问题排查方法
客户端日志
对于宿主机挂载,Linux、macOS 客户端日志默认为 /var/log/juicefs.log,Windows 则是 C:\Users\<username>\AppData\Local\juicefs.log。当使用 JuiceFS 出现问题时,首先查看客户端日志。而如果日志中没有明显异常,可以为挂载命令添加 --verbose 参数(支持平滑重新挂载),输出更为丰富的 DEBUG 日志。
不同 JuiceFS 客户端获取日志的方式不同,以下分别介绍。
宿主机挂载点
在挂载命令中用 --log=<log_path> 指定日志储存路径,默认为 /var/log/juicefs.log 或 ~/.juicefs/log/juicefs.log,具体取决于执行用户。
可以用 grep 命令过滤不同等级日志做性能分析或者故障诊断:
grep 'ERROR\|FATAL' /var/log/juicefs.log
Kubernetes CSI 驱动
根据你使用的 JuiceFS CSI 驱动版本会有不同的获取日志的方式,参考 CSI 驱动文档。
S3 网关
S3 网关仅支持在前台运行,因此客户端日志会直接输出到终端。如果你是在 Kubernetes 中部署 S3 网关,需要查看对应 pod 的日志。
Hadoop Java SDK
使用 JuiceFS Hadoop Java SDK 的应用进程(如 Spark executor)的日志中会包含 JuiceFS 客户端日志,因为和应用自身产生的日志混杂在一起,需要通过 juicefs 关键词来过滤筛选。
文件系统访问日志
和 juicefs.log 不一样,访问日志负责记录对文件系统的访问(比如打开文件、读取文件、关闭文件),遇到性能问题时,收集并分析访问日志会非常有帮助。
在挂载点上运行下方命令,就能实时打印文件系统的访问日志:
# 假设挂载点为 /jfs
cat /jfs/.accesslog
# 收集访问日志
cat /jfs/.accesslog > access.log
如果不方便登入客户端环境,也可以直接在控制台收集并下载访问日志:
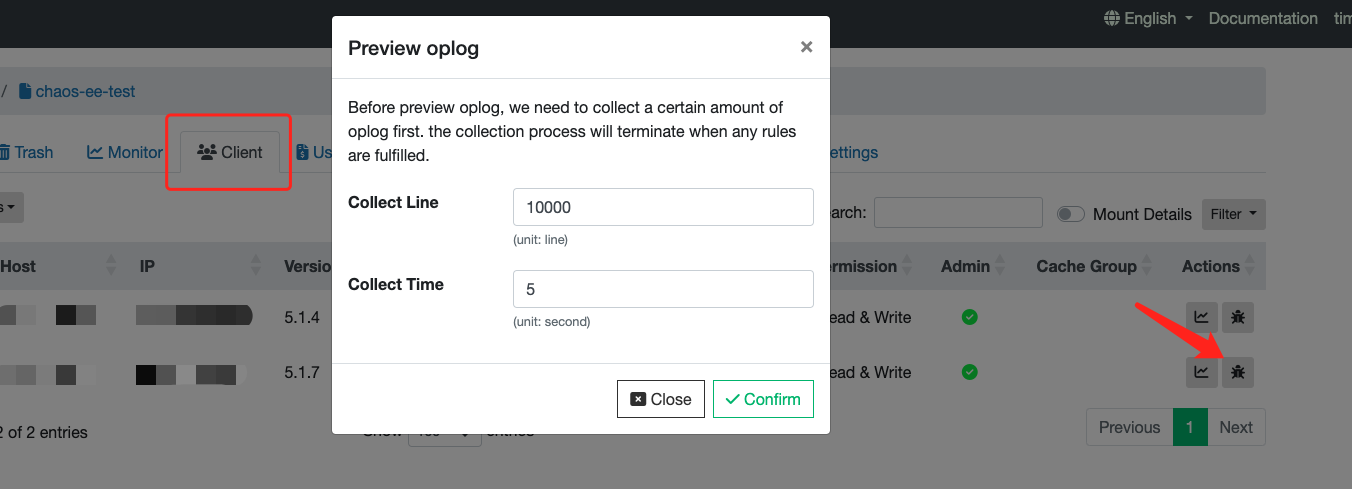
对于 Kubernetes CSI 驱动场景,需要进入 Mount Pod 内运行相同的命令:
# 首先找到应用容器对应的 mount pod,默认名称中会含有 PVC 名,根据实际情况调整:
kubectl -n kube-system get pod | grep juicefs | grep [pvc-name]
# 也可以罗列出所有 mount pod,然后自行查找判断:
kubectl -n kube-system get pod -l app.kubernetes.io/name=juicefs-mount
# 钻进容器,打印访问日志:
kubectl -n kube-system exec juicefs-[node]-pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373 -- cat /jfs/pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373/.oplog
- JuiceFS 中的虚拟文件大小都为 0,不必感到奇怪,直接运行
cat命令就能打印相关内容; .accesslog又名.oplog,这两个虚拟文件的作用相同;- 如果错过了操作时机,没能捕捉到关键的访问日志,可以迅速
cat .ophistory来尝试提取,这个虚拟文件里滚动保存了少量历史日志,不超过 15M; - 对于 Hadoop SDK,需要在客户端配置中使用
juicefs.access-log配置项,指定访问日志输出的路径,默认不输出访问日志。
文件系统访问日志中记录了操作类型、UID/GID、文件 inode 及其花费的时间。访问日志可以有多种用途,如性能分析、审计、故障诊断。下方将会介绍的 juicefs profile 命令正是根据访问日志统计各种文件系统操作,在命令行汇总呈现统计信息。你可以使用该命令快速统计并判断出你的应用对于文件系统的访问模式,评估访问性能。
日志格式
我们选取了一些常见的文件系统操作,将访问日志的样例与格式说明在下方进行示范,日志中用 inode 来表示文件,如果需要从 inode 反查文件详细信息,可以使用 juicefs info [INODE]。
# 大体上格式如下,不同类型日志稍有区别:
# [UID,GID,PID] [调用方法] [输入参数(不同方法参数有别)]: [OK] [排查信息] <耗时(秒)>
# open,输入参数 (inode, flags)
[uid:0,gid:0,pid:1631098] open (38597810,0x8000): OK (38597810,[-rw-r--r--:0100644,1,0,0,1650446639,1650446639,1650446639,212]) (direct_io:0,keep_cache:1) [handle:00007869] <0.010293>
# read,输入参数 (inode, size, offset, file-handler)
[uid:0,gid:0,pid:0] read (148199375,69632,1439510528,18333): OK (69632) <0.001047>
# getattr,输入参数 (inode)
[uid:0,gid:0,pid:1631098] getattr (1): OK (1,[drwxrwxrwx:0040777,19977521,0,0,1634886025,1663052916,1663052916,9265059409920]) <0.000002>
# statfs,输入参数 (inode)
[uid:0,gid:0,pid:1240206] statfs (1): OK (47474945257472,62476217520128,1165873,4293801422) <0.000345>
# setattr,输入参数 (inode, setmask, mode)
[uid:0,gid:0,pid:1631098] setattr (45758905,0x1,[mode=-rw-r--r--:00644;]): OK (45758905,[-rw-r--r--:0100644,1,0,0,1664165438,1664165438,1664165438,4096]) <0.011076>
# create,输入参数 (parent-inode, name, mode, umask)
[uid:0,gid:0,pid:1631098] create (1,.temp.sh.swp,-rw-------:0100600,00000,0x280C2): OK (45758905,[-rw-------:0100600,1,0,0,1664165438,1664165438,1664165438,0]) [handle:00007868] <0.011117>
# write,输入参数 (inode, size, offset, file-handler)
[uid:0,gid:0,pid:1631098] write (45758905,4096,0,18333): OK <0.000040>
# unlink,输入参数 (parent-inode, name)
[uid:0,gid:0,pid:1631098] unlink (1,temp.sh~): OK <0.011033>
# flush,输入参数 (inode, file-handler)
[uid:0,gid:0,pid:1631098] flush (45758905,18333): OK <0.030459>
实时统计数据
JuiceFS 在每个挂载点的根目录下提供了一个文件名为 .stats 的纯文本格式虚拟文件,记录了实时的统计数据。在进行故障诊断和分析的时候,查看这个文件里面的统计数据将会非常有帮助。这些统计数据也可以通过 JSON API 或者 Prometheus API 收集,参考「监控」文档。
不同 JuiceFS 客户端获取实时统计数据的方式不同,以下分别介绍。
宿主机挂载点
假设 JuiceFS 挂载点为 /jfs:
# 查看 CPU 和内存占用:
cat /jfs/.stats | grep usage
# 查看运行时间:
cat /jfs/.stats | grep uptime
# 查看对象存储的各项操作请求计数:
cat /jfs/.stats | grep object
# 查看对象存储读写数据量:
cat /jfs/.stats | grep _bytes
Kubernetes CSI 驱动
在 mount pod 内,JuiceFS 挂载点路径为 /jfs/<pv_volumeHandle>,示范命令如下:
# 首先找��到应用容器对应的 mount pod,默认名称中会含有 PVC 名,根据实际情况调整:
kubectl -n kube-system get pod | grep juicefs | grep [pvc-name]
# 也可以罗列出所有 mount pod,然后自行查找判断:
kubectl -n kube-system get pod -l app.kubernetes.io/name=juicefs-mount
# 钻进容器,打印访问日志:
kubectl -n kube-system exec juicefs-[node]-pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373 -- cat /jfs/pvc-d4b8fb4f-2c0b-48e8-a2dc-530799435373/.stats
实时性能监控
基于上方介绍的「文件系统访问日志」和「实时统计数据」,JuiceFS 客户端提供 profile 和 stats 两个子命令来对性能数据进行可视化呈现。
juicefs profile
juicefs profile 会对「文件系统访问日志」进行汇总,根据日志的统计信息显示各个文件系统调用的耗时:
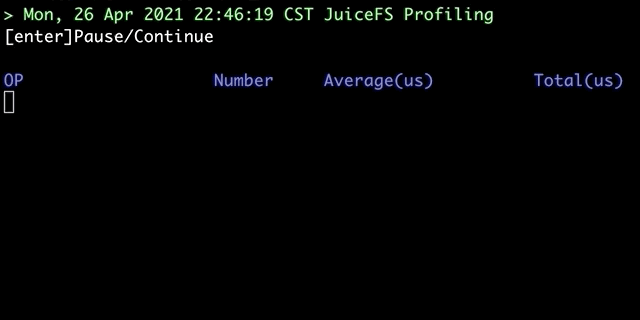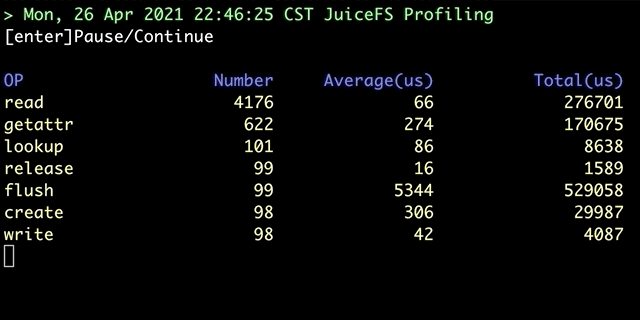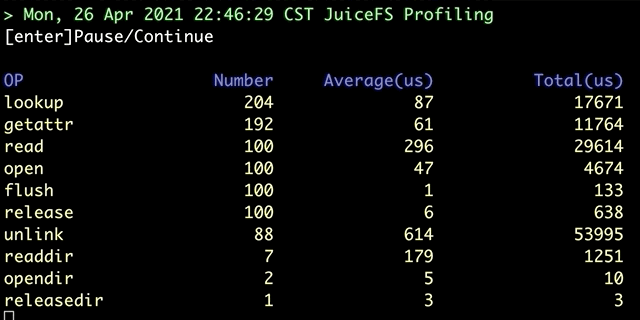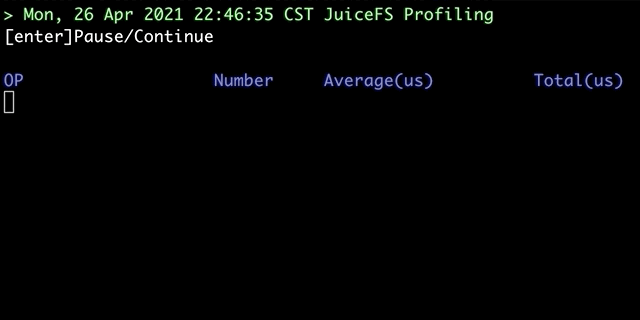
该命令提供实时和回放两种诊断模式,实时模式下会现场读取挂载点下的文件系统访问日志来进行计算,而回放模式则可以对预先收集的日志进行回放分析。
实时模式示范如下:
juicefs profile MOUNTPOINT
在调试或分析性能问题时,更实用的做法通常是先记录访问日志,然后重放:
# 预先收集日志
cat /jfs/.accesslog > /tmp/op.log
# 性能问题复现后,重放日志,分析各调用耗时,找出性能瓶颈
juicefs profile /tmp/op.log
juicefs stats
juicefs stats 命令通过读取 JuiceFS 客户端的性能数据,以类似 Linux dstat 工具的形式实时打印各个指标的每秒变化情况。
最基础的用法如下:
$ juicefs stats /jfs
------usage------ ----------fuse--------- ----meta--- -blockcache remotecache ---object--
cpu mem buf | ops lat read write| ops lat | read write| read write| get put
0.0% 124M 32M| 0 0 0 0 | 0 0 | 0 0 | 0 0 | 0 0
输出中展示了客户端的基础资源用量,以及各个环节的吞吐,可以通过他直观看出目前 JuiceFS 客户端的数据流入流出,判断 JuiceFS 是否在正常工作。
如果需要进一步展示 各个外部系统的请求延迟情况,可以增加 -l 1 参数:
$ juicefs stats -l 1 /jfs
---------usage--------- ----------fuse--------- ----------meta--------- ----blockcache--- ------------------------------remotecache------------------------------ ------------------------object-----------------------
cpu mem buf cache| ops lat read write| ops lat send recv| read write evict| read rd_c lat write wr_c lat db_c lat pr_c lat wb_c lat | get get_c lat put put_c lat del del_c lat
0.0% 124M 32M 44M| 0 0 0 0 | 0 0 0 0 | 0 0 0 | 0 0 0 0 0 0 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 0
特别地,如果需要细致排查读放大的原因,可以修改 --schema 参数,增加读放大相关指标(具体指标含义请查看 [juicefs stats](../reference/command_reference.md#stats)):
$ juicefs stats -l 1 --schema="ufmcaro" /jfs
---------usage--------- ----------fuse--------- ----------meta--------- ----blockcache--- -------------readahead------------ ------------------------------remotecache------------------------------ ------------------------object-----------------------
cpu mem buf cache| ops lat read write| ops lat send recv| read write evict| used winvl wclup wshrk wfree wclos| read rd_c lat write wr_c lat db_c lat pr_c lat wb_c lat | get get_c lat put put_c lat del del_c lat
0.0% 124M 32M 44M| 0 0 0 0 | 0 0 0 0 | 0 0 0 | 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 0
用 pprof 获取运行时信息
JuiceFS 客户端默认会通过 pprof 在本地监听一个 TCP 端口用以获取运行时信息,如 Goroutine 堆栈信息、CPU 性能统计、内存分配统计。你可以通过挂载点下的 .config 文件查看当前 JuiceFS 客户端监听的具体端口号:
# 假设挂载点是 /jfs
$ cat /jfs/.config | grep 'DebugAgent'
"DebugAgent": "127.0.0.1:6064",
默认 pprof 监听的端口号范围是从 6060 开始至 6099 结束,从上面的示例中可以看到实际的端口号是 6064。在获取到监听端口号以后就可以通过 http://localhost:<port>/debug/pprof 地址查看所有可供查询的运行时信息,一些重要的运行时信息如下:
- Goroutine 堆栈信息:
http://localhost:<port>/debug/pprof/goroutine?debug=1 - CPU 性能统计:
http://localhost:<port>/debug/pprof/profile?seconds=30 - 内存分配统计:
http://localhost:<port>/debug/pprof/heap
为了便于分析这些运行时信息,可以将它们保存到本地,例如:
curl 'http://localhost:<port>/debug/pprof/goroutine?debug=1' > juicefs.goroutine.txt
curl 'http://localhost:<port>/debug/pprof/profile?seconds=30' > juicefs.cpu.pb.gz
curl 'http://localhost:<port>/debug/pprof/heap' > juicefs.heap.pb.gz
你也可以使用 juicefs doctor 命令自动收集这些运行时信息并保存到本地,默认保存到当前目录下的 debug 目录中,例如:
juicefs doctor /jfs
关于 juicefs doctor 命令的更多信息,请查看命令参考。
如果你安装了 go 命令,那么可以通过 go tool pprof 命令直接分析,例如分析 CPU 性能统计:
$ go tool pprof 'http://localhost:<port>/debug/pprof/profile?seconds=30'
Fetching profile over HTTP from http://localhost:<port>/debug/pprof/profile?seconds=30
Saved profile in /Users/xxx/pprof/pprof.samples.cpu.001.pb.gz
Type: cpu
Time: Dec 17, 2021 at 1:41pm (CST)
Duration: 30.12s, Total samples = 32.06s (106.42%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 30.57s, 95.35% of 32.06s total
Dropped 285 nodes (cum <= 0.16s)
Showing top 10 nodes out of 192
flat flat% sum% cum cum%
14.73s 45.95% 45.95% 14.74s 45.98% runtime.cgocall
7.39s 23.05% 69.00% 7.41s 23.11% syscall.syscall
2.92s 9.11% 78.10% 2.92s 9.11% runtime.pthread_cond_wait
2.35s 7.33% 85.43% 2.35s 7.33% runtime.pthread_cond_signal
1.13s 3.52% 88.96% 1.14s 3.56% runtime.nanotime1
0.77s 2.40% 91.36% 0.77s 2.40% syscall.Syscall
0.49s 1.53% 92.89% 0.49s 1.53% runtime.memmove
0.31s 0.97% 93.86% 0.31s 0.97% runtime.kevent
0.27s 0.84% 94.70% 0.27s 0.84% runtime.usleep
0.21s 0.66% 95.35% 0.21s 0.66% runtime.madvise
也可以将运行时信息导出为可视化图表,以更加直观的方式进行分析。可视化图表支持导出为多种格式,如 HTML、PDF、SVG、PNG 等。例如导出内存分配统计信息为 PDF 文件的命令如下:
导出为可视化图表功能依赖 Graphviz,请先将它安装好。
go tool pprof -pdf 'http://localhost:<port>/debug/pprof/heap' > juicefs.heap.pdf
关于 pprof 的更多信息,请查看官方文档。
JuiceFS Doctor
如果上边的排查手段未能帮助解决你的问题,Juicedata 团队可能会要求你用 juicefs doctor 这个命令收集更为丰富的排查信息,将结果发给我们进行排查解决。


