















BioMap specializes in AI-driven life sciences technologies. The company has developed xTrimo V3, the world's largest AI foundation model for life sciences, with 210 billion parameters, covering proteins, DNA, RNA, and other key biological domains.
As data volumes in life sciences grow exponentially, storage costs have become a major challenge for us. To optimize costs and efficiency, we evaluated multiple storage solutions, including Lustre, Alluxio, and JuiceFS. After assessing factors such as cost, performance, and operational complexity, we chose JuiceFS.
Currently, JuiceFS supports fine-tuning and inference workloads, managing billions of small files while meeting performance demands. Compared to the previous architecture, our storage costs have been reduced by 90%.
In this article, we’ll share our storage challenges, why we chose JuiceFS over Lustre and Alluxio, and how we use it in different scenarios.
Storage challenges in life sciences
The era of large AI models has revolutionized life sciences. For example, in drug discovery, traditional methods rely on extensive experimental screening. This is costly and time-consuming. AI models like xTrimo accelerate candidate molecule screening, significantly improving efficiency.
However, large models depend on computing power, algorithms, and data. Storage, as the foundation, plays a critical role in performance. With the explosive growth of life sciences data, managing massive datasets presents new challenges:
- Backup reliability issues: At TB or PB scale (with about 1 billion small files), backups often fail. Even when successful, they take up to a month. Lost files are nearly impossible to recover.
- High storage costs: Existing systems lack intelligent cold/hot data tiering. This forces all data (including rarely accessed cold data) to be stored in expensive file storage rather than low-cost object storage. Traditional cloud storage solutions incur substantial costs, straining the budgets of scaling enterprises.
Storage selection: Lustre vs. Alluxio vs. JuiceFS
Our primary objective was to optimize costs by significantly reducing storage expenses while maintaining required throughput and latency service levels.
Our secondary priorities included:
- Ensuring robust data safety and read/write performance to guarantee data integrity and availability.
- Streamlining deployment and maintenance processes to accommodate our small operations team, eliminating unnecessary system optimization complexity.
Based on these requirements, we conducted a comprehensive analysis of Lustre, Alluxio, and JuiceFS.
-
Lustre builds storage clusters using local compute resources (such as SSDs) across multiple nodes to achieve large-scale capacity. However, this architecture doesn't natively support object storage backends, preventing it from using object storage's cost-efficiency and scalability advantages.
-
Alluxio primarily serves as a caching layer that consolidates data from multiple file systems into a unified access point. However, it doesn't fundamentally resolve our core challenges of high storage costs and inefficient hot/cold data tiering. Therefore, it is unsuitable as our primary solution.
-
We ultimately selected JuiceFS for three key advantages:
- Active community support: With its vibrant open-source community, JuiceFS provides timely technical support and continuous feature updates. This ensures long-term system stability and reliability.
- Native object storage support: JuiceFS' built-in object storage support fully leverages the cost-efficiency and high scalability of object storage. This delivers substantial reductions in our overall storage expenditures.
- Operational efficiency: JuiceFS offers easy deployment and maintenance workflows, significantly reducing our operational burden.
| Comparison basis | Lustre | JuiceFS | Alluxio |
|---|---|---|---|
| Type | Parallel distributed file system | Cloud-native distributed file system | Memory-accelerated virtual file system |
| Design goal | High performance computing (HPC) | Cloud storage + compatibility | Data locality acceleration + cross-cloud abstraction |
| Key strength | Ultra-low latency, high bandwidth | POSIX compliance + elastic scaling | Cache acceleration + unified view across multiple backends |
| Architecture | Decoupled metadata (MDS) and data (OSS) | Metadata service + object storage backend | Tiered cache (memory/SSD) + storage proxy |
| Data persistence | Self-managed storage clusters | Relies on object storage (S3/OSS) | Depends on backend storage (HDFS/S3) |
| Consistency model | Strong consistency | Strong consistency | Configurable consistency (strong or eventual) |
To validate JuiceFS’ real-world performance, we conducted comprehensive tests and found JuiceFS had these capabilities:
- Seamless Kubernetes integration via CSI Driver
- Demonstrated good stability
- Simplified maintenance and deployment workflows
The performance testing outcomes also aligned with our expectations. Consequently, we migrated from an object storage service to JuiceFS. Despite the substantial scale and complexity of this migration task, JuiceFS’ demonstrated benefits—including cost optimization, performance gains, and operational stability—make this transition a strategic priority.
The JuiceFS-based storage architecture reduced costs by 90%
The Kubernetes-based platform initially used Network File System (NFS) backed by SSD arrays as its underlying storage, and the overall usage costs were nearly 10 times that of object storage. After adopting JuiceFS, data is now persisted to public cloud object storage (such as S3 and OSS), while the JuiceFS cluster itself incurs minimal overhead—almost negligible. This architectural transformation successfully replaced the SSD-based solution with object storage, reducing storage costs by over 90%.
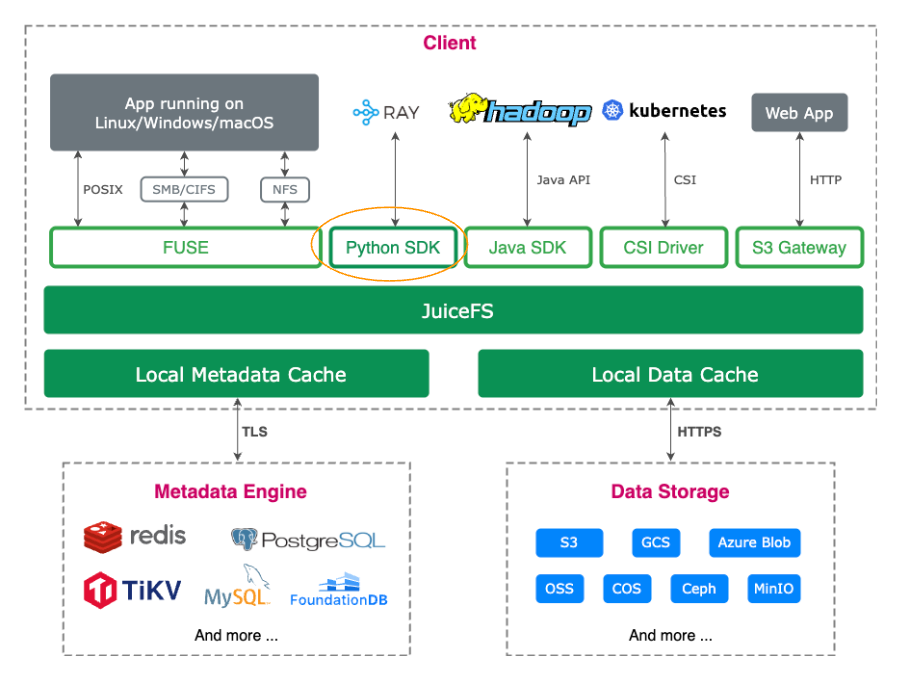
JuiceFS employs a decoupled architecture for data and metadata:
- File data is sliced and stored in object storage.
- Metadata can be stored in various databases (such as Redis, MySQL, TiKV, and SQLite), allowing users to select the optimal engine based on performance and use-case requirements.
Initially, we used MySQL as the metadata engine. However, when the file count exceeded 100 million, its performance degraded significantly. Finally, we migrated to TiKV. Currently, our platform uses PB-level storage and contains billions of files.
As mentioned earlier, we previously encountered issues with insufficient backup reliability. Currently, we’ve achieved stable metadata backups through JuiceFS' metadata backup mechanism. In addition, to prevent accidental data deletion, we’ve further enhanced data safety and recoverability by using JuiceFS' trash feature.
How we use JuiceFS
Data migration tools
During migration, we initially tried to develop multi-process/multi-threaded Python scripts to accelerate data synchronization but encountered numerous challenges. Later, we discovered JuiceFS' built-in juicefs sync command. It effectively resolved synchronization issues and significantly improved migration efficiency.
Storage access optimization
We initially adopted JuiceFS CSI for Kubernetes integration due to its:
- Cloud-native compatibility
- Simplified maintenance
- Built-in monitoring dashboard support
- Easy deployment via YAML
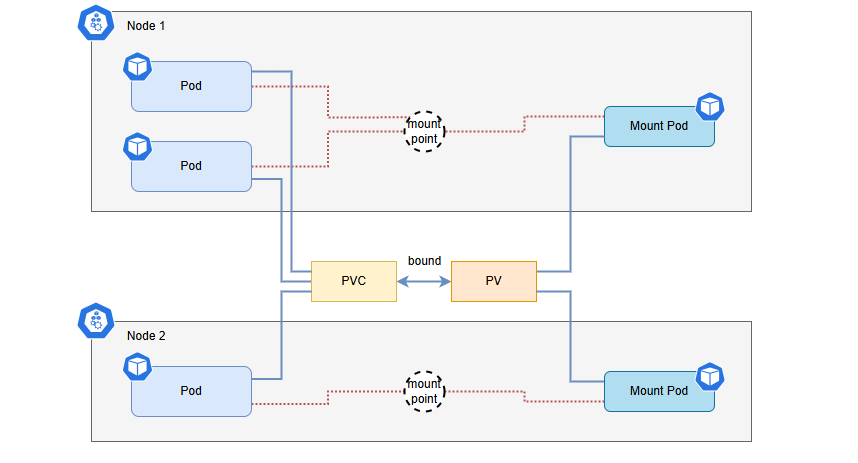
However, in practical applications, we encountered several issues:
- Shared Mount Pod configuration issues: Due to the limited number of Pods per node on the platform, we wanted all users to share a single Mount Pod. Although this could be achieved by configuring the same
volumeHandlefor PVCs generated by different users on the same node, this method increased system complexity and management difficulty. - Mount Pod pre-deployment and update issues: When using the default CSI approach, Mount Pods could not start properly under resource constraints. This may lead to issues with application Pods. As a result, we needed to pre-deploy Mount Pods and set the
juicefs-delete-delayparameter to “525600h” to prevent Mount Pods from being released after application Pods were terminated. However, updating Mount Pod resources required coordination across teams to clean up application Pods, delete old Mount Pods, and start new ones. This made the process cumbersome and error-prone. - Stability issues: Due to excessively large local caches and high page cache usage, Mount Pods frequently encountered out-of-memory (OOM) errors. This affected read/write operations within application Pods, disrupting normal application operations.
Given the issues with the CSI approach, we decided to switch to the HostPath mounting method. This involved mounting JuiceFS to each node, allowing application Pods to access the mounted file system via HostPath. While this method proved more stable than CSI, it also had drawbacks, such as more complex deployment and difficulty in management and upgrade. To address these challenges, we used automation tools for batch deployment and management. This improved operational efficiency.
Editor’s Note
For JuiceFS CSI, we recommend using dynamic provisioning and sharing a single Mount Pod by assigning the same StorageClass. This preserves full functionality and simplifies management. We do not recommend the approach mentioned above of sharing by reusing the same volumeHandle; it can break several advanced CSI features (e.g., rolling upgrades). JuiceFS CSI supports rolling upgrades of the Mount Pod without restarting application Pods, further improving availability and operational efficiency.
If increased kernel page cache usage causes the Mount Pod to run out of memory (OOM), enable the client option to proactively drop page cache (evict immediately after reads/writes) to reduce memory consumption. For details, see the docs:https://juicefs.com/docs/csi/guide/cache/#clean-pagecache
File copy performance optimization
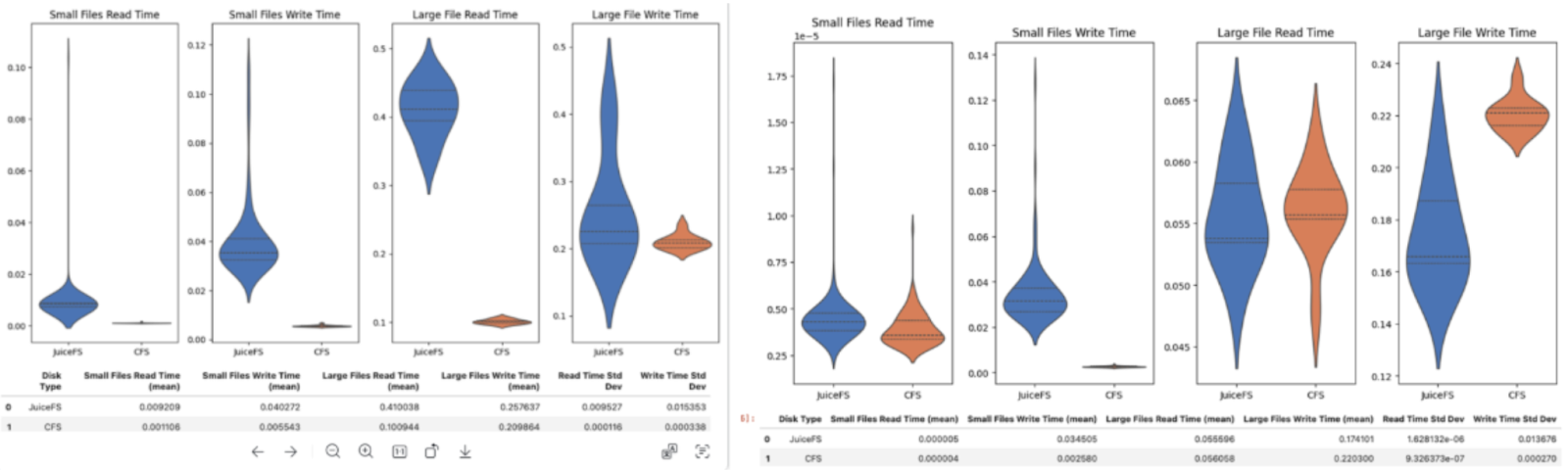
During JuiceFS usage, application staff reported slower Pod startup time. After joint investigation by the operations and application teams, we found that the delay primarily occurred during file copy (cp) operations in the application code. Tests by the operations team revealed that, with the same number of files, JuiceFS' copy performance was over three times slower than CFS. Since copy operations are single-threaded, we used the juicefs sync command to increase concurrency, significantly speeding up the copy process. All copy operations in production were replaced with juicefs sync.
Package import and file read/write performance optimization
During testing, the application staff found that package import speeds were slower with JuiceFS, with small file read/write speeds eight times slower than CFS and large file read speeds four times slower. We resolved this issue by increasing client caching, using the NVMe drives available on GPU machines as read cache media. After optimization, the read/write performance for both small and large files became comparable to CFS, significantly improving application performance.
Summary
By implementing JuiceFS and establishing a new object storage-based architecture, we reduced overall storage costs by 90%. Throughout data migration, Kubernetes integration, performance optimization, and high-concurrency scenario handling, we accumulated extensive expertise. This system refactoring has not only significantly improved platform stability, performance, and scalability but also laid a solid foundation for future growth. We hope these practical insights can serve as a valuable reference for more life science and AI enterprises.