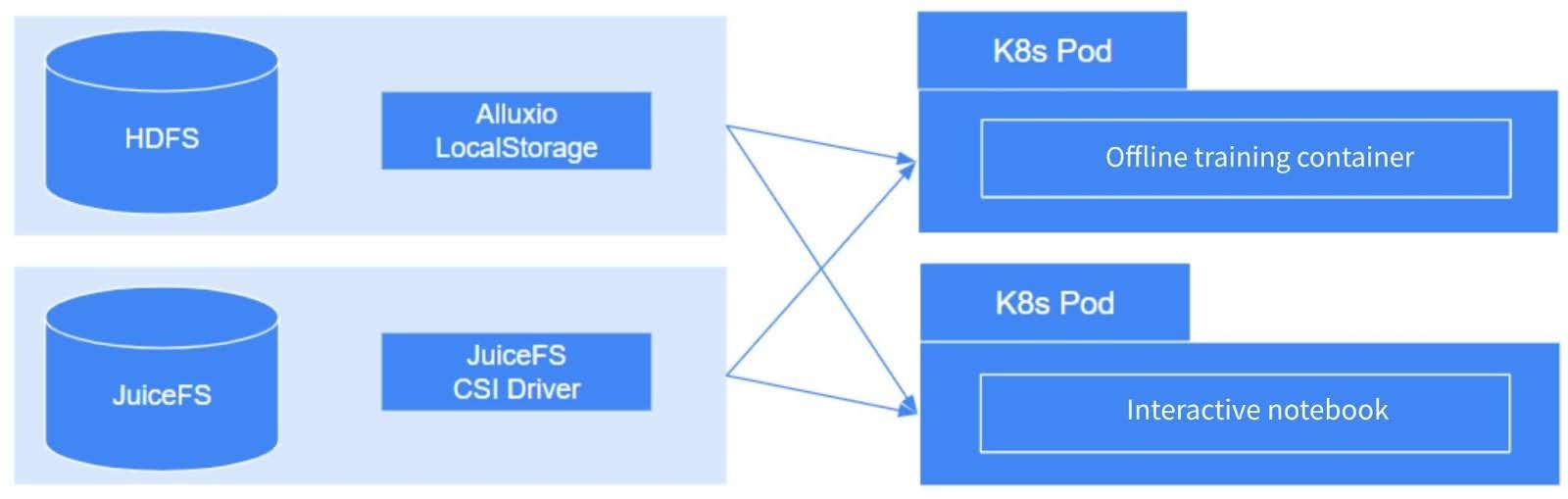
HDFS mainly stores sample data. Algorithm engineers and data engineers generally complete data processing and preparation on the big data platform and then upload it to HDFS. Alluxio manages the HDFS data. This data is read-only during model training and interactive access.
JuiceFS is used as the output directory for saving checkpoints. It provides a unified storage solution for interactive notebooks. Temporary content in notebooks, such as model downloads, software installations, and compilation results, are all stored in JuiceFS. Since notebooks have state, any failed restart of the container may result in the loss of a large amount of state information. By mounting JuiceFS, we’re able to preserve a portion of the storage. This is more user-friendly for users with interactive applications.
Challenges in training LLMs
Checkpoint stalling
Our cluster runs various tasks simultaneously. These tasks typically generate checkpoint data exceeding 100 GB, requiring large-scale model loading.
Initially, we employed JuiceFS Community Edition to handle large-scale file reads and writes. However, we observed a sharp increase in CPU usage during write operations, as shown in the figure below. This caused the cluster to become unavailable. This issue resulted in severe system latency for our team using notebooks and executing other tasks. It significantly impacted the overall efficiency of the cluster.
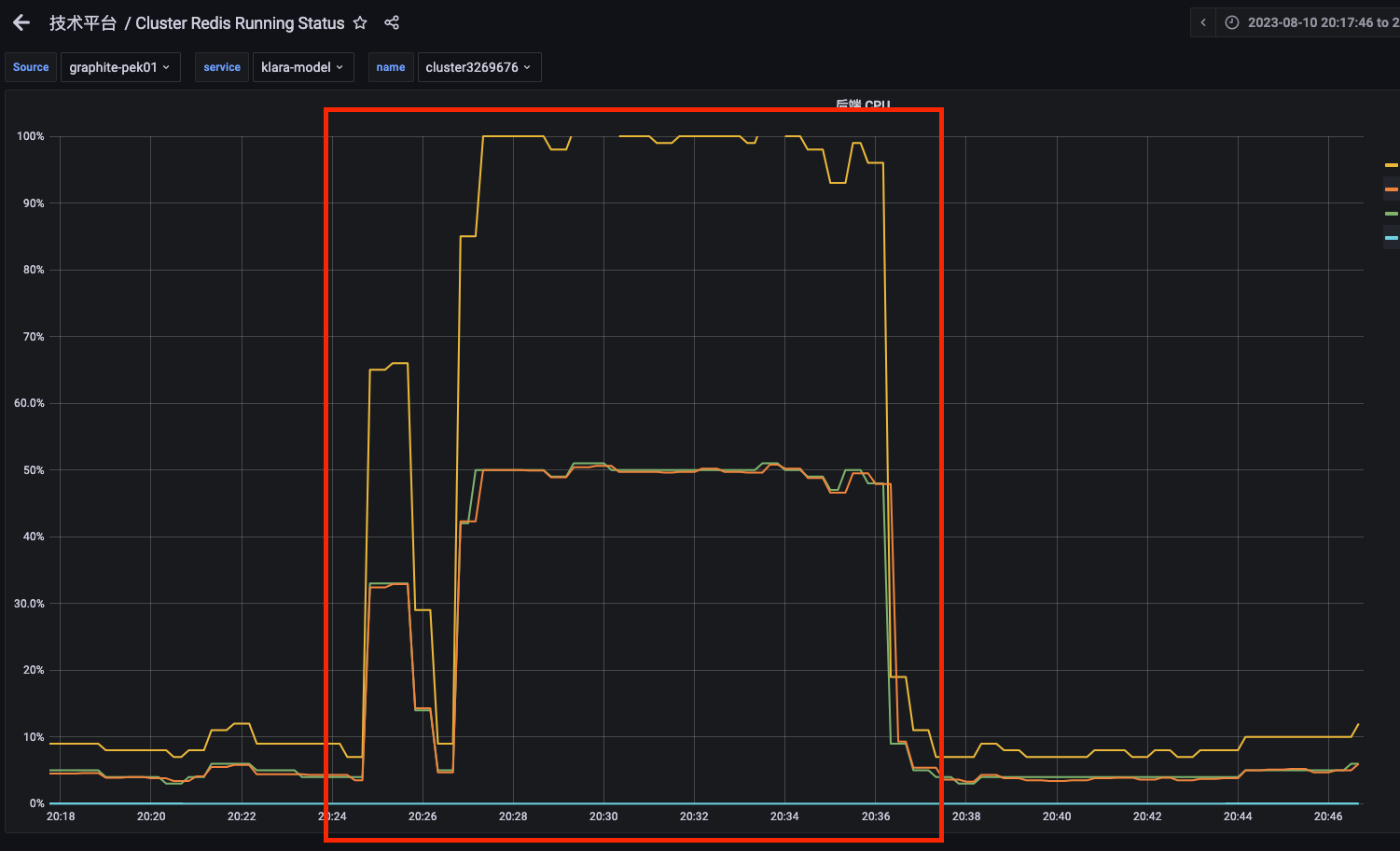
When we further troubleshoot cluster performance issues, we discovered that CPU resource exhaustion was primarily due to the complete occupation of CPU resources by Redis. While reviewing Redis logs, we noticed a specific audit notification indicating an automatic scan operation would be triggered after file checking. This scan would target all files exceeding 6.4 GB, regardless of whether they were set through manual operations or API calls. In Redis' single-threaded mode, this scan would block all other requests when CPU resources were already at their limit.
Stability issue cause analysis and solutions
When troubleshooting the system slowdown, we identified that the system latency was caused by the prolonged execution time of the setattr operation, which lasted about 577 seconds. When reviewing JuiceFS code, we noticed that JuiceFS printed relevant information for each operation. This information helped us quickly locate the problematic operation and its approximate duration. However, there was a minor flaw in the logs: it only displayed the file's ID rather than its path. Although this added complexity to the problem-solving process, we successfully found the root cause of the issue.
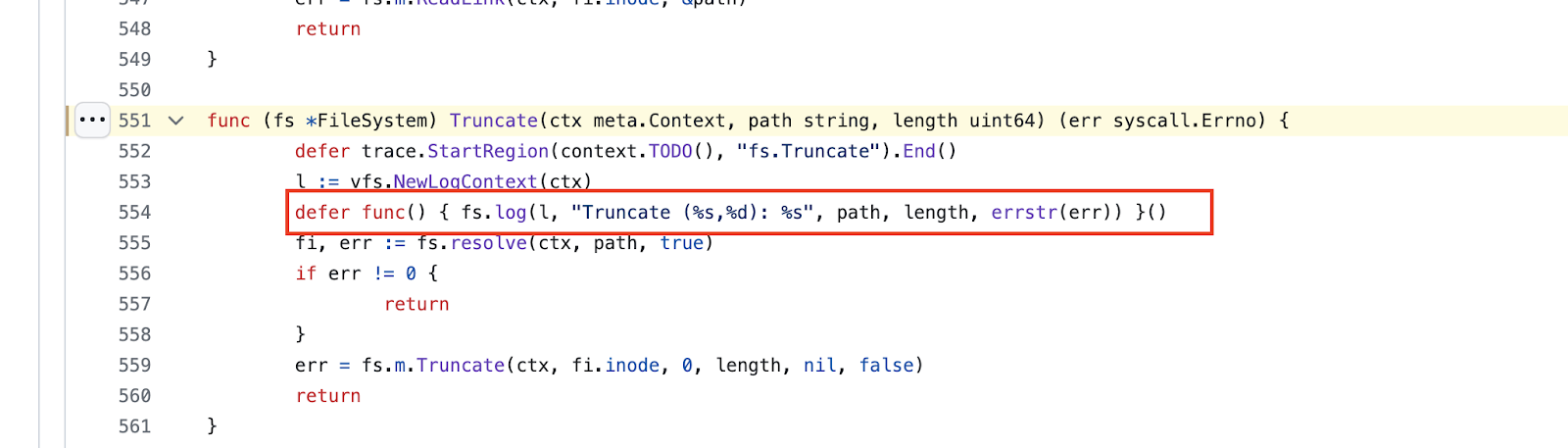
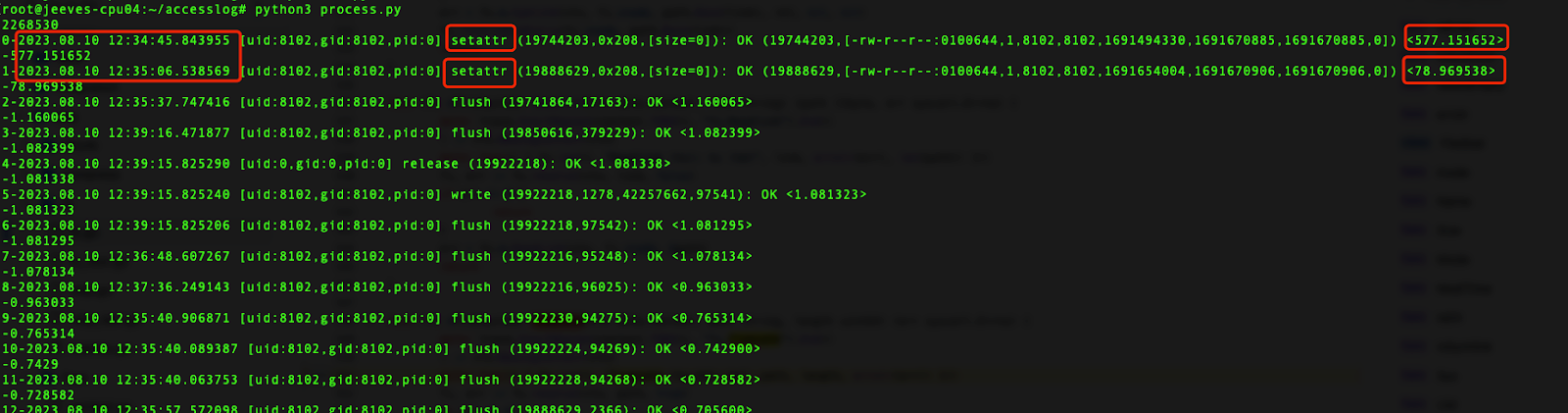
After conducting a deeper analysis of the root cause, we also examined the PyTorch source code. We found that when PyTorch saved data, each Tensor was recorded incrementally to a zip_file. During this incremental write process, modifications to file sizes triggered a file truncate operation. This requirement to reset file sizes activated the previous scan operation, resulting in it lasting a considerable amount of time.
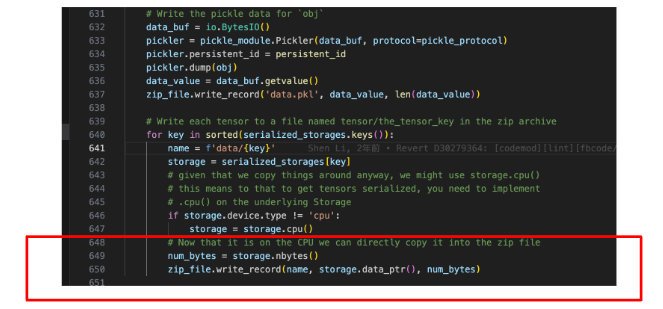
Furthermore, we learned that JuiceFS split files into fixed-sized chunks. Each chunk consisted of one or more slices. The length of each slice was not always the same. This implied that we could not calculate the total size of a file simply by summing the lengths of slices. Therefore, when we added or modified content at the end of a file, we needed to recalculate the overall file size. This involved traversing all the content of the file.
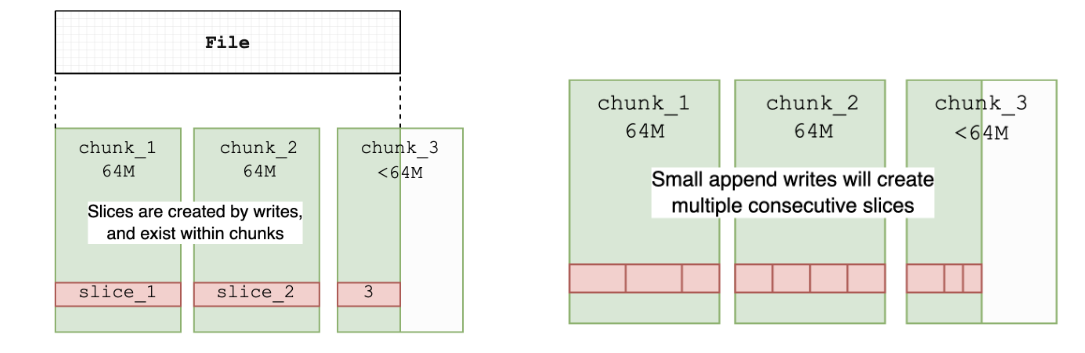
Faced with this challenge, we considered two solutions:
- Avoiding incremental writes to large files by not using PyTorch's
save_checkpointinterface. Instead, data was first written to local files and then transferred to JuiceFS using amoveoperation. This ensured data continuity and integrity. - Adopting JuiceFS Enterprise Edition to address this issue thoroughly. The metadata engine performance of JuiceFS Enterprise Edition was superior, enabling more effective management of large-scale file operations.
We ultimately adopted JuiceFS Enterprise Edition. The primary consideration was that we could not entirely avoid potential issues, nor could we enforce everyone to adhere to rules avoiding incremental writes to checkpoints. On one hand, due to the involvement of numerous participants, achieving unanimous action across all members was challenging. On the other hand, with the continuous iteration and updates of community code, much of our code was based on open-source projects for subsequent prototype validations. In such circumstances, modifying others' code was not a feasible long-term strategy.
JuiceFS Enterprise Edition’s metadata service performance
For metadata performance, our primary concern is its scalability in parallelism. The following two figures show the performance of rename and delete operations in JuiceFS Enterprise Edition, indicating the transaction processing rate (TPS) as the number of concurrent threads increases. These figures compared OSS, HDFS, and JuiceFS.
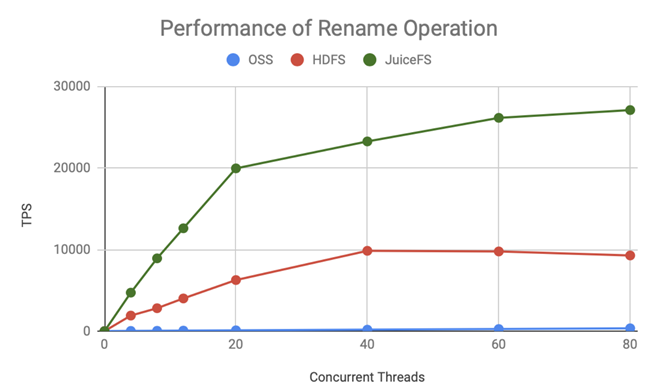
JuiceFS demonstrated a stable linear increase in TPS as the number of concurrent threads increased during rename operations, far surpassing HDFS and OSS.
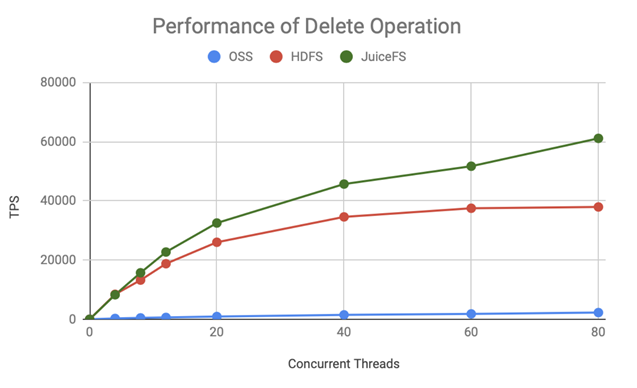
JuiceFS also exhibited good performance during delete operations, with its performance significantly outperforming that of HDFS and OSS.
Based on this data, we opted for JuiceFS Enterprise Edition due to its superior scalability in handling parallel operations. Although the performance report did not provide data on truncate operations, which were of utmost importance to us, we could infer from these graphs that JuiceFS effectively scaled its transaction processing capability with increasing concurrency. It demonstrated stronger performance compared to the Community Edition. Therefore, we chose the Enterprise Edition to address the performance issues encountered during LLM training.
Challenges of petabyte-scale data migration across clouds
As the demand for GPUs increased, we gradually introduced new data centers. Due to changes in the primary data center, we needed to migrate storage from smaller data centers to larger storage systems.
JuiceFS Community Edition
The migration process mainly involved two stages: full migration and incremental migration. During the full migration stage, we primarily used offline backup methods to transfer data from S3 to the new storage system. It was essential to ensure dedicated bandwidth to avoid disrupting normal operations during data migration.
In addition, we needed to consider bandwidth limitations between the two cloud platforms, as these constraints might affect the overall stability of the cluster. Therefore, it was necessary to confirm available bandwidth in advance. Furthermore, S3 gateways might impose restrictions based on accounts, IPs, or other conditions. Therefore, we needed communication with stakeholders to secure the largest possible bandwidth quota for smooth offline backup operations. Base on past experiences, about 4 PB of data might take about a week to back up.
JuiceFS Enterprise Edition
The migration process in the Enterprise Edition is similar to the previous method, but with a significant difference in the dual-write functionality. After completing the initial incremental migration, we used this feature for data synchronization. At this point, we must pause all file access, restart tasks and notebooks, and configure the dual-write setting. During the dual-write phase, the system continued to use the original storage, with the impact limited to a few minutes on application operations. The new storage was enabled later, and we completed this process in about two days.
Next, we switched components in dual-write and redirected application pod nodes to the new cluster. This switch required a short service interruption, and the impact on the application was in minutes.
We found that incremental migration was fast. Actual test results indicated it only took a few minutes. This incremental migration could be performed after starting tasks and notebooks, without affecting application operations. However, it’s essential to note that restarting may not be acceptable in many critical tasks. Therefore, the timing of restarts typically depends not on the completion of migration but on the application’s ability to tolerate interruptions.
Although the overall migration time did not shorten, JuiceFS Enterprise Edition's impact on application operations was less disruptive. Especially within an enterprise, if operations affect the entire platform, the advantages of the Enterprise Edition become more obvious.
Lessons learned for cross-cloud data migration
- Full data copy: Critical factors to consider include the degree of parallelism in data copying, public network bandwidth, and potential traffic restrictions on both S3 gateways. When conducting incremental data copying, the focus is on the duration of offline tasks. This aims for a one-time completion without the need for repetition.
- Incremental data copy: The primary time-consuming aspect occurs during the scanning of S3 data rather than the actual copying of data. If specific directories where users write data can be known in advance, the time required for incremental copying will be significantly reduced. In addition, JuiceFS' synchronization tools can achieve precise synchronization of specified file directories.
- Process optimization: Ideally, metadata copying should be performed after the network is disconnected. In our initial attempt at synchronization using the Community Edition, we did not disconnect the network beforehand, leading to data loss issues after metadata synchronization. JuiceFS emphasizes data integrity, with metadata serving as the accurate basis. Therefore, during migration with the Community Edition, we must ensure that metadata synchronization begins only after application operations have completely stopped.
-
Comparison of Community Edition and Enterprise Edition migration solutions: During the file system migration process, we conducted migrations for both JuiceFS Community Edition and Enterprise Edition. The Community Edition employed two configurations with Redis and MySQL as metadata managers. After a comprehensive comparison, we found that the Community Edition had a longer impact on application time during migration and was highly susceptible to the influence of incremental data volume.
In contrast, migration with the Enterprise Edition maintained the continuous availability of JuiceFS services, although it required three restarts for application. Proper selection of restart timing is crucial. If handled correctly, the impact on application can be minimized.
Conclusion
JuiceFS offers full POSIX compatibility, supports diverse data writing requirements, achieves real-time interactive file read/write performance, seamlessly integrates with mainstream Kubernetes clusters, and provides comprehensive cloud application documentation and deployment cases.
Currently, we’ve stored 3.5 PB of data with JuiceFS Community Edition for machine learning applications. For tasks requiring higher performance, such as checkpoint writing of LLM training, we use JuiceFS Enterprise Edition. Leveraging JuiceFS ensures flexibility and efficiency in data operations across multiple public clouds.
If you have any questions, feel free to join JuiceFS discussions on GitHub and their community on Slack.