Using Kerberos
Kerberos is a authentication protocol widely supported in the Hadoop ecosystem.
Without Kerberos, HDFS Client cannot authenticate the current user, the HADOOP_USER_NAME environment variable can be used to configure user name (can be set to superuser), but this brings security issues. By using Hadoop in Secure Mode and enable Kerberos, users accessing HDFS is authenticated using Kerberos.
Enable Kerberos for JuiceFS
JuiceFS>=4.8 Hadoop Java SDK brings support to Kerberos
-
Preparation
-
Install KDC if you haven't already.
-
Create a
meta.keytabfile for JuiceFS, replaceVOL_NAMEwith:kadmin.local -q "addprinc -randkey meta/{VOL_NAME}"
kadmin.local -q "ktadd -norandkey -k meta.keytab meta/{VOL_NAME}"
-
-
Enable Kerberos support in JuiceFS console
-
Enable Kerberos support in the volume settings page, and then upload the previous created
meta.keytabfile.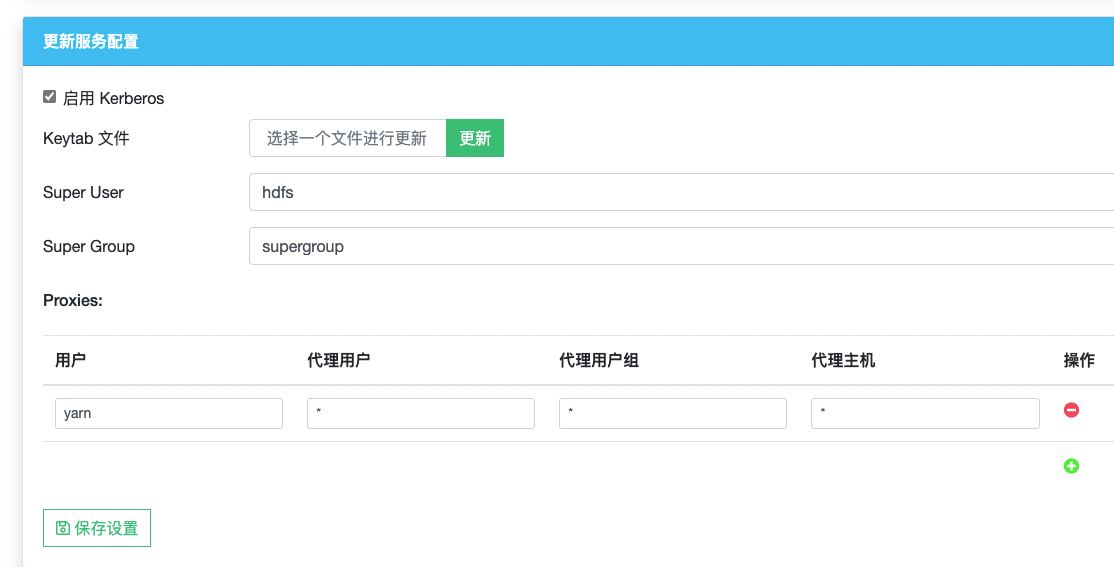
-
Superuser and Supergroup
With Kerberos enabled, you can configure superuser / supergroup in console. The configured value will overwrite
juicefs.superuserandjuicefs.supergroup. -
Optional: Proxy User
JuiceFS supports Proxy User as well, see HDFS Proxy User, and add proxyuser config when you need.
-
-
SDK Configuration
Add to
core-site.xml:<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>juicefs.server-principal</name>
<value>meta/_HOST</value>
<description>
The _HOST wildcard will expand into JuiceFS volume name at runtime.
Change to meta/{VOL_NAME} to use specific file system.
</description>
</property> -
Verify
-
Hadoop shell
# log in using kinit
kinit {your-client-principal}
# verify if JuiceFS works
hadoop fs -ls jfs://{VOL_NAME}/
# exit
kdestroy
# after logout, accessing files should fail with error: kerberos credential is needed
hadoop fs -ls jfs://{VOL_NAME}/ -
Spark
Needs to add the following config to Spark:
--conf spark.yarn.access.hadoopFileSystems
-
By default, Hadoop compute client uses /etc/krb5.conf to access KDC, if KDC config file is located elsewhere, add -Djava.security.krb5.conf=/path/to/conf to your Java arguments.

