















JuiceFS is a distributed file system that offers both an Enterprise Edition (hosted on-premises or in the cloud) and a Community Edition. While the open-source Community Edition is more familiar to most users, the Enterprise Edition was actually released earlier and served as the foundation for the Community Edition's architecture.
In this article, we’ll explore the unique features and services of JuiceFS Enterprise Edition and compare them to the Community Edition. We hope this post can help you choose the edition that best suits your needs.
JuiceFS development timeline
- In October 2017, we released the cloud service of JuiceFS, providing software as a service (SaaS) services built on public cloud infrastructure. Over the years, it has undergone extensive testing and served enterprise customers, ensuring its stability and reliability.
- In 2018, JuiceFS introduced the metadata cache and data cache functionalities. Additionally, Juicesync was open-sourced. It lets users copy their data in object storage between any clouds or regions.
- By 2019, JuiceFS had been deployed on 16 global public clouds, offering cloud services. It also supported on-premises deployments and released the Hadoop Java SDK and Kubernetes CSI drivers.
- In 2020, we developed our metadata engine capable of handling tens of billions of files. We launched the S3 gateway and WebDAV services, extending compatibility to Windows systems.
- In January 2021, we released the Community Edition of JuiceFS on GitHub.
- In 2022, we improved the user experience of on-premises deployments. The Hadoop Java SDK added support for Kerberos and Apache Ranger.
- In January 2022, JuiceFS Community Edition 1.0 was released, marking the first long-term support (LTS) version.
- In March 2023, JuiceFS Enterprise Edition 4.9 was released.
- In June 2023, JuiceFS Community Edition 1.1 Beta was released.
Why we introduced JuiceFS Community Edition alongside the Enterprise Edition
The introduction of the Community Edition alongside the Enterprise Edition was driven by several factors:
- Customization flexibility: JuiceFS is a cloud-native distributed file system, catering to diverse user requirements. By offering an open-source version, users can customize and adapt the software to their specific needs, facilitating faster adoption and implementation.
- Enhanced architecture: The Community Edition features an improved architecture that allows users to choose their preferred database as JuiceFS' metadata engine, based on their specific use cases. Currently, the Community Edition supports multiple mature databases like Redis, MySQL, and TiKV, which enjoy robust ecosystem support. This enables technical professionals to leverage these databases to meet their specific requirements, seamlessly integrating them with JuiceFS for optimal user experience.
- Openness and trust: Through open-source availability, users gain transparency into JuiceFS' internal workings, enabling them to make informed decisions based on their specific use cases. JuiceFS Community Edition adopts the widely recognized Apache 2.0 open-source license. This promotes openness and engenders trust among users. The choice of an open-source codebase and license instills confidence and assurance in users.
- Efficient iteration: The Community Edition encourages broader user participation and leads to accelerated product iteration. User feedback is carefully evaluated. If certain requirements are deemed broadly applicable and important, they’re incorporated into our maintenance or development roadmap of the Community Edition. This eliminates the need for individual customizations by each company, streamlining the process for all users.
JuiceFS Enterprise Edition vs. Community Edition
Similarities
- Consistent user experience: Both editions provide a consistent user experience, not only in terms of their interfaces but also through code-level reuse in their underlying implementations.
- Metadata import and export: Both editions support metadata import and export, allowing for seamless migration of metadata between the Community and Enterprise Editions. Users can export metadata from one edition and import it into the other, enabling smooth transitions.
- Support for mature object storage: Both editions offer support for over 30 mature object storage systems.
- Scalability: Both editions can handle tens of billions of files and petabytes of data. For users of the Community Edition aiming to achieve a scale of tens of billions of files, the most mature solution currently available is to use TiKV as the metadata engine.
- Multiple access methods: Both editions support various access methods, including POSIX, HDFS, CSI drivers, S3, and WebDAV.
- Local data and metadata caching: Both editions provide caching mechanisms for local data and metadata, improving access performance. They also offer cache warm-up functionality.
- Data security features: Both editions offer various data security features, such as a Trash, data encryption, and data cloning.
- The inclusion of several enterprise-level features, such as directory quotas and usage statistics. As the number of files in a file system grows into the tens of billions, enterprises may need to regularly analyze directory usage to better manage and clean unnecessary data. Therefore, the ability to quickly generate directory usage statistics becomes crucial. Directory quotas are also valuable for multi-tenant platforms, allowing the limitation of capacity and file counts for different directories.
Differences
Target use cases:
- Enterprise Edition: Designed for distributed file systems in high-performance applications and scenarios involving massive files. It’s suitable for use cases such as AI model training, distributed computing on big data platforms, and high-performance computing.
- Community Edition: Geared towards general-purpose distributed file systems, emphasizing ease of maintenance, usability, and customization. It’s ideal for teams actively participating in open-source community development.
Architecture:
- Enterprise Edition: To support massive data storage and high-performance access, the Enterprise Edition distinguishes itself from the Community Edition by employing a proprietary distributed metadata engine and distributed cache.
- Community Edition: Users of the Community Edition can choose a suitable database as the metadata engine based on their specific needs. However, the Community Edition does not currently support distributed caching.
Additionally, the Enterprise Edition offers several distinct features:
- Ease of use: It provides a graphical management and operations platform that can be used for both cloud service and on-premises deployments, facilitating better maintenance and utilization of JuiceFS.
- Multi-cloud and hybrid cloud architecture: Leveraging the file system mirroring feature in the Enterprise Edition, users can automate data replication between clouds or between a cloud and an on-premises data center. This allows applications to access the required data quickly, regardless of the environment.
- User authentication and permission management: The Enterprise Edition supports various authentication and permission management methods, including Kerberos, Ranger, POSIX ACL, and access tokens. Access tokens, a unique feature of JuiceFS Enterprise Edition, enable unified authentication or permission management for mounted points. Each token corresponds to read or write permissions and can implement fine-grained control based on specific IP ranges.
- Data security: The Enterprise Edition provides data recovery functionality based on Raft logs, similar to the concept of a time machine. Users can restore the file system to any previous state using log records, recovering mistakenly modified or updated data and ensuring data integrity. Additionally, the Enterprise Edition includes a centralized client operation auditing feature that helps enterprises audit all client activities.
Release cycle:
- Enterprise Edition: Approximately one major release every quarter, for example, from v4.9 to v4.10.
- Community Edition: Approximately one major release per year, for example, from v1.0 to 1.1, with quarterly patch releases, for example, from v1.0.1 to v1.0.2. We also maintain a LTS version.
An in-depth overview of JuiceFS Enterprise Edition
The architecture of JuiceFS Enterprise Edition
The following figure shows the architecture of JuiceFS Enterprise Edition:
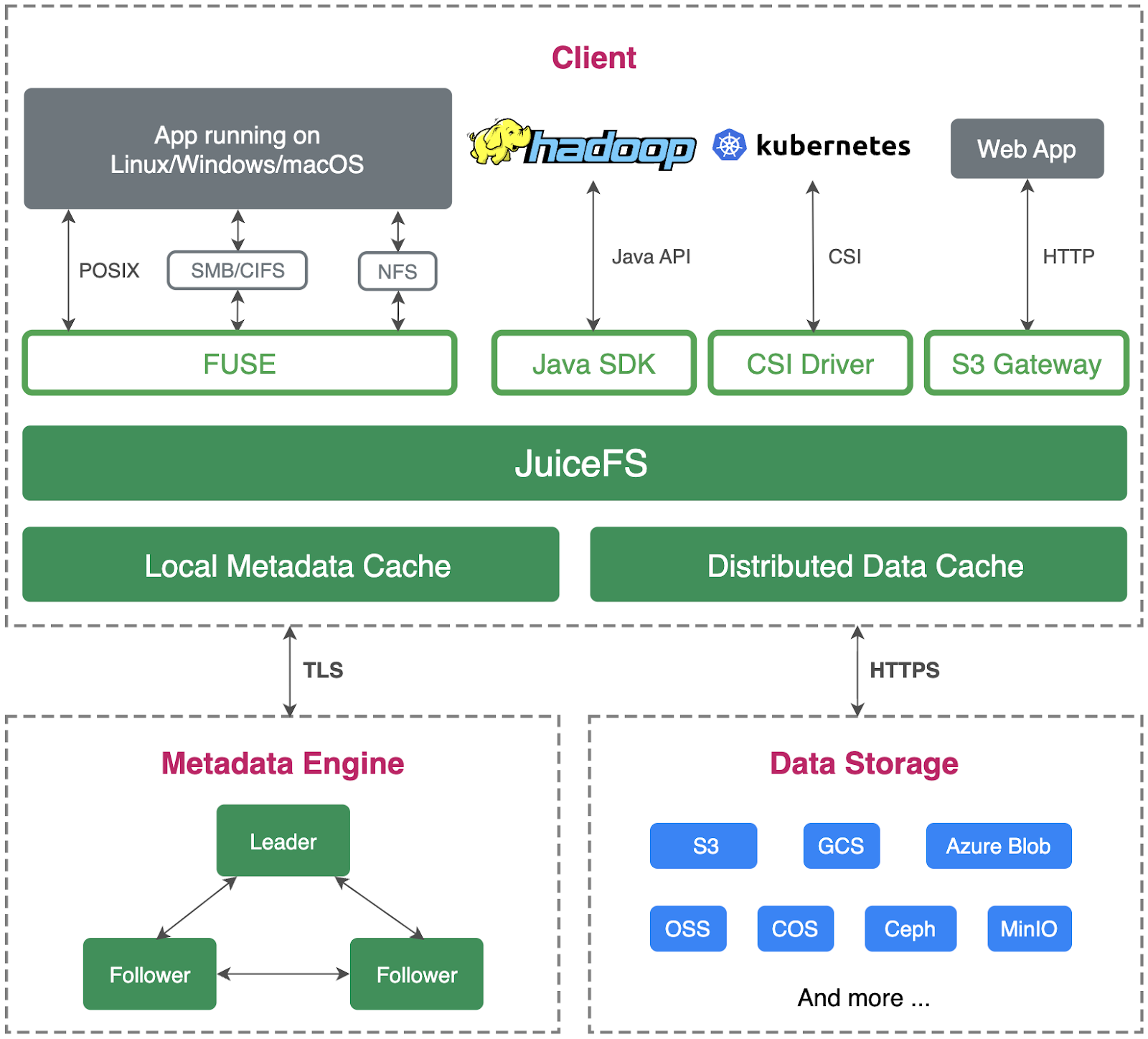
The architecture of the Enterprise Edition is similar to the Community Edition, consisting of three main components:
- The Metadata Engine
- The Data Storage
- The Clients
The major difference lies in the metadata engine used in the Enterprise Edition, which is a proprietary distributed storage system implemented based on the Raft consensus algorithm. It includes roles such as a leader and followers. As for the clients, different client options can be used in various scenarios, such as POSIX, Java SDK, CSI driver, and S3 gateway.
Each client has its own local metadata cache and a distributed data cache. By forming a cache group, these different clients can collectively create a cache cluster, enabling a larger caching capacity to store more data.
The single-partition architecture of the metadata engine
This is the internal architecture of the metadata engine with a single partition:
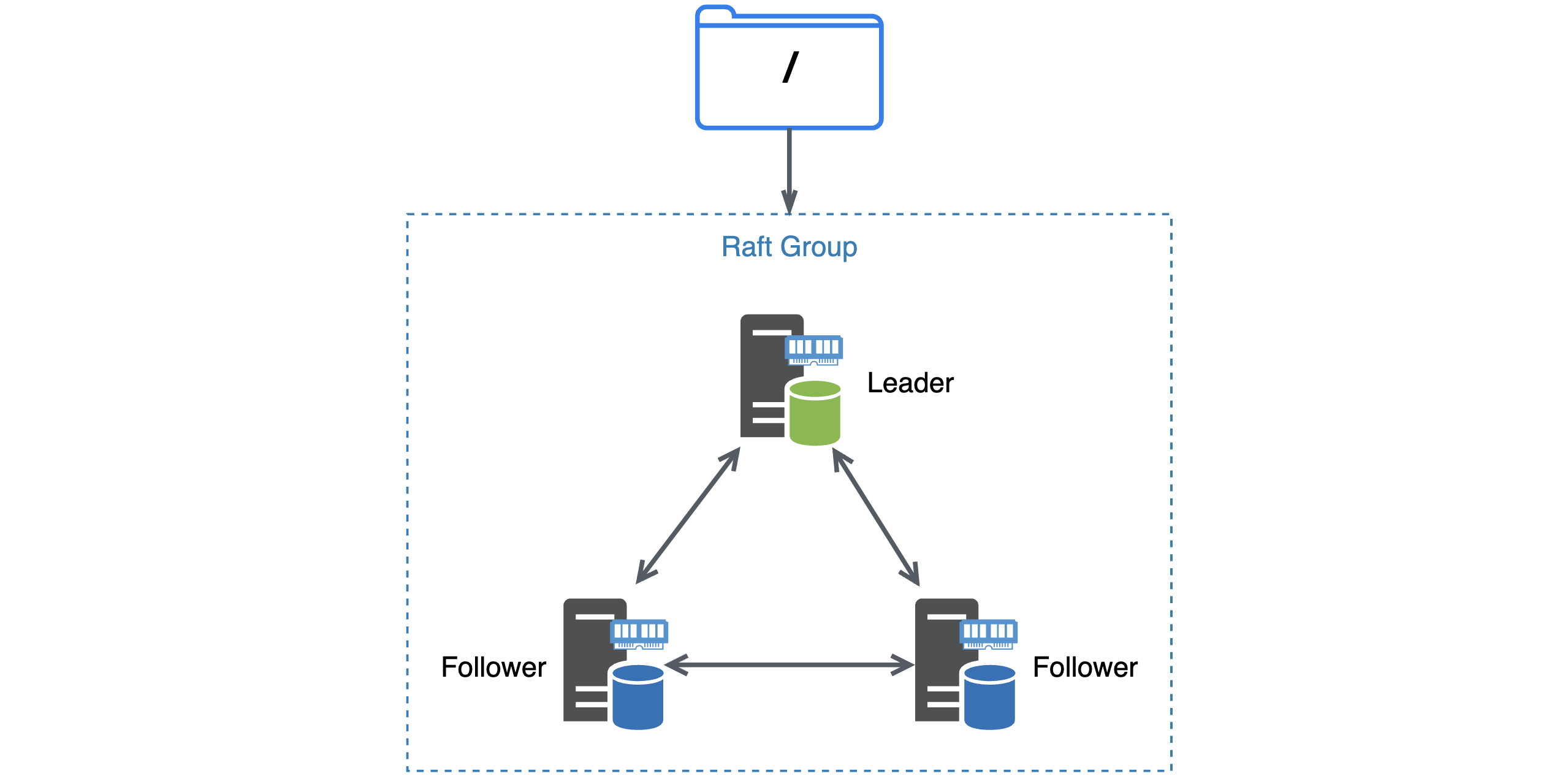
In a production environment, a metadata cluster requires a minimum of three nodes: one leader and two followers. Both the leader and followers store the metadata in memory. Client read and write requests are handled exclusively by the leader node, while the follower nodes do not participate in request processing. Consequently, metadata operations, such as reading and writing, exhibit exceptional speed and responsiveness.
When the leader node fails, for example, when it crashes or meets a network issue, the remaining two follower nodes select a new leader, and the client automatically switches to the new leader. The switching process typically completes within seconds.
To ensure the durability of the metadata, each node persists the metadata modification log and memory snapshot to the local disk. As a result, there are three copies of the metadata in memory and three copies on the local disks. Furthermore, JuiceFS Cloud Service periodically replicates this metadata to external locations beyond the cluster. This further ensures data reliability.
Typically, it’s recommended to store approximately 100 to 200 million files within a single-partition architecture. As data volume and file count grow, the maintenance cost of the entire cluster may gradually increase. Therefore, it’s necessary to expand the single-partition architecture into a multi-partition architecture to accommodate these growing demands.
Multi-partition metadata engine architecture
For larger storage requirements, such as billions or even tens of billions of items, you can upgrade to a multi-partition architecture. Similar to the single partition architecture, each Raft group consists of one leader and two followers. However, nodes in different groups can perceive and communicate with each other.
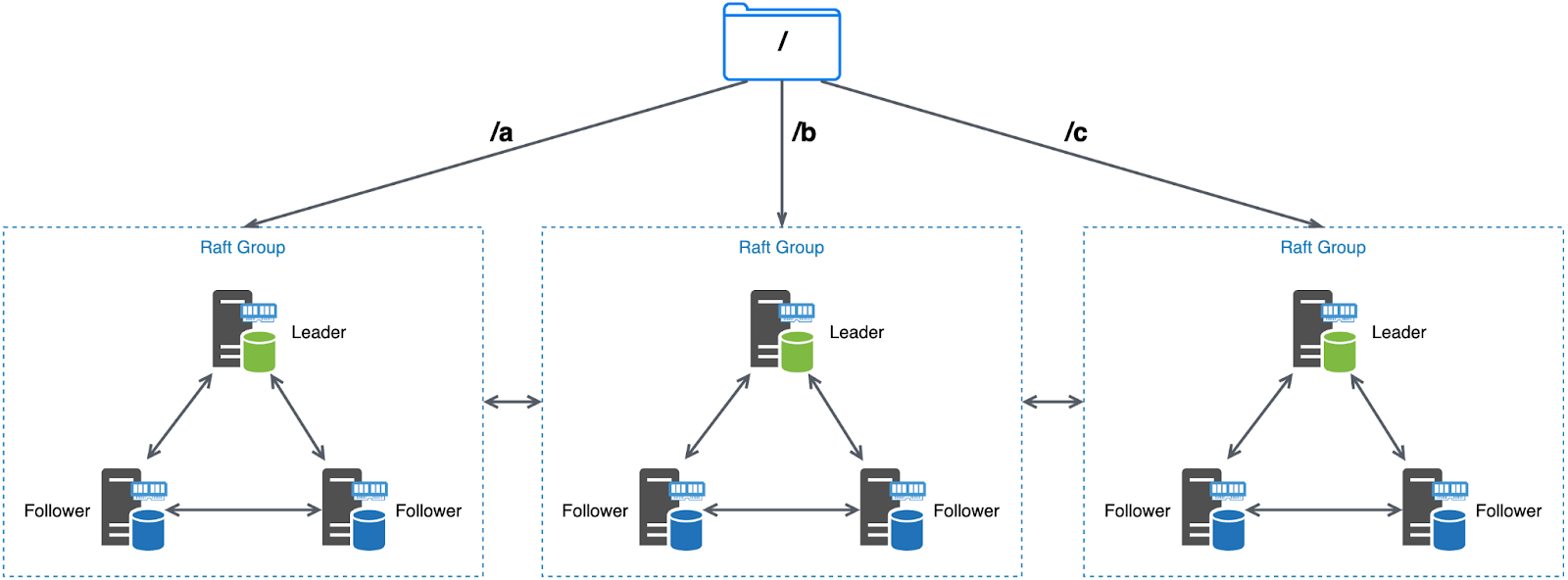
Metadata of different directories is evenly distributed across multiple partitions. This ensures balanced data distribution within the same file system. The system employs an automated data balancing strategy to achieve this distribution. Moreover, users have the flexibility to manually migrate the metadata of specific directories to further fine-tune the data balance.
Core features of JuiceFS Enterprise Edition
Distributed caching
JuiceFS Enterprise Edition offers a key feature known as distributed caching. In a model training setup, where each node in the cluster possesses memory and GPU resources and is connected to the JuiceFS file system, the GPU nodes retrieve data using the local JuiceFS client. Caching data within the memory and disk of each GPU node allows for fast access. In cases where the local cache does not contain the required data, the cache cluster layer is accessed as a fallback option. This distributed caching mechanism improves performance by minimizing data retrieval delays and optimizing overall model training efficiency.
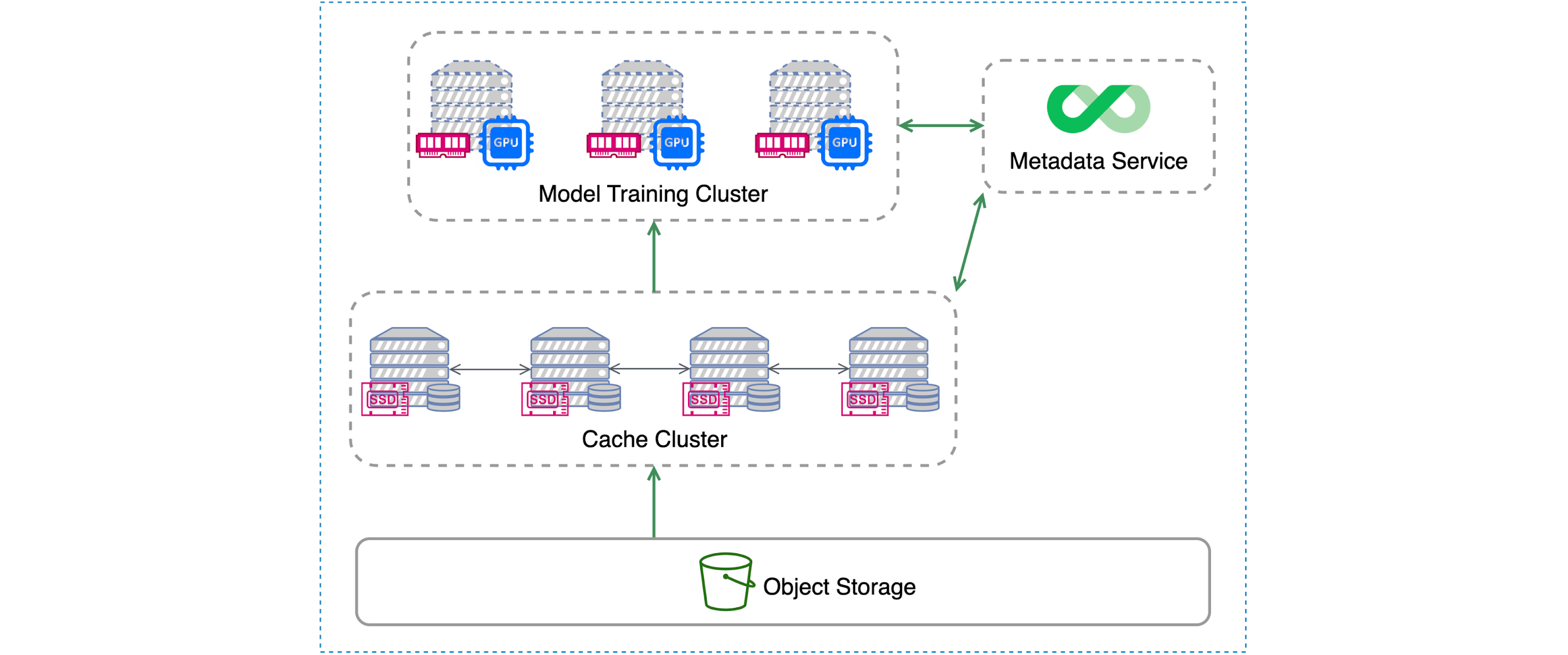
The cache cluster serves as a distributed caching layer implemented by the JuiceFS client. To meet the high data throughput requirements of the compute layer, the cache cluster needs to be configured with high network bandwidth and high-performance, large-capacity storage devices, such as NVMe SSDs. If a cache request is not hit in the cache cluster, the request ultimately falls back to the object storage to retrieve the original data. Throughout this process, both the training cluster and the cache cluster need to communicate with the JuiceFS metadata service.
Compared to traditional file systems or distributed storage, JuiceFS distributed cache offers several advantages:
- Efficient management and access of hot data:
- The cache cluster in JuiceFS is an independent single-copy cluster that can dynamically scale in and out. It operates independently from the compute cluster and object storage, making it ideal for storage scenarios that require high-performance access to hot data.
- Users can flexibly configure the cluster size, node disk capacity, and network bandwidth to ensure that the cache cluster meets the performance requirements of the training cluster for accessing hot data.
- Note that the cache cluster typically doesn't cache all data from the object storage due to the higher cost of high-performance storage. Enterprises need to balance performance and cost.
- Improved training efficiency brought by multi-level cache acceleration:
The cache retrieval process follows a multi-level access flow, from faster to slower levels, including memory, local cache disk, and independent cache cluster. Thus, there are multiple levels of cache access between the training nodes, cache nodes, and object storage. No matter which level of cache is hit, the read requests receive an immediate response.
File system mirroring
The file system mirroring functionality is used in multi-cloud or hybrid cloud scenarios. It automatically duplicates a file system to one or multiple regions, such as replicating it to another data center, from public cloud to private cloud, or from private cloud to public cloud.
Replication is not limited to a one-to-one relationship; it can also involve one-to-many relationships. You have the option to configure one or multiple mirroring clusters to expedite the replication of data to different regions and environments. This caters to the requirements of remote collaboration or task scheduling that may arise.
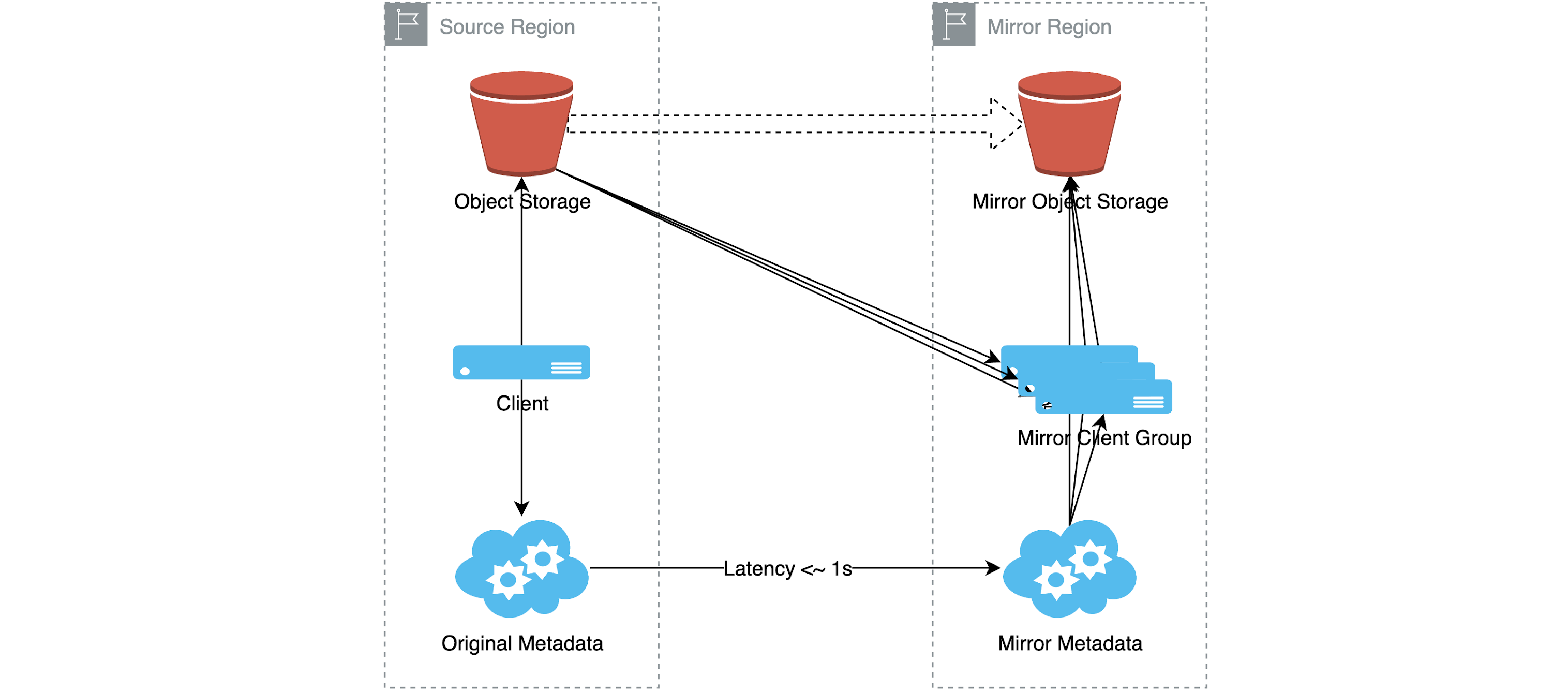
As soon as new data is written, synchronization is promptly triggered to achieve rapid replication to a remote storage location. Once you write data to the original region using the JuiceFS client, the metadata and data from the object storage in the original region are asynchronously copied to the metadata cluster and object storage in the mirroring region. Consequently, the client in the mirroring region gains access to JuiceFS through the local mirrored file system.
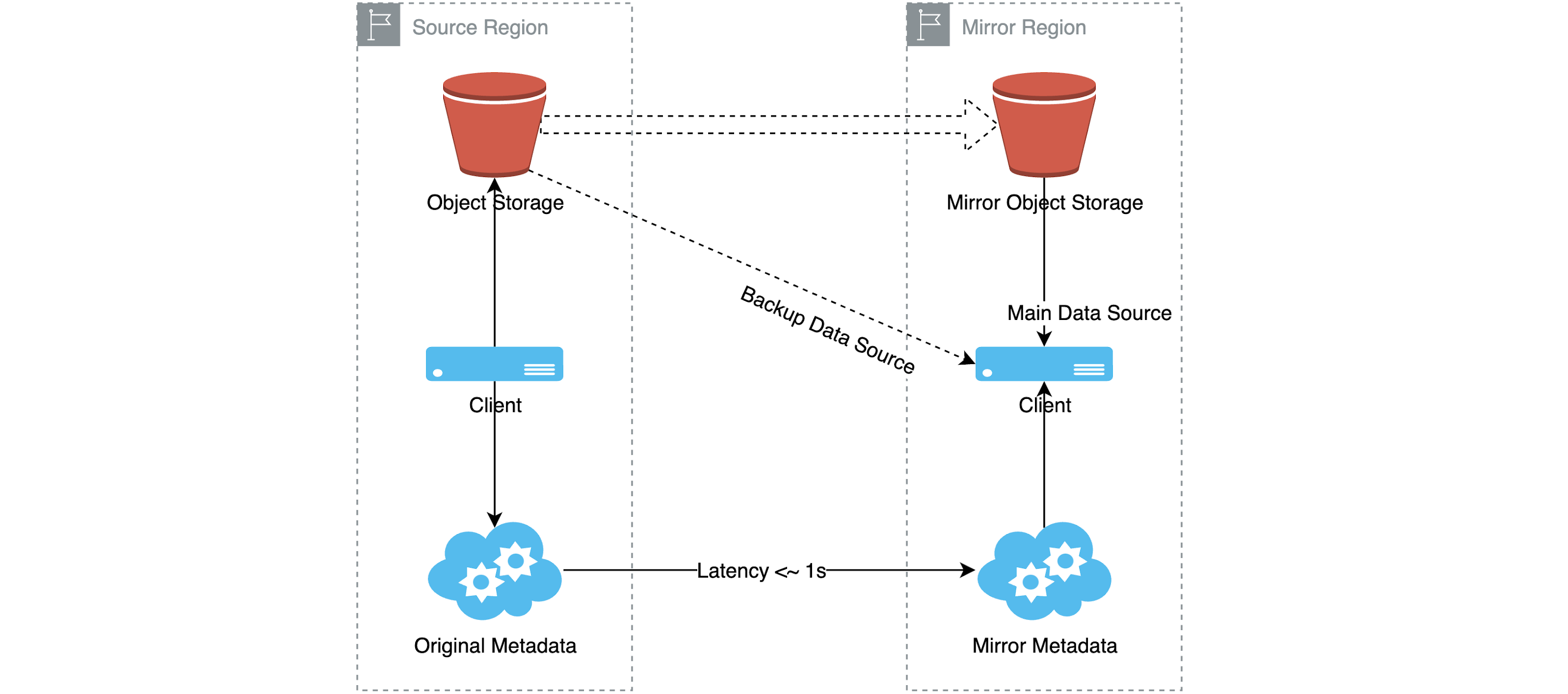
When the client in the mirroring region retrieves data, the preferred data source is the object storage in the current region. However, in cases where the data has not been replicated to the mirroring region's object storage from the original region, possibly due to network latency, the client can alternatively fetch the data from the original region to ensure seamless access for applications. Note that obtaining data from the alternative data source is less efficient than accessing the preferred data source.
Data security
JuiceFS Enterprise Edition provides various types and dimensions of data security measures for enterprises, including:
- Access control based on access tokens: The JuiceFS console lets you control permissions based on access tokens. You can restrict the read and write permissions of users or teams who use the token. This includes limiting access to specific subdirectories, allowing access only from specific IP address ranges, and specifying permitted operation types. These multi-dimensional restrictions help enforce fine-grained access control.
- Integration with Kerberos and Ranger: In big data scenarios, JuiceFS' Hadoop SDK can integrate with Kerberos and Ranger to connect with the enterprise's internal user authentication and permission management system. This integration enhances user authentication and authorization in enterprise environments.
- Data recovery based on Raft log of the metadata cluster: JuiceFS uses the Raft log of the metadata cluster to enable data recovery and prevent data from being mistakenly updated. This ensures data integrity and protects against accidental modifications.
- Centralized auditing: JuiceFS can collect and audit all client operations. The auditing feature is implemented based on JuiceFS' access logs. This allows for centralized monitoring and tracking of client activities, enhancing transparency and accountability.
The web console
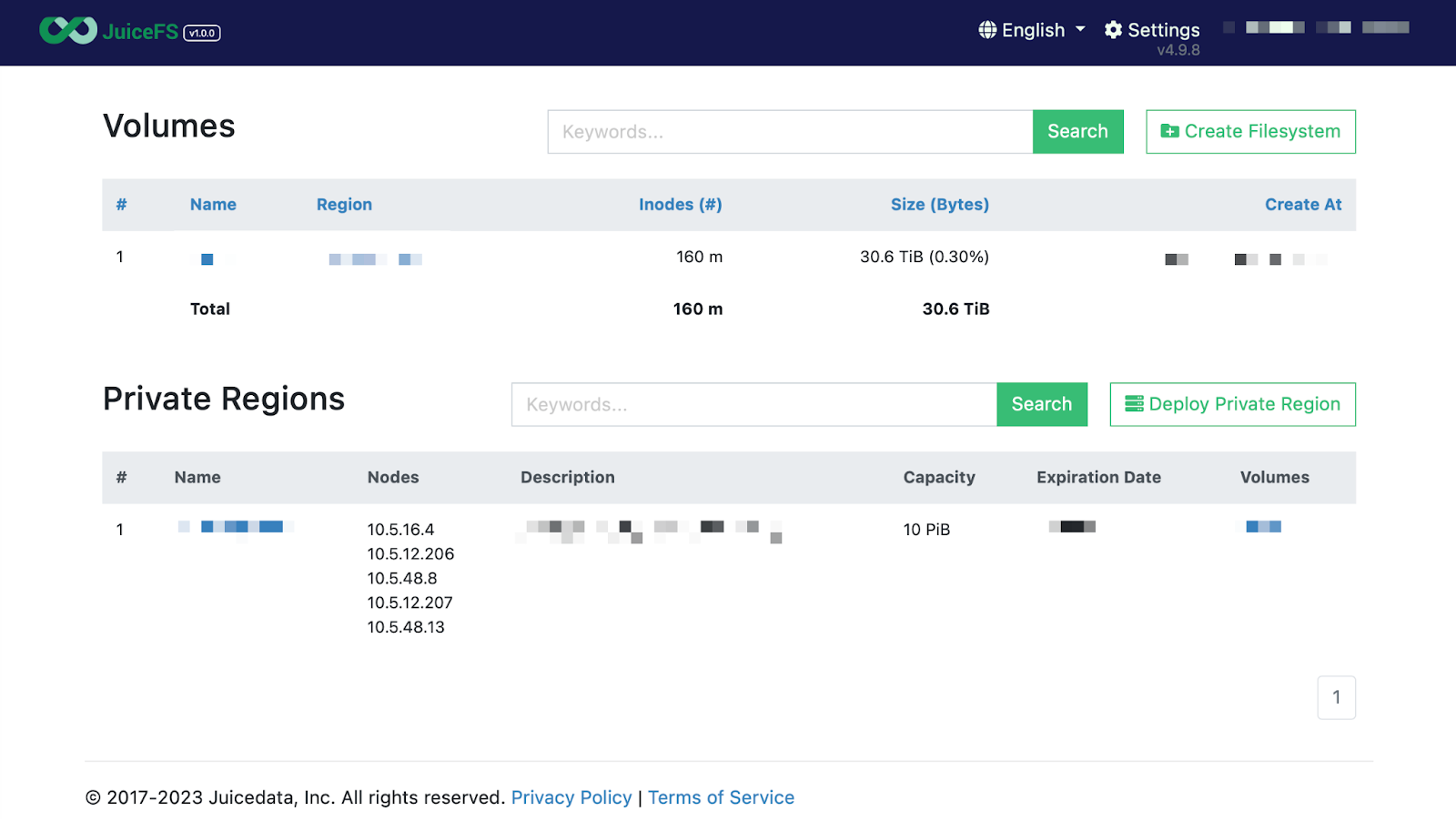
JuiceFS Enterprise Edition provides a web-based console where you can manage the JuiceFS metadata cluster and file system. Through this console, you can create a file system and view its essential information, such as the directory structure and file names. For on-premises deployment of the Enterprise Edition, you can also manage the JuiceFS metadata cluster through the console. In the figure above, you can see basic information about the metadata cluster, such as the IP addresses of the nodes.
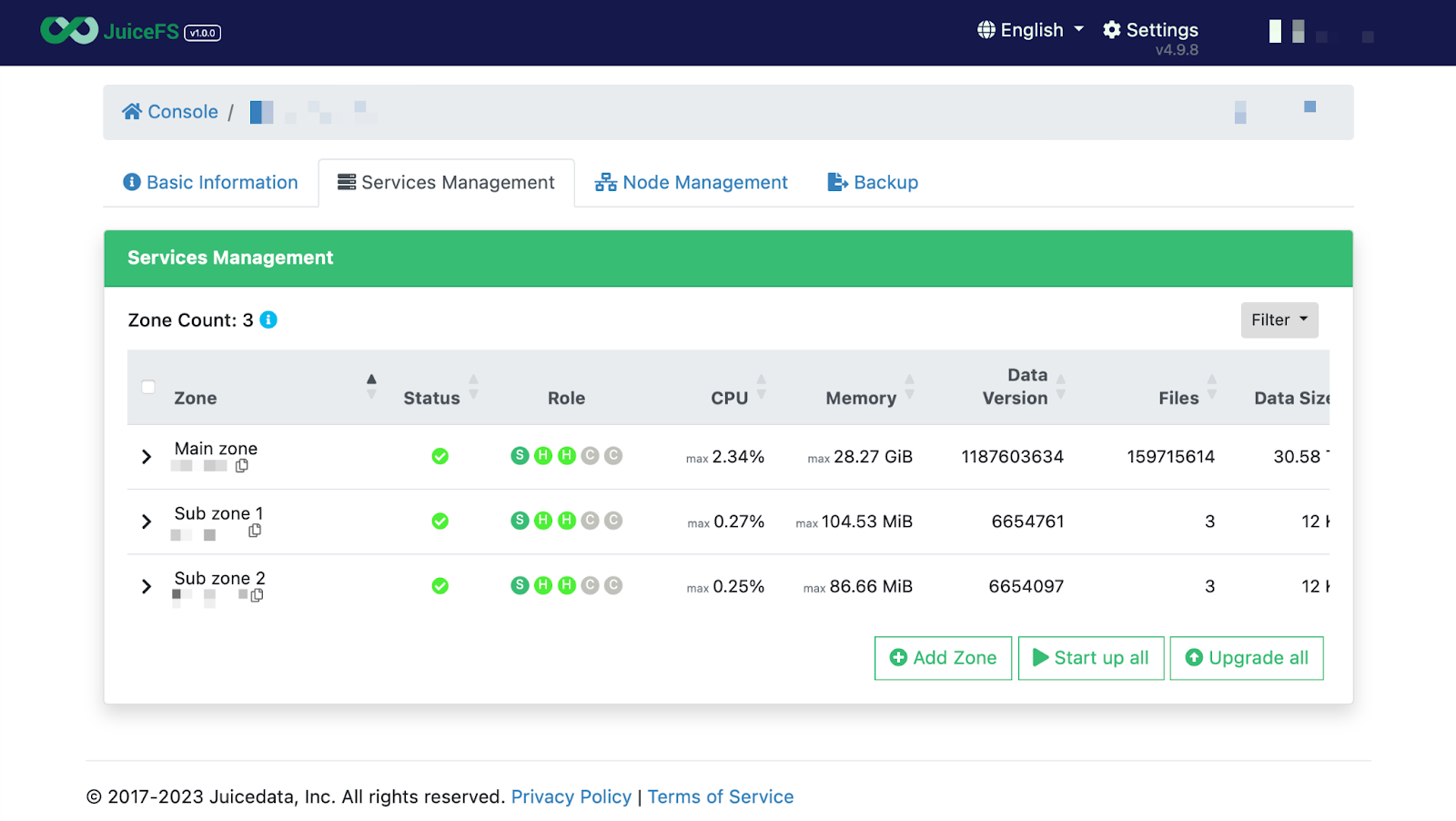
As shown in the figure above, you can manage the metadata cluster through the JuiceFS web console. Within the console, you can view information such as:
- Version numbers
- Roles, for example, service nodes, hot standby nodes, and cold standby nodes
- CPU and memory usage
- The number of files and data size stored in the file system
The console provides maintenance operations, for example:
- Upgrades
- Restarts
- Log viewing
- Accessing metadata service logs
Delivery options
Cloud service
JuiceFS Cloud Service features:
- It supports popular public cloud platforms worldwide, which is similar to out-of-the-box services available on public clouds.
- It’s a fully managed service provided by Juicedata, primarily hosting the metadata engine, while users are responsible for creating and using object storage in the cloud. The entire service workflow and experience are designed to be out-of-the-box.
- We offer a 99.95% service-level agreement (SLA) guarantee for our cloud service.
- It has a web-based console.
- It uses elastic capacity billing, a similar pricing model as other mainstream cloud storage products. This means that the cost is determined by the amount of data stored in JuiceFS.
- It’s a multi-tenant environment, suitable for applications with file counts around one hundred million or smaller.
On-premises deployment
Our on-premises deployment features:
- You can implement on-premises deployment in a virtual private cloud (VPC) on the cloud or in a data center. If you choose data center deployment, you must have object storage in place as JuiceFS Enterprise Edition does not include object storage.
- In terms of user experience, on-premises deployment is very similar to our cloud service. The on-premises deployment console provides additional management functionalities, such as creating and maintaining the metadata cluster.
- In an on-premises deployment environment, all JuiceFS components, including the metadata engine, are fully deployed within the user's environment. Therefore, you have two options for operations and maintenance:
- Self-management: Juicedata provides a platform that enables users to easily manage the entire JuiceFS cluster while offering technical support.
- You can authorize Juicedata to handle the maintenance for you, such as granting permissions to certain machines related to JuiceFS.
- It supports both the elastic capacity billing model and a fixed capacity billing model. You can choose a fixed capacity and obtain a license authorization.
- It applies to scenarios with tens of billions of files and higher performance requirements.
JuiceFS Enterprise Edition 4.9 introduction
New features
JuiceFS Enterprise Edition 4.9 has several new features:
- Expanded command set: It has introduced several new subcommands, including
gateway,sync,stats, andload. These commands were previously available only in the Community Edition. - Multiple bucket support: This feature already exists in the Community Edition. Typically, a file system corresponds to a single object storage bucket. However, if a single bucket has limitations, such as capacity or queries per second (QPS) restrictions, it may not meet the read/write requirements of an application. In such cases, multiple buckets can be associated with a file system to ensure data is evenly distributed across different buckets. This allows for the aggregation of underlying read/write bandwidth or throughput from multiple buckets, enabling better horizontal scaling of external storage.
- Additional functionality and improvements. For example, it allows administrators to view the mount parameters for each client from the console. This facilitates troubleshooting.
- The Java SDK has various improvements, including support for configuring Kerberos user mapping rules. This is a significant advancement for users requiring Kerberos. The SDK also supports configuring a separate caching cluster for Hadoop applications.
Performance and stability enhancements
JuiceFS Enterprise Edition 4.9 has several performance and stability optimizations:
- Metadata cache performance and memory usage enhancement. This brings accelerated metadata access. It’s particularly beneficial in the Enterprise Edition, where there is a larger cache of metadata, ensuring consistent metadata caching.
- Reduced read amplification in distributed caching. Distributed caching can enhance read performance but may sometimes lead to read amplification. Version 4.9 further optimizes this problem.
- Improved fault tolerance capability of data mirroring synchronization. Fault tolerance is crucial. Especially when synchronizing a large amount of data to multiple mirror regions, stability and fault tolerance are paramount in such scenarios. Therefore, in version 4.9, we enhanced the fault tolerance capability of data mirroring synchronization.
Upcoming plans for JuiceFS Enterprise Edition
Our plans for JuiceFS Enterprise Edition in the near future:
- External storage import and cache acceleration: Many enterprises have large amounts of existing data stored in external storage. To facilitate quick import into JuiceFS without the need for data replication, we’re supporting importing data from external storage. We’ll also allow users to leverage the unique functionalities of JuiceFS Enterprise Edition, such as cache acceleration and distributed caching. The feature is implemented and undergoing internal testing.
- Multi-mount cloud disk support: This enables the sharing of cloud disks across multiple virtual machines (VMs), rather than being limited to a single VM. Certain public cloud platforms already support multi-mount cloud disks, allowing multiple VMs to simultaneously mount the same cloud disk and share storage.This capability is particularly beneficial for scenarios with extreme performance requirements, especially for small file read/write operations. By performing read/write operations on high-performance cloud disks for small files, more efficient data operations can be achieved. Compared to object storage, high-performance cloud disks offer greater advantages in terms of latency and overall storage performance. This feature is in the testing phase and will be further optimized.
- RDMA (RoCE Network) support: Many users are interested in leveraging the latest technologies to improve network request efficiency in better network environments or with advanced network hardware. This feature is now in the development phase.
Try JuiceFS Enterprise Edition
If you're interested, you can try our Enterprise Edition now. If you have any questions or would like to share your thoughts, feel free to join our discussions on GitHub and community on Slack.