FIO 性能测试
本章包含两部分内容:一些规划及设计性能测试的建议,以及展示不同条件下性能测试的结果。如果你只想参考 JuiceFS 的性能测试结果,请下拉直接参考对应小节,不需要从头开始阅读。
明确测试意图、资源边界
JuiceFS 客户端可以跑到很高的吞吐(单个大文件读取 2GB/s 左右)——但前提是给足资源,并且使用性能极佳的对象存储服务。因此在文件系统测试开始前,需要明确目的:是希望不计成本给足资源、跑出极限性能呢,还是在接近实际生产资源隔离的条件下,看给定的资源能提供怎样的性能水平。
只有明确测试意图,后续测试成绩不达预期的时候,才能知道要怎么优化。如果你希望测试 JuiceFS 的极限性能,只要是资源引发的性能不足,都尽可能扩充资源、提升成绩。但是依照这种方式测得的极限性能,往往无法在实际环境中复现,因为生产资源不可能无限地分配给某个业务(或者 JuiceFS 客户端)。因此我们更推荐你「在接近实际生产资源隔离的条件下,看给定资源能提供怎样的性能水平」。本文中执行的测试,也都依照这个思路来设计。
测试对象存储(可选)
在一切开始之前,建议先验证对象存储的性能是否达到其宣称的规格。如果对存储后端的性能有着高预期,但实际测试时却发现吞吐不够,会陷入「不知道是 JuiceFS 没有做好调优、或是有 bug,还是对象存储本身性能不够」的困境。因此我们建议在测试前就确立好对象存储的实际性能水平,打好基础。
如果你在使用公有云提供的对象存储服务(S3、OSS 等),可以视情况跳过这道工序。但对于自建对象存储,或者采购了私有部署模式的商用对象存储,那么我们建议将对象存储测试作为必要项,并且在所有后续测试开始之前就验证好。
如果没有特殊需要,建议直接用 juicefs objbench 命令用来测试对象的性能,此处以 Ceph 为例,先测试单线程情况下的吞吐,确立基准:
# 记录 p=1 时的基准测试,获得最佳时延和单线程的带宽数据,用于后边的估算
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p=1 --big-object-size=4096
逐渐增大并发(-p),可以翻倍翻倍地测(最大到 CPU 核数),观察时延和带宽,前期应该是能够线性增长的。需要注意当并发较大时,如果预期带宽较大,需要增大 --big-object-size 来保证有足够的数据进行读写,获得准确的数据。例如:
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p 128 --big-object-size=4096
用递增并发的方式测得顶点以后,对于某些对象存储的 SDK,可能还需要增大 --object-clients,比方说 Ceph SDK 对单个客户端实例施加了带宽上限,因此用该参数增大客户端实例数,就能继续用更高的对象存储并发来提升吞吐,找到单机上限。例如:
juicefs objbench --storage=ceph --access-key=ceph --secret-key=client.jfspool jfspool -p 128 --big-object-size=4096 --object-clients=[2|3|4]
确认硬件信息(可选)
对于自建机房(数据中心),我们建议提前记录、核实机器的各项硬件规格,这是为了:
- 确认环境的正确性;
- 确认硬件性能符合预期。
CPU
记录 CPU 型号、个数、核数、频率相关的信息:
dmidecode -t processor | grep -E 'Socket Designation|Version|Speed|Core|Thread'
确认 CPU Governor。根据型号和驱动的不同,查询的地方会不同。简单的确认方式就是查看一下当前的运行频率:
cat /proc/cpuinfo | grep MHz
如果频率和标称相差比较大,建议和供应商沟通确认,确保性能模式等相关选项正确设置(比如采用“性能模式”),减少 CPU 频率波动对性能测试准确性的影响。
内存
记录类型、数量、大小、频率、NUMA 信息:
dmidecode --type memory | grep -E "Configured Memory Speed|Volatile Size|Type: DDR" | grep -vE "None|Unknown"
numactl --hardware
硬盘
硬盘对 JuiceFS 的缓存性能非常重要,尤其是分布式缓存场景,如果是自建机房,建议硬盘安装好以后,立刻对性能进行测试,确保达到标称。
以 NVMe 为例,可以使用 nvme-cli 来查看:
nvme list
用 FIO 对硬盘进行读写基准测试,下方的测试实例会给出 4K 随机读写的 IOPS 和 1M 大小时的吞吐。
fio --name=4k --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=4K --rw=randwrite --numjobs=16 --group_reporting
fio --name=4k --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=4K --rw=randread --numjobs=16 --group_reporting
fio --name=1m --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=1M --rw=write --numjobs=16 --group_reporting
fio --name=1m --filename=/dev/nvme0n1 --ioengine=libaio --direct=1 --iodepth=128 --bs=1M --rw=read --numjobs=16 --group_reporting
将测试结果和该硬盘型号对应的标称性能数据进行对比,确认是否符合预期。如果确实出现性能不符的情况,除了硬盘本身的故障外,也有可能不慎将本该使用 NVMe 协议的硬盘插错接口(比如 SATA AHCI 协议)导致性能下降的情况,建议与机房运维一起协查。
网卡
- 首先记录网卡信息,根据预先规划的网段找一下对应的网卡,运行
ethtool <interface>确认其带宽。如果该网卡是 bond,那么cat /proc/net/bonding/<interface>来记录 bond 信息,了解 slave 是谁、哈希策略等; - 网卡速率可能受到 CPU 等因素的影响,在没有其他网络负载的前提下,用 iperf 进行压测并记录结果;
- 测试期间额外核实确认路由是否正确,例如通过
sar -n DEV 1来确认网卡的流量状况,判断是否流量走在正确的网卡,bond 网卡是否流量均衡; - 如需测试独立缓存集群场景,需要确认清楚:缓存提供方和消费端分别位于哪些机器,这些机器是否同属一个网络环境?如果需要跨 VPC 或者其他涉及到跨网络环境访问,建议提前测试好跨网络环境的性能,谨防网络环境引起的性能下降。
挂载参数预调优
依上小节的推荐,你应该首先规定资源上限,并且在资源限制内进行测试。因此在开始使用 FIO 测试之前,先根据你的实际场景,对挂载点的性能参数进行提前调优。要注意,JuiceFS 的挂载参数远不止下方小节提到的这些,还有很多其它参数也会不同程度地影响性能。不过可以肯定,在大部分场景下,你只需要充分理解和设置这几个参数,就能获得很好的性能。
缓冲区调优
JuiceFS 所有的 I/O 都经由缓冲区来完成,因此 --buffer-size 是对 JuiceFS 性能影响最大的参数。如果你尚不熟悉什么是读写缓冲区,请先阅读相关文档。
假设资源上限为 32 核 CPU、64G 内存,对于高负载场景,可以按照客户端占用内存大致为缓冲区的 4 倍来估算,因此在整个测试过程中,--buffer-size 都不应超过 64 * 1024 / 4 = 16384。
16G 的缓冲区已经非常大,能提供很高的并发和吞吐,FIO 测试通常不需要如此大缓冲区,因此建议初始设置为 1024 或 2048 即可。后续如有缓冲区不足的迹象(使用 juicefs stats 命令来实时观测缓冲区使用情况),再进一步在容许范围内增大。
juicefs mount --buffer-size=1024 myjfs /jfs
并发度调优
JuiceFS 客户端的并发首先是受到缓冲区大小的控制——缓冲区越大,并发度就会越大,来进行预读和并发上传的需要,因此提高缓冲区大小本身就有增加并发的作用。只有在特定场景下,通过缓冲区大小推算出来的并发可能并不合适,因此 JuiceFS 客户端提供 --max-uploads 和 --max-downloads 参数来显式指定并发上限。这组参数是针对特定场景的调优参数,通常来说(尤其是大文件顺序读场景),并不需要特意调节,理由如下:
--max-uploads默认 20,假设 4M 大小的对象存储块 PUT 延迟是 50ms,那么一秒内最高可上传1000 / 50 * 4 * 20 = 1600M,这已经是极高的吞吐,也正因此,上传并发度通常无需进一步提高。真正需要更高的上传并发度的情况只有高频并发小写,或者高频创建小文件;--max-downloads默认 200,和上一点原理类似,该值也不需要进一步调节,就算是大量随机读或者小文件场景,默认值也已经能很好胜任。
“通常不需要”毕竟是经验之谈,实测中如遇瓶颈,可以查看 juicefs stats 的输出,根据监控中的实际并发度来判断是否需要调整这两个参数。
缓存、缓存组相关调优
如果只需要测试单机性能,那么缓存大小 --cache-size 的设置非常简单易懂:有多少缓存空间,就设置多大。你如果希望测试无缓存的情况,可以指定 --cache-size=0 来禁用本地缓存盘,不过仍需注意:即便禁用了本地缓存盘,JuiceFS 客户端会额外占用 100M 内存作为缓存空间,因此监控上仍能可能有 100M 左右的缓存空间占用。
而如果此次测试需要用到分布式缓存,那么缓存组的测试方案就需要仔细制定,需要考虑和确定的有:
- 缓存组服务提供方的节点数量最多能提供多少?
- 缓存组总容量多少?能否放下预估的热数据量?如果预估数据量超过缓存组容量,考虑在 FIO 测试里安排穿透测试;
- 是否采用独立缓存集群架构?如果是的话,需要确定服务提供方、消费端客户端的资��源上限;
- 如果不是独立缓存集群架构,选择直接在缓存组内访问业务,那么节点间推荐采用高性能网络,拥有充裕带宽来进行节点间通信。
确定了以上要点,将规格翻译成 --cache-size、--group-weight、--group-ip、--no-sharing 等缓存组相关参数,来部署 JuiceFS 挂载点。
测试工具
FIO 有众多参数,如果你尚不熟悉这款测试工具,我们总结了最为关键的一系列参数的用法,帮助你自行构造测试。
| 项 | 说明 |
|---|---|
name | 测试任务名称。 |
directory | 测试数据读写路径,即 JuiceFS 挂载点,以下测试以 /jfs 举例。 |
readwrite、rw | 读写模式,在针对 JuiceFS 的测试中,一般只需要使用 read、write、randread 以及 randwrite 这四种模式来分别测试顺序读、顺序写、随机读以及随机写的性能。 |
blocksize、bs | 每次读写的块数据大小,测试顺序读写场景时设为 1m 或 4m,随机读写场景可以取值 4k~256k,或者结合实际应用场景来设置。 |
numjobs | 并发度,默认每个任务(job)是一个独立的 fork thread,如果不进行特殊设置,那么多个 job 会各自分批读写文件,不会出现多个 job 读写同一文件的情况,这也是我们推荐的测试设置。 |
openfiles | 如无特殊要求(比如使用 time_based 模式),建议携带 --openfiles=1 参数,让每个线程同一时刻只打开和处理 1 个文件。如果按照 FIO 的默认行为,他会打开 nrfiles 个文件,因此文件量增大,JuiceFS 的缓冲区会迅速被挤占、严重影响性能。除非明确要测同时打开多个文件、反复读取他们的时候,否则默认都是单线程内串行处理。 |
filename_format | 一般避免使用该参数。FIO 实际上不支持多个任务并发读取同一批文件,如果使用 filename_format 参数,会产生单线程、无并发的串行读效果,因此必须调整测试用例、改为每个 job 读取自己专属的一批文件。 |
filename | 一般避免使用该参数。比如在顺序写测试中用该参数规定了写入文件名,会造成 FIO 多线程写入同一文件,造成 FUSE 写流量远大于对象存储 PUT 的情况。 |
size | 每个任务处理的文件的总大小。 |
nrfiles | 在每个任务中生成的文件数量。 |
filesize | 每个任务中生成的单个文件大小,满足 filesize * nrfiles = size,因此该参数不需要和 size 同时设置。 |
direct | 文件读取过后,内核会利用空闲内存对数据、元数据进行缓存,因此往往只有首次读取产生了 FUSE 请求,后续的都通过内核返回了。因此如果没有特殊要求,建议所有测试都应携带 --direct=1 绕过内核页缓存,专注测试 FUSE 挂载点的能力。但如果希望尽可能贴近实际场景、充分利用空闲内存提升 I/O,此时可以去掉 --direct=1 来利用内核缓存。 |
ioengine | 如无特殊要求都应采用默认的 ioengine=psync。如果实际环境要运行的应用对接了 aio,那么不仅需要在 FIO 启用 ioengine=libaio,JuiceFS 挂载点也需要追加 -o async_dio 参数来进行适配。 |
refill_buffers | 默认情况下,FIO 会在测试任务开始时创建用于生成测试文件的数据片段,并一直重用这些数据。使用这个参数后,会在每次 I/O 提交后重新生成数据,保证生成测试文件内容有充分的随机性。 |
end_fsync | 对于 JuiceFS,write 成功以后只是将数据提交到读写缓冲区,并不代表数据就上传到对象存储了,需要 close 或者 fsync 才能触发持久化。因此对于写测试,建议开启该参数,以准确反映 JuiceFS 的性能。 |
file_service_type | 用来定义测试任务中的文件选取方式,有 random、roundrobin、sequential 三种。在本章某些测试用例中使用了 file_service_type=sequential 来保证测试任务及时关闭文件、触发 JuiceFS 将写入数据持久化,在这点上使用 end_fsync 更合适。 |
构造测试
本小节提供一系列 FIO 命令示范,帮助你按照自己的实际环境构造测试。
如果测试集中的文件可以读写复用,那么建议先安排写测试,生成的文件正好可以用于后续的读测试。
顺序写测试:
# 顺序写 1 个大文件
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=1 \
--nrfiles=1 \
--size=1G
# 并发顺序写 1 个大文件,因此 16 线程一共写 16 个大文件
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=16 \
--nrfiles=1 \
--size=1G
# 并发顺序写多个大文件,并发度 16,每个线程写入 64 个大文件
fio --name=big-write --directory=/mnt/fio --group_reporting \
--rw=write \
--direct=1 \
--bs=4m \
--end_fsync=1 \
--numjobs=16 \
--nrfiles=64 \
--size=1G
顺序读测试:
# 测试之前根据需要,可以选择清空本地数据缓存,以及内核缓存
rm -rf /var/jfsCache/*/raw
sysctl -w vm.drop_caches=3
# 顺序读 1 个大文件
fio --name=big-read-single --directory=/jfs/fio --group_reporting \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=1 \
--nrfiles=1 \
--size=1G
# 顺序读多个大文件
fio --name=big-read-multiple --directory=/jfs/fio --group_reporting \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=1 \
--nrfiles=64 \
--size=1G
# 并发顺序读多个大文件,线程数 64,每个线程读 64 个文件
fio --name=big-read-multiple-concurrent --group_reporting \
--directory=/jfs/fio \
--rw=read \
--direct=1 \
--bs=4m \
--numjobs=64 \
--nrfiles=64 \
--openfiles=1 \
--size=1G
如果你的场景需要构造随机读写测试,也可以参考上方的测试命令,需要修改的只有以下参数:
- 使用
rw=[randread|randwrite]来代表随机读和随机写; - 将
bs按需设置为 4k~128k,或按照真实业务场景的写入大小来设定。
测试不同的缓冲区大小
缓冲区几乎是对 JuiceFS 性能影响最大的参数,在顺序读写场景下,必须设置合适大小的缓冲区,才能获得理想的性能。本组测试关注不同大小的缓冲区对性能的影响,在不同配置的挂载点上,用 FIO 模拟不同并发负载,分别测得单个挂载点的吞吐。
简单来说,对于大文件顺序读写场景,在一定范围内,缓冲区越大性能就越好。如果你的场景正是顺序读写,那么推荐将 --buffer-size 至少设置为 1024。
测试环境
不同的对象存储性能差异可能会非常巨大,因此本文给出的测试结果均为参考,不代表或保证你的环境一定能测得相似的性能。本组测试的环境信息如下:
- JuiceFS 挂载点都部署在 GCP,机型为 c3-highmem-176,拥有 176 核 CPU、700G 内存、200Gbps 网卡。实际测试中客户端并不需要占用大量资源,选用溢出的配置只是为了避免网卡或内存成为瓶颈、影响测试。
- 测试使用 FIO 3.28;
- 客户端挂载配置中,除了缓冲区设置大小不一致,还会根据对象存储的延迟情况来调整并发:如果延迟较低(30ms 左右),可以采用比较低并发,如果延迟较高(100ms-400ms),则需要根据情况增大并发,避免对象的高延迟影响吞吐。本次测试中,GCS 的延迟达到 100ms-400ms,因此各组测试中挂载点还根据现场情况调整了并发度(
--max-uploads和--max-downloads)。
顺序写
对应的 FIO 配置:
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=write
bs=4M
filesize=1G
directory=/jfs/fio-dir

顺序读
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=read
bs=4M
filesize=1G
directory=/jfs/fio-dir

随机写
随机读写暂时还不是 JuiceFS 的强项,并且性能也很大程度取决于元数据延迟和对象存储延迟。并且由于 I/O 粒度小,反而和缓冲区大小没有特别大关系。因此这里只给出启用了客户端写缓存(也就是 --writeback)情况下的随机写结果,供有需要的用户参考,不进行随机读测试。
[global]
stonewall
group_reporting
openfiles=1
end_fsync=1
ioengine=sync
rw=write
bs=4M
filesize=1G
directory=/jfs/fio-dir

测试不同块大小
这一组测试主要目的是展示不同块大小(--block-size)下 JuiceFS 的性能,因此所有挂载点均默认的 JuiceFS 挂载参数,并没有经过挂载参数预调优,而是按照上手指南中教程操作创建的默认挂载点。
另外,由于本测试使用默认配置创建的 JuiceFS 云服务的文件系统,启用了 Zstandard 进行压缩,所以在下面各个测试任务中都加了 --refill_buffers 参数,让 FIO 生成的数据尽可能随机且没有规律,生成数据的压缩比很低,效果尽可能接近于实际业务场景中性能较差的情况。换言之,在实际业务中,JuiceFS 的表现大多好于本测试的性能指标。如果希望查看调优后的结果,请关注「测试不同的缓冲区大小」
综合来看,4M 的性能是最佳的,更大或更小都会在不同场景下引起一定的性能倒退。因此我们建议如无特殊需要,一律采用 4M 作为文件系统的块大小,如果确实需要修改块大小,务必提前进行测试验证、充分评估性能是否满足实际场景需要。
测试环境
不同的云服务商、对象存储、虚拟机类型、操作系统,其性能表现都会存在差异。本测试用例如无特殊说明,环境信息如下:
- JuiceFS 文件系统是基于 AWS us-west2 区的 S3 创建(创建方法请查看 上手指南);
- 机型是 c5d.18xlarge EC2 实例(72 CPU,144G RAM),Ubuntu 18.04 LTS (Kernel 4.15.0) 系统,选择 c5d.18xlarge 因为它有 25Gbit 网络,同时可以启用 Elastic Network Adapter(ENA),将 S3 的带宽提升至 25Gbps,保证测试中 JuiceFS 不会受网络带宽限制。
- 测试使用 FIO 3.1;
- 使用默认配置挂载 JuiceFS(挂载方法请查看上手指南)。
大文件
在日志收集、数据备份、大数据分析等很多场景中,都需要做大文件顺序读写,这也是 JuiceFS 适用的典型场景。
注意:此处需要事先创建不同块大小的 JuiceFS 文件系统并进行挂载,在测试脚本中对 --directory 参数换成对应的 JuiceFS 挂载点。
大文件顺序读�
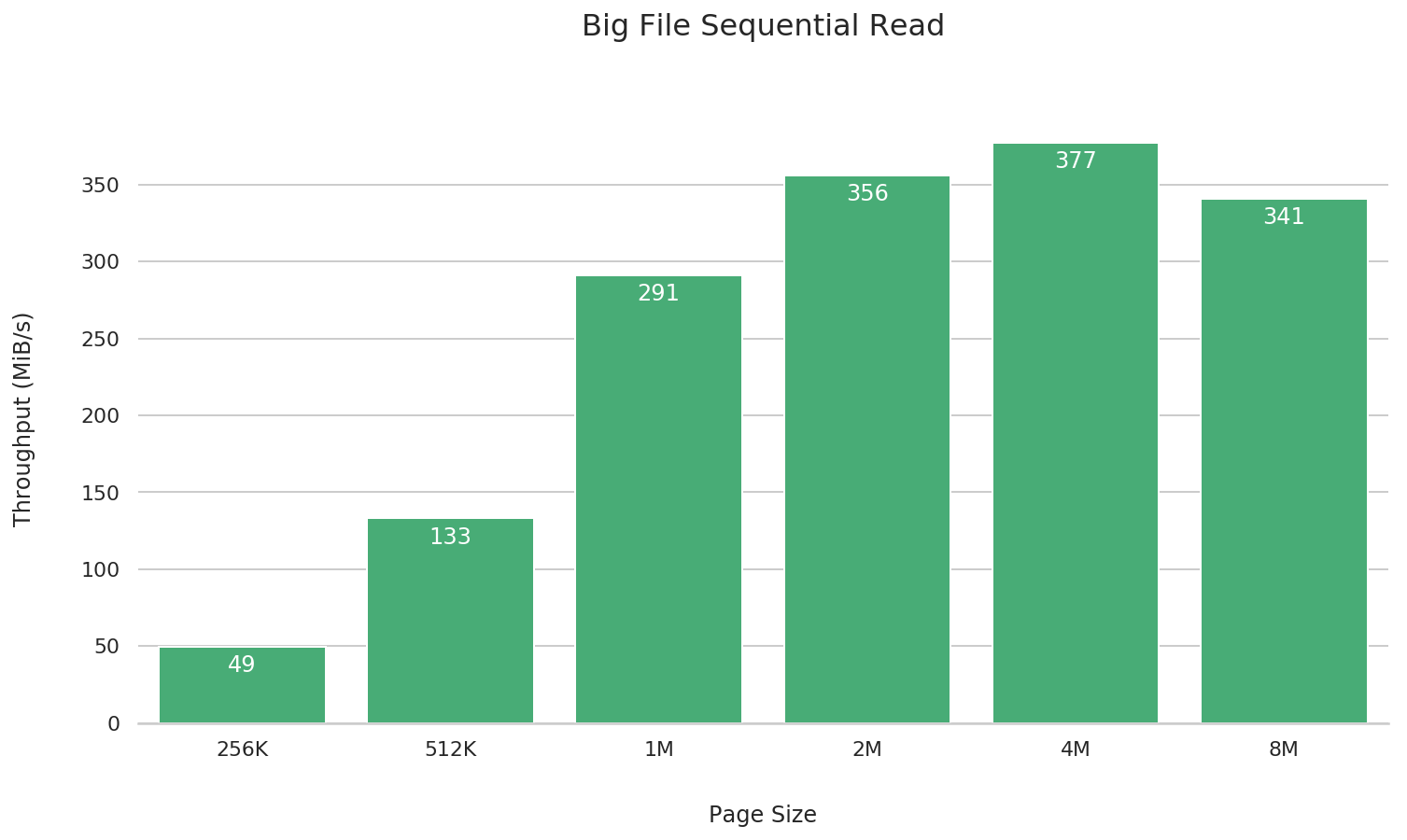
fio --name=big-file-sequential-read \
--directory=/jfs \
--rw=read --refill_buffers \
--bs=256k --size=4G
大文件顺序写
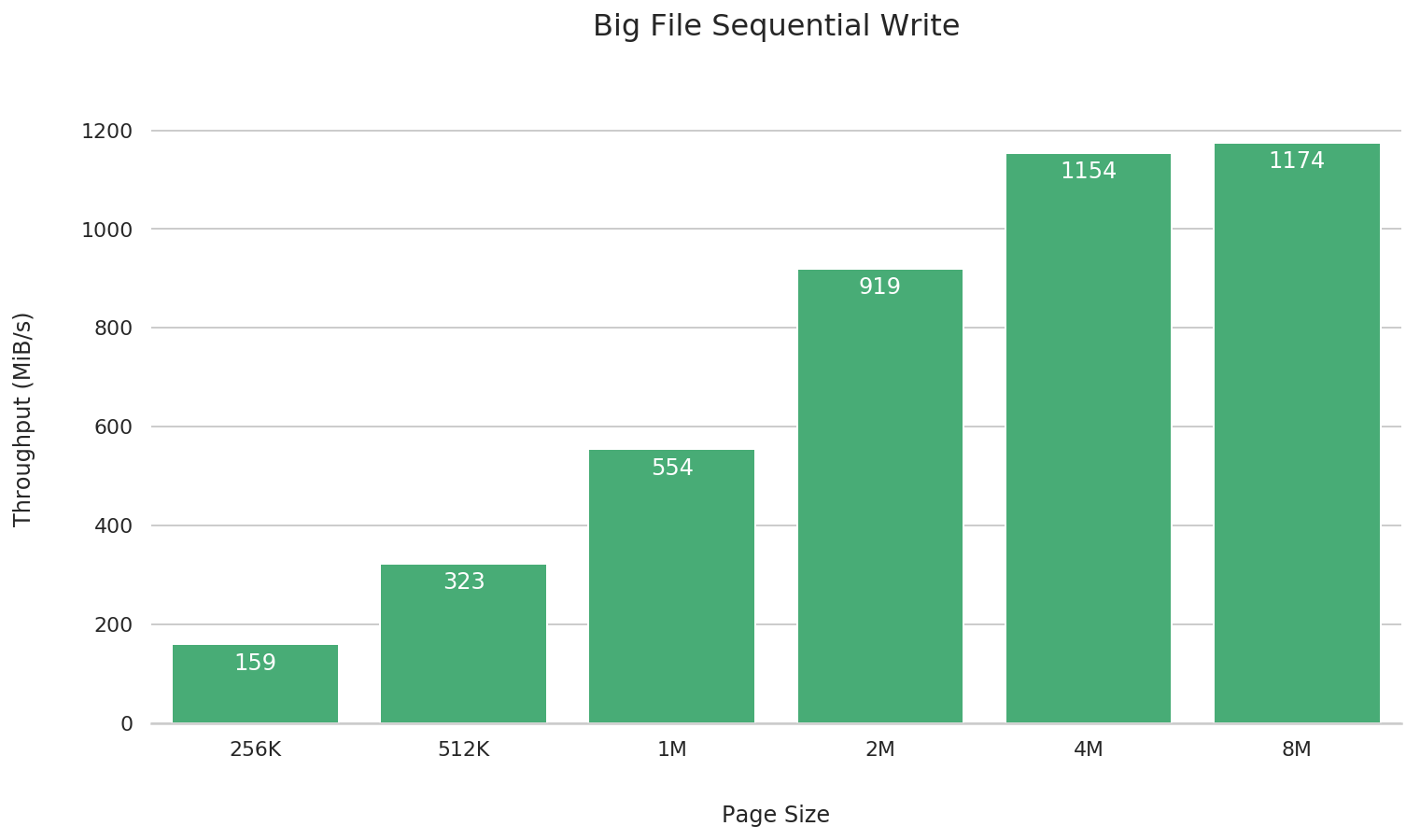
fio --name=big-file-sequential-write \
--directory=/jfs \
--rw=write --refill_buffers \
--bs=256k --size=4G
大文件并发读
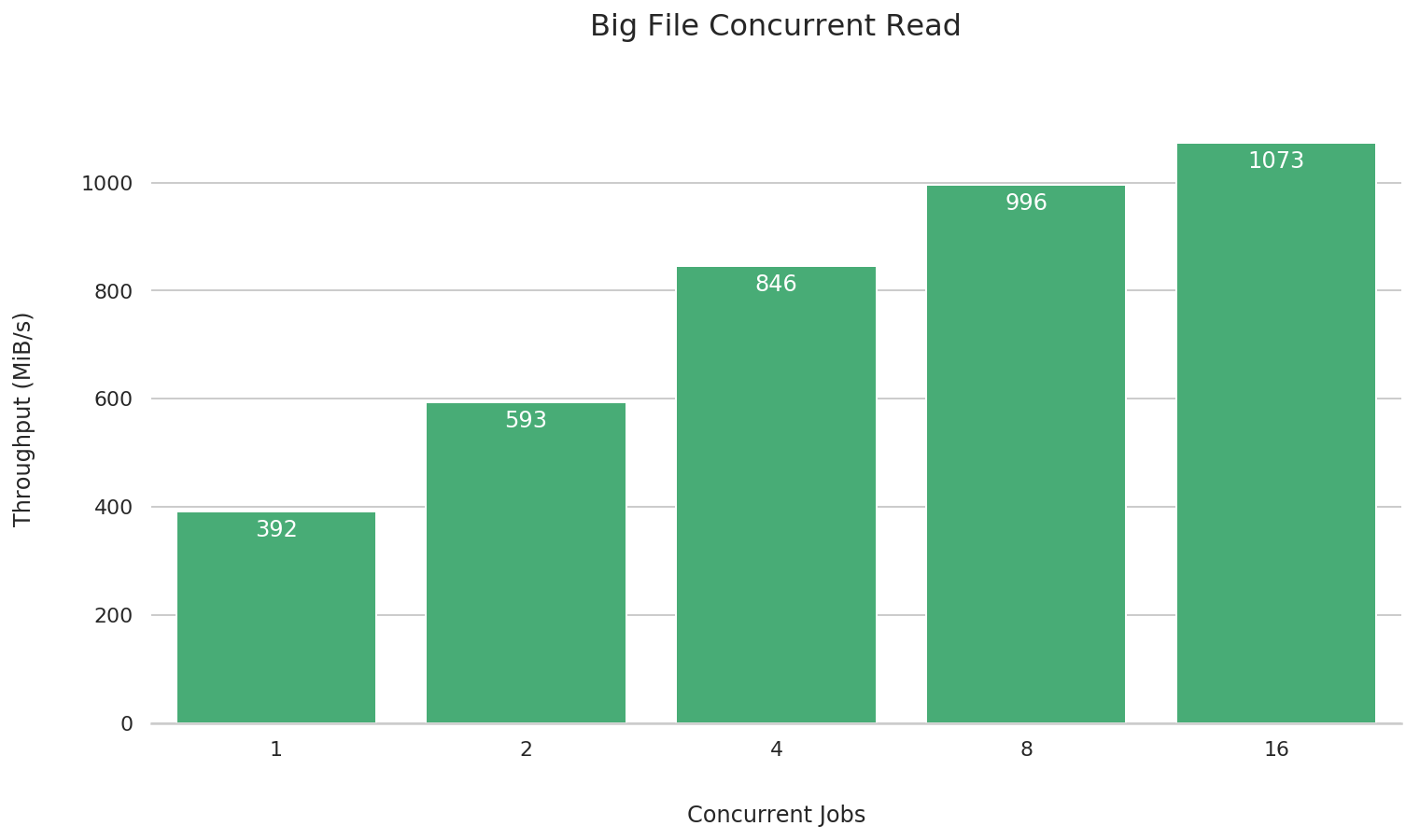
fio --name=big-file-multi-read \
--directory=/jfs \
--rw=read --refill_buffers \
--bs=256k --size=4G \
--numjobs={1, 2, 4, 8, 16}
大文件并发写
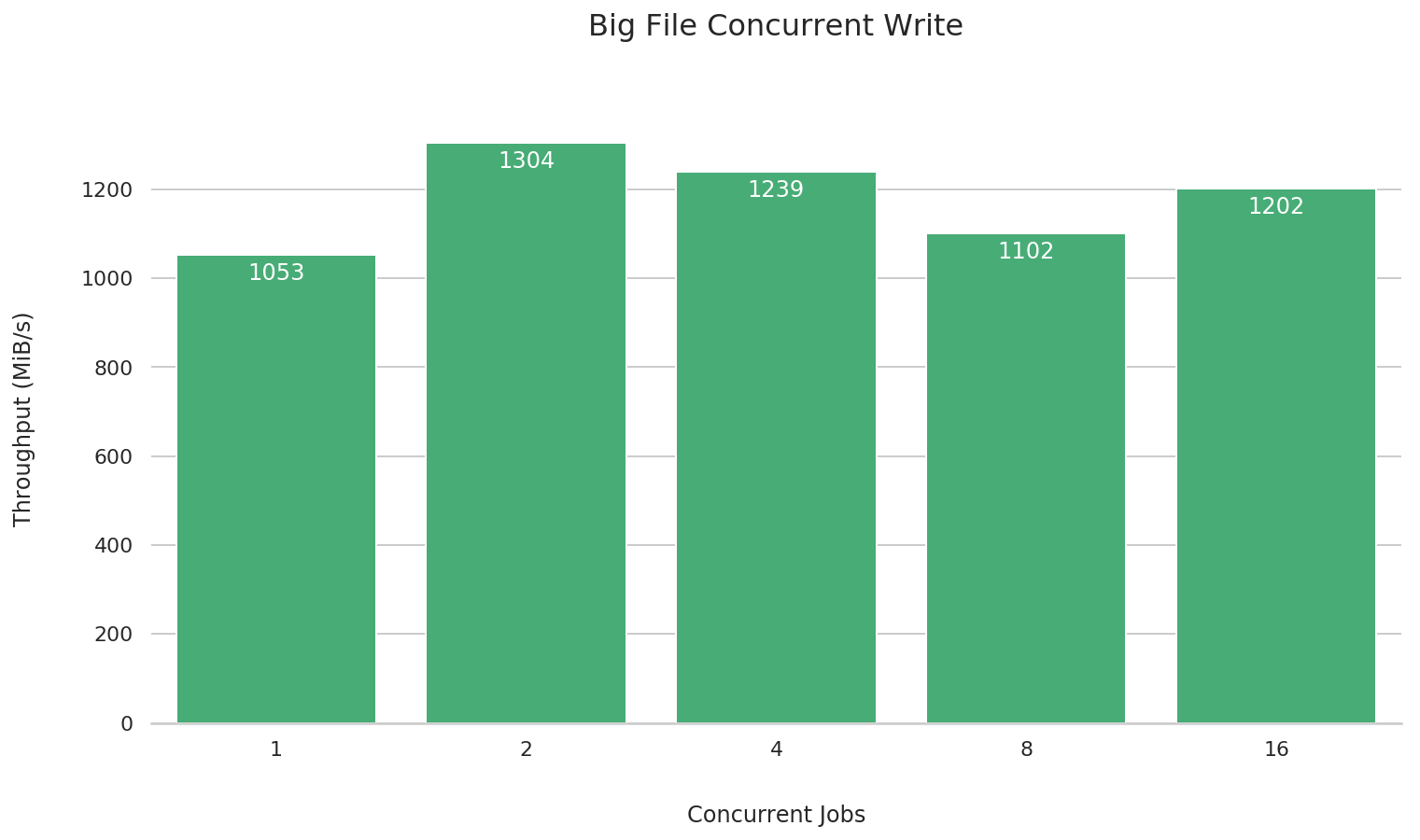
fio --name=big-file-multi-write \
--directory=/jfs \
--rw=write --refill_buffers \
--bs=256k --size=4G \
--numjobs={1, 2, 4, 8, 16}
大文件随机读
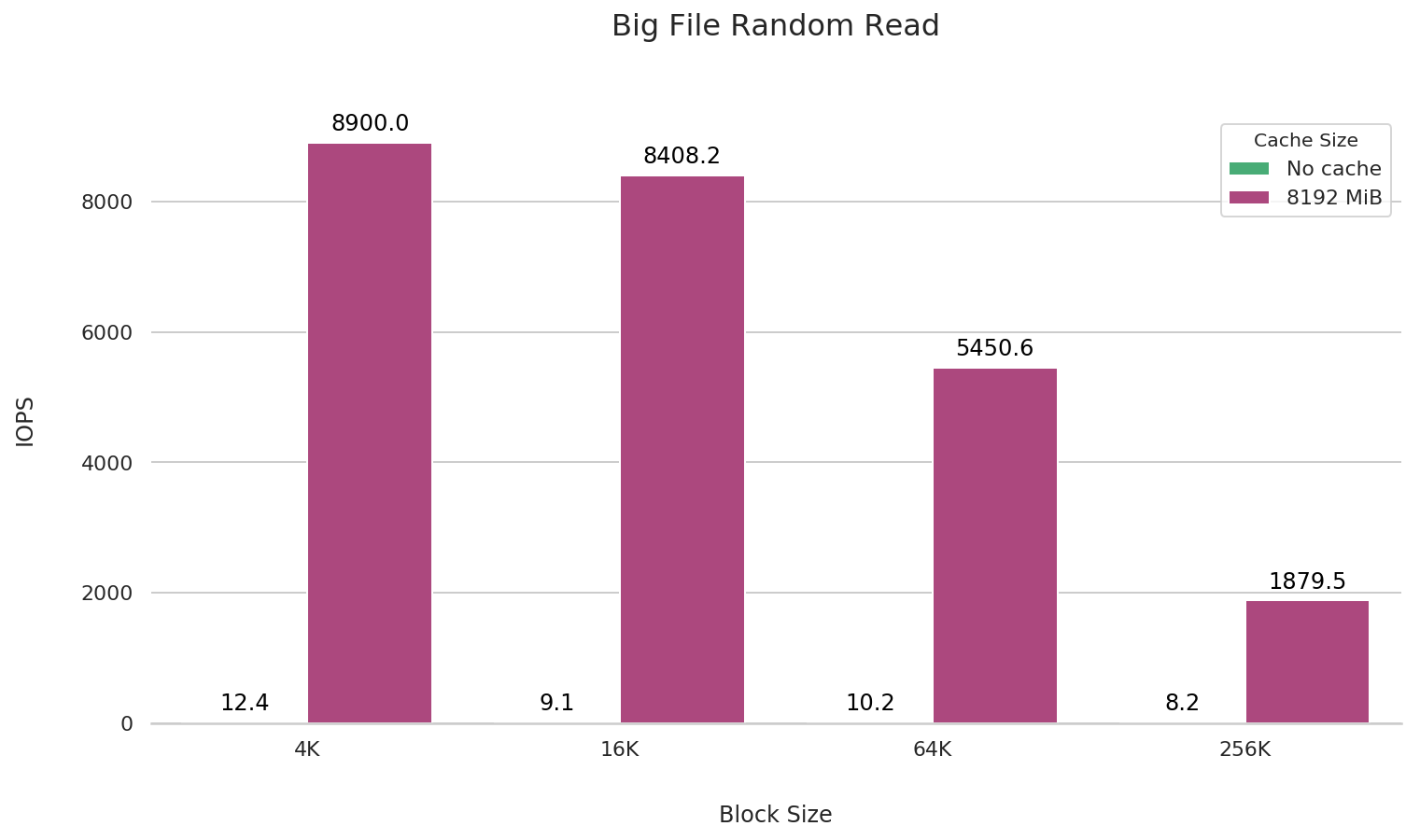
fio --name=big-file-rand-read \
--directory=/jfs \
--rw=randread --refill_buffers \
--size=4G --filename=randread.bin \
--bs={4k, 16k, 64k, 256k} --pre_read=1
sync && echo 3 > /proc/sys/vm/drop_caches
fio --name=big-file-rand-read \
--directory=/jfs \
--rw=randread --refill_buffers \
--size=4G --filename=randread.bin \
--bs={4k, 16k, 64k, 256k}
为了精准地测试大文件随机读的性能,在这里我们先使用 fio 将文件预��读取一遍,然后清除内核缓存(sysctl -w vm.drop_caches=3),接着使用 fio 进行随机读的性能测试。
在大文件随机读的场景,为了获得更好的性能,建议将挂载参数的缓存大小设置为大于将要读取的文件大小。
大文件随机写
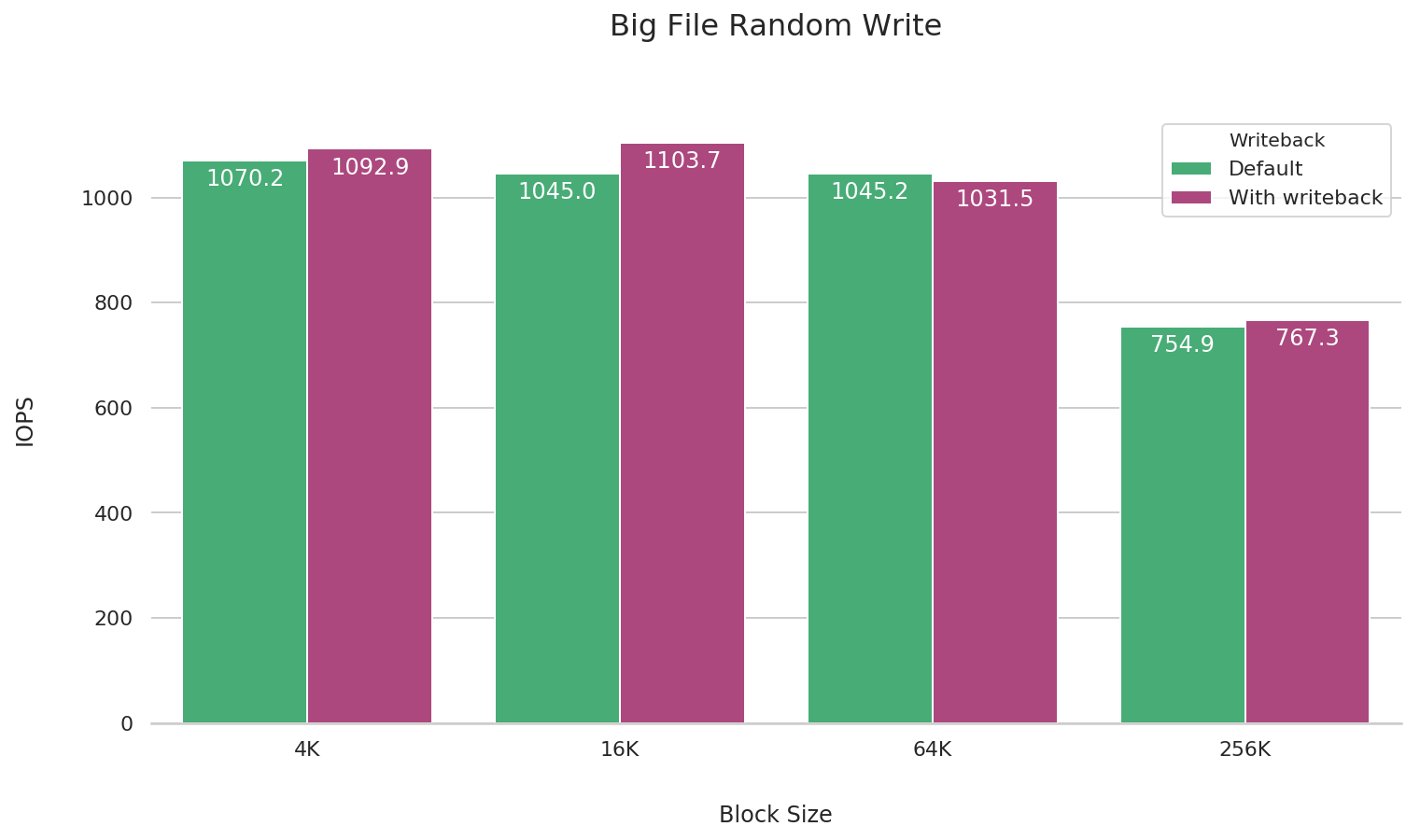
fio --name=big-file-random-write \
--directory=/jfs \
--rw=randwrite --refill_buffers \
--size=4G --bs={4k, 16k, 64k, 256k}
小文件
小文件读
JuiceFS 在挂载时默认开启 1G 本地数据缓存,缓存能大幅提升小文件读取的 IOPS。可以在挂载 JuiceFS 时加上 --cache-size=0 的参数关闭缓存,下面做了有无缓存时的性�能对比。
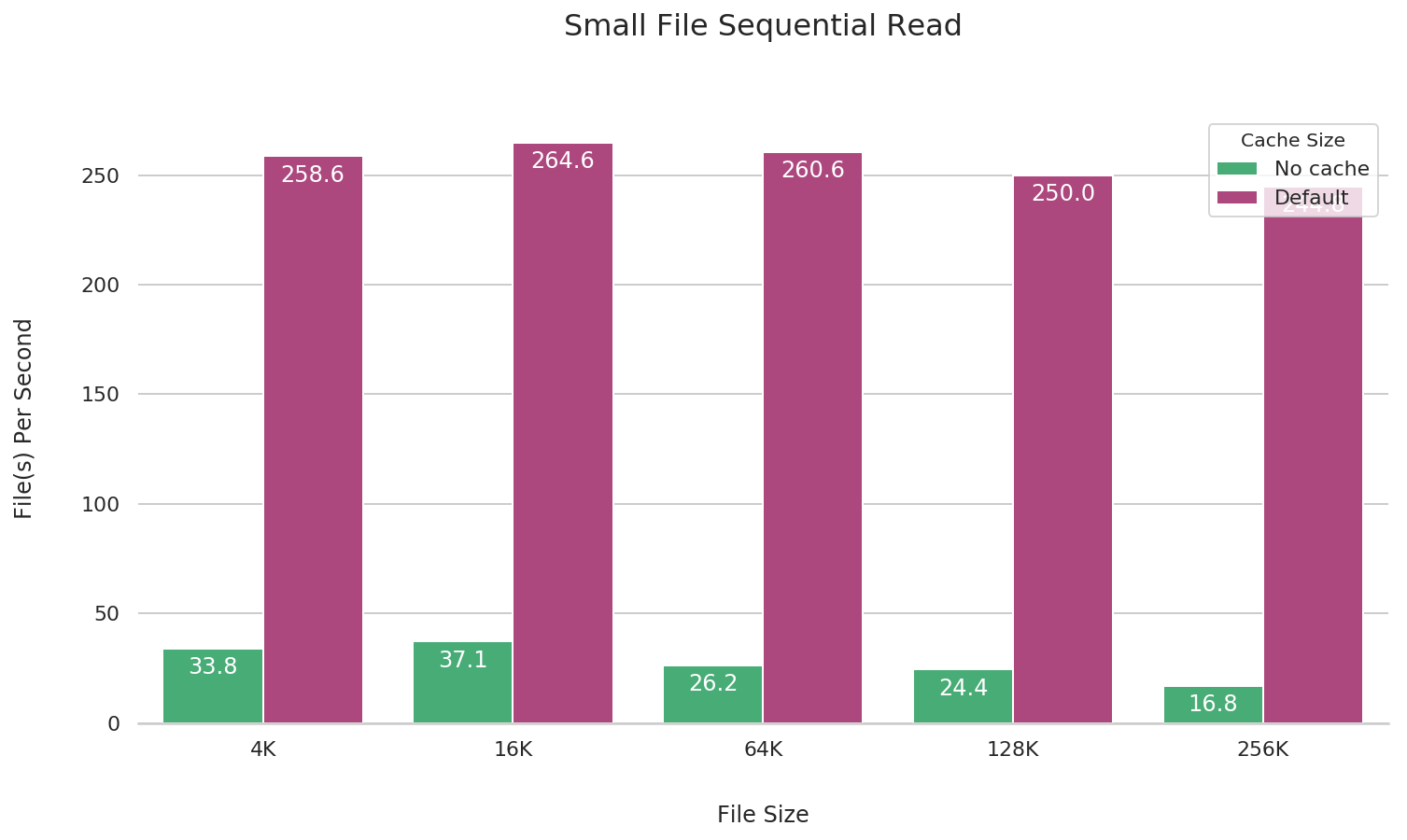
fio --name=small-file-seq-read \
--directory=/jfs \
--rw=read --file_service_type=sequential \
--bs={file_size} --filesize={file_size} --nrfiles=1000
小文件写
在 JuiceFS 挂载时加上 --writeback 参数客户端写缓存(详细说明可以查看 缓存 一章),可以对小文件顺序写性能大幅提升,下面做了对比测试。
在默认的 fio 测试行为中会把文件的关闭操作留在任务最后执行,这样在分布式文件系统中存在因网络异常等因素丢失数据的可能。所以我们在 fio 的测试参数中使��用了 --file_service_type=sequential 参数,这样 fio 会在测试任务中保证写完一个文件(执行 flush & close,把数据全部写入对象存储)再进行下一个文件。
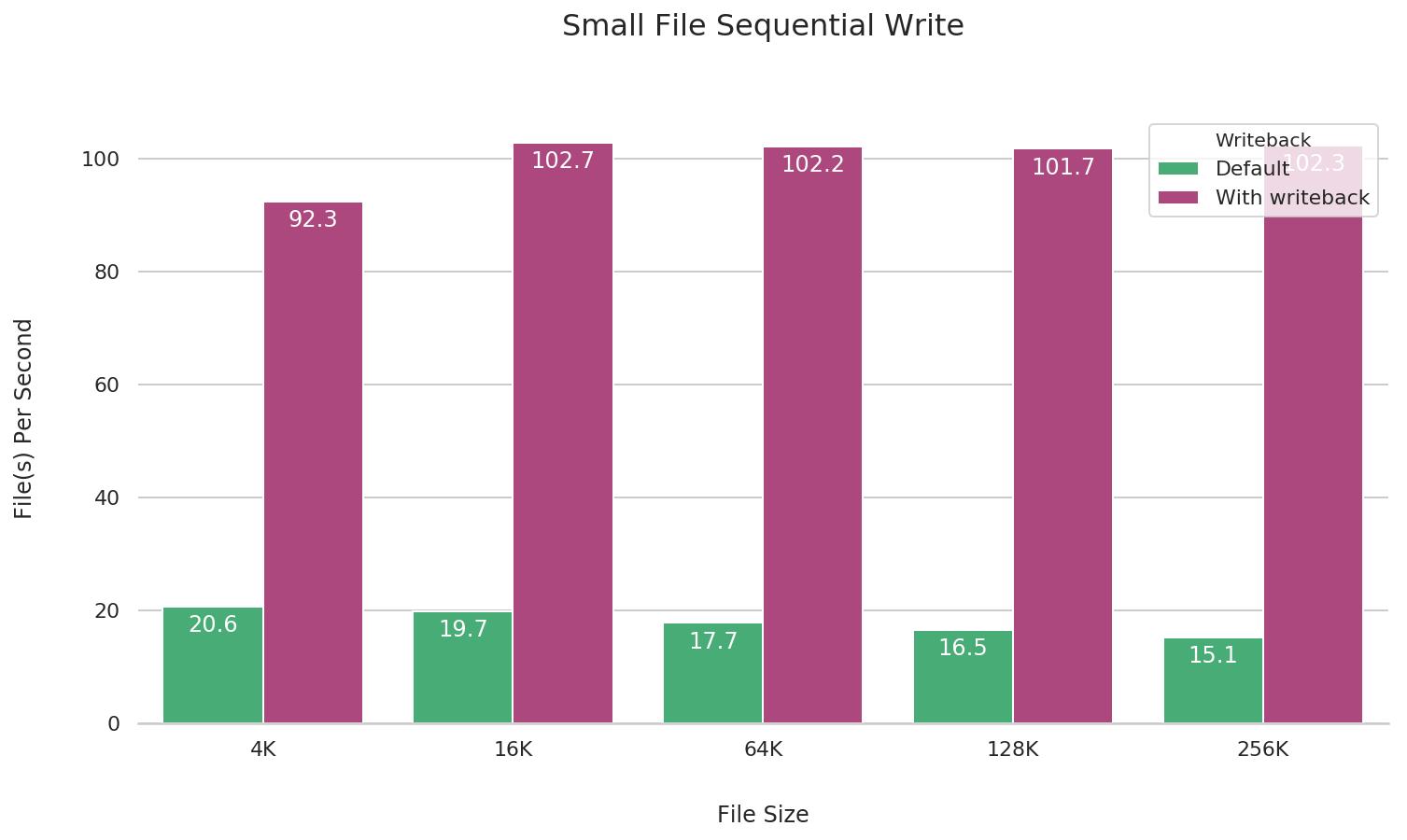
fio --name=small-file-seq-write \
--directory=/jfs \
--rw=write --file_service_type=sequential \
--bs={file_size} --filesize={file_size} --nrfiles=1000
小文件并发读
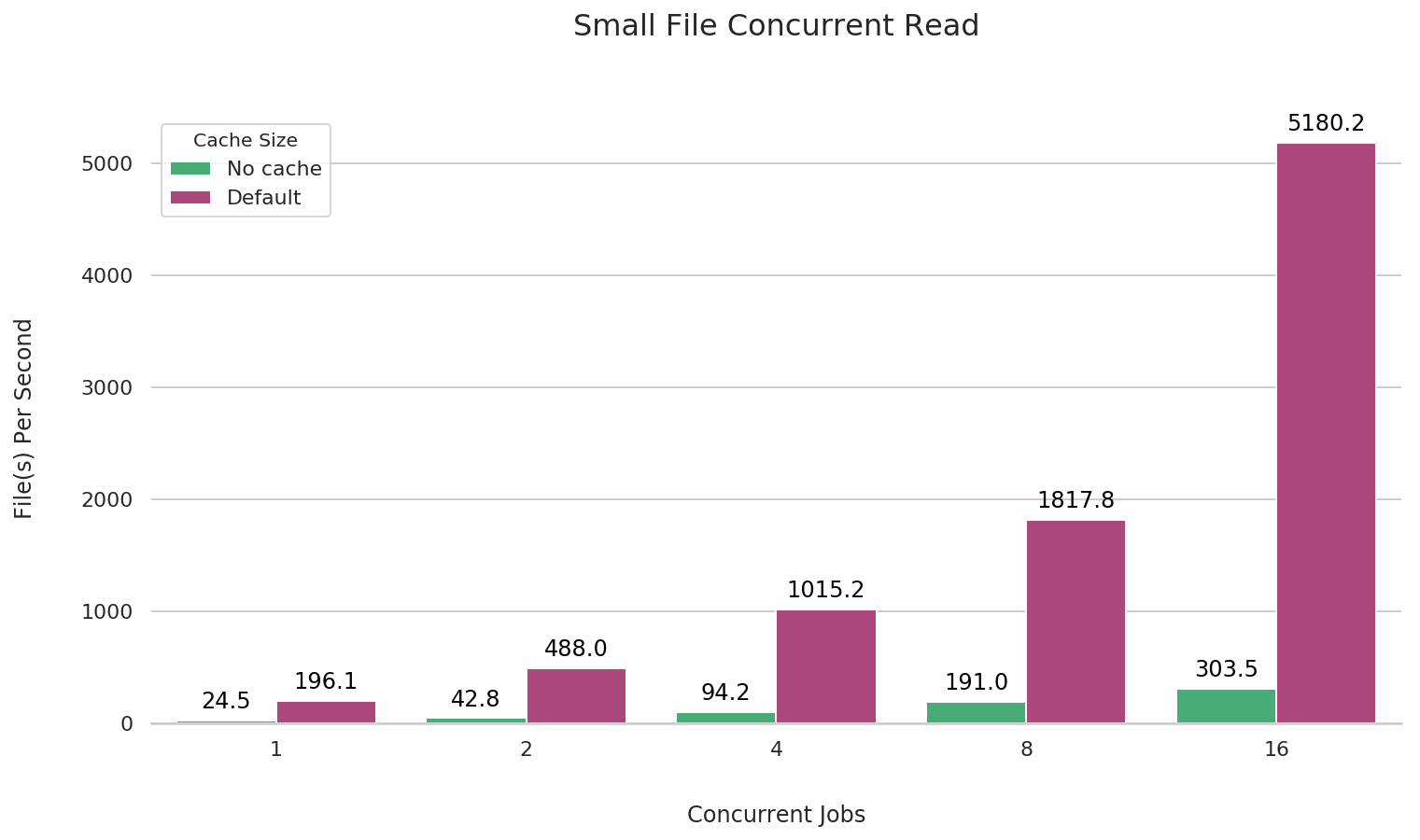
fio --name=small-file-multi-read \
--directory=/jfs \
--rw=read --file_service_type=sequential \
--bs=4k --filesize=4k --nrfiles=1000 \
--numjobs={1, 2, 4, 8, 16}
小文件并发写
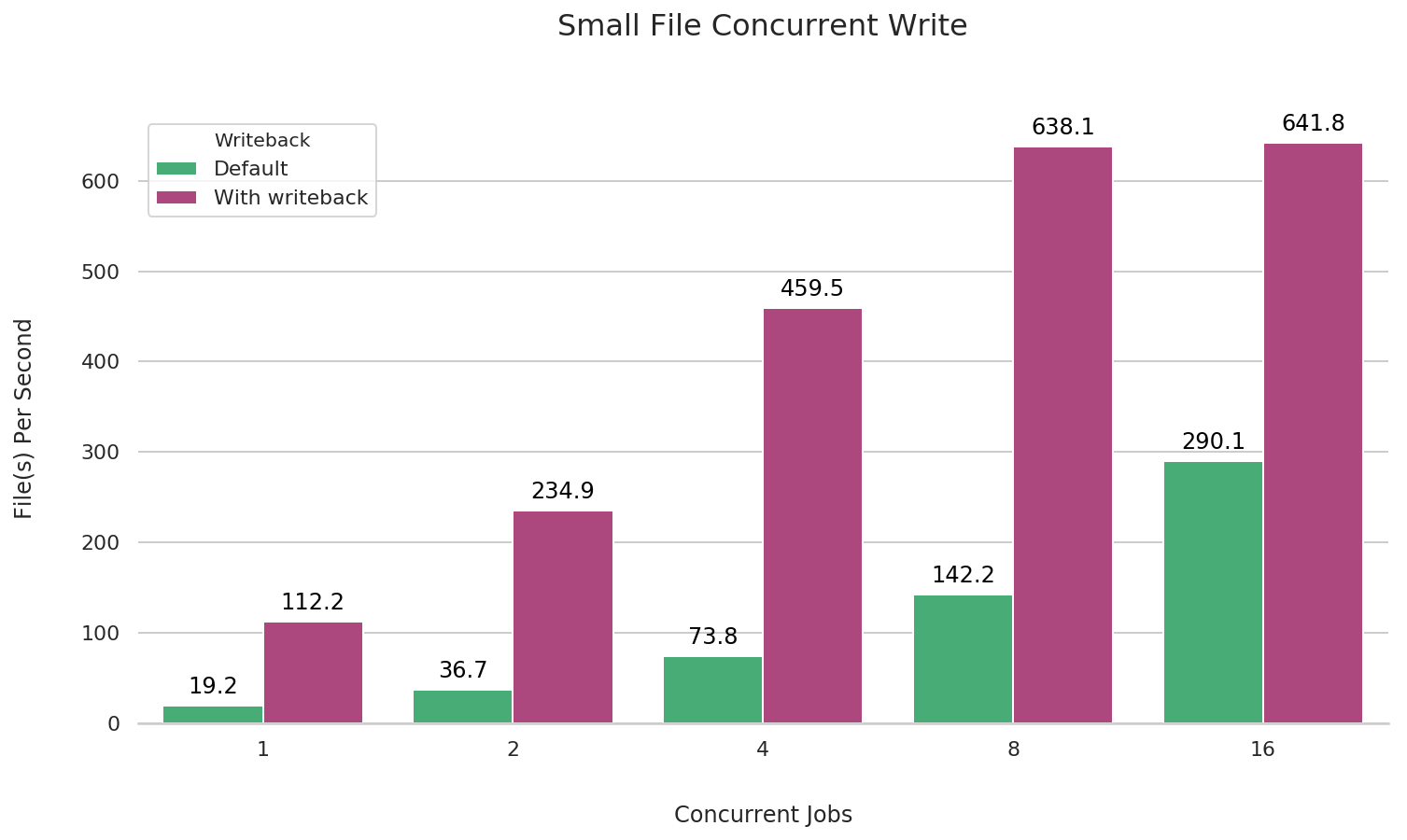
fio --name=small-file-multi-write \
--directory=/jfs \
--rw=write --file_service_type=sequential \
--bs=4k --filesize=4k --nrfiles=1000 \
--numjobs={1, 2, 4, 8, 16}


