Comparison of Metadata Performance between JuiceFS and HDFS, OSS
Background
Storage is the cornerstone of big data, and the Metadata of storage system is its core brain. The performance of Metadata is very important to the performance and expansion of the whole big data platform. We chose HDFS, OSS and JuiceFS to do metadata performance measurements together.
HDFS is a widely used big data storage system, which has been deposited and accumulated for more than ten years, and is the most suitable reference frame.
Object Storage, represented by Amazon S3 and Aliyun OSS, is also a candidate for big data platforms in the cloud, but it only has part of the functionality and semantics of HDFS, and its performance is not very good, so it is not widely used in practice. In this test object storage is represented by Aliyun OSS and other object storage is similar.
JuiceFS is a new player in the big data community, built specifically for big data in the cloud. It is a big data storage solution that conforms to the native features of the cloud. JuiceFS uses cloud-based object storage to store customer data content, and uses the JuiceFS metadata service and Java SDK to achieve full compatibility with HDFS, giving the same experience as HDFS without any changes to the data analysis component.
Test Method
Hadoop has a tool called NNBench that specifically measures the Metadata performance of a file system, and we used it to do this.
The original NNBench has some limitations, and we've made some adjustments:
- The single test task of the original NNBench is single-threaded and the resource utilization is low. We change it to multi-threaded, which can increase the concurrent pressure.
- The original NNBench used hostname as part of the pathname, without considering the problem of multiple concurrent tasks in the same host, which would result in multiple test tasks repeatedly creating and deleting files, which is not very true for big data workloads, instead, we use the sequence number of the Map to generate the pathname to avoid the conflict of multiple test tasks on a single host.
We used three Aliyun 4 core 16 GB virtual machines for the stress test. CDH 5 is a widely used Hadoop distribution, and we chose it as our test environment, with HDFS version 2.6. HDFS is a highly available configuration that uses three JournalNodes, and JuiceFS is a Raft group of three nodes. HDFS uses intranet IP, JuiceFS uses elastic IP, HDFS network performance will be better. OSS is accessed using an intranet interface.
Data Analysis
Let's start with the performance of HDFS:
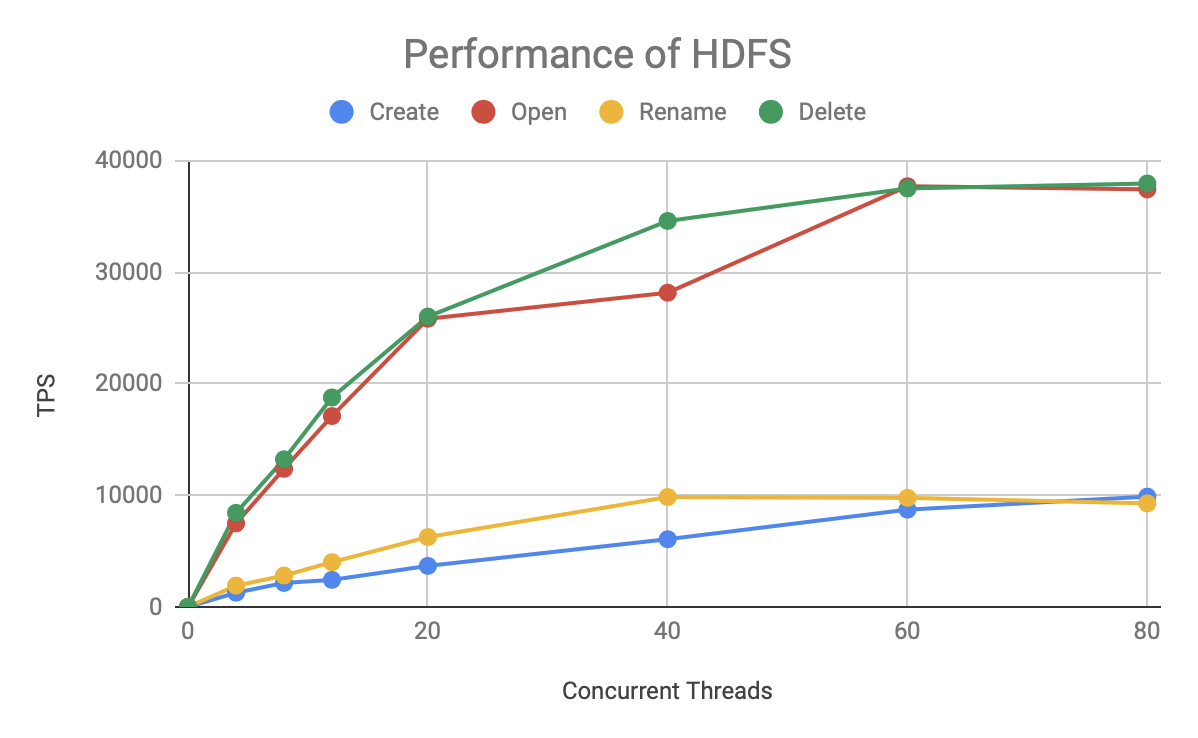
This graph depicts the number of requests (TPS) processed by HDFS per second as the number of concurrency increases. There are two findings:
- The Open / Read and Delete operations perform much better than the Create and Rename operations.
- Before the 20 concurrency, TPS increases linearly with the number of concurrency, after that the growth slows down to 60 concurrency that has reached the limit of TPS (full load).
Consider the performance of OSS:
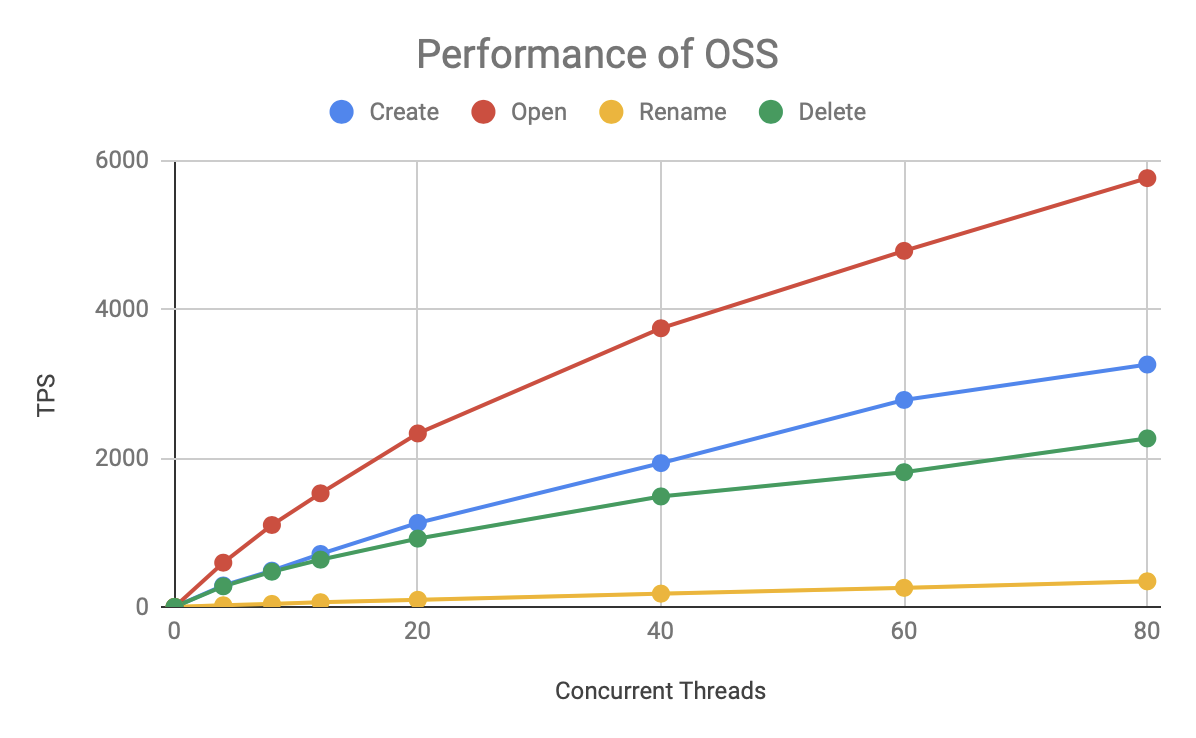
OSS is an order of magnitude slower than HDFS, but the speed of its various operations remains stable, and the total TPS increases with the number of concurrency, with no bottleneck under 80 concurrency. Due to the limitation of test resource, we can not know its upper limit by further pressure test.
Finally, take a look at JuiceFS'performance:
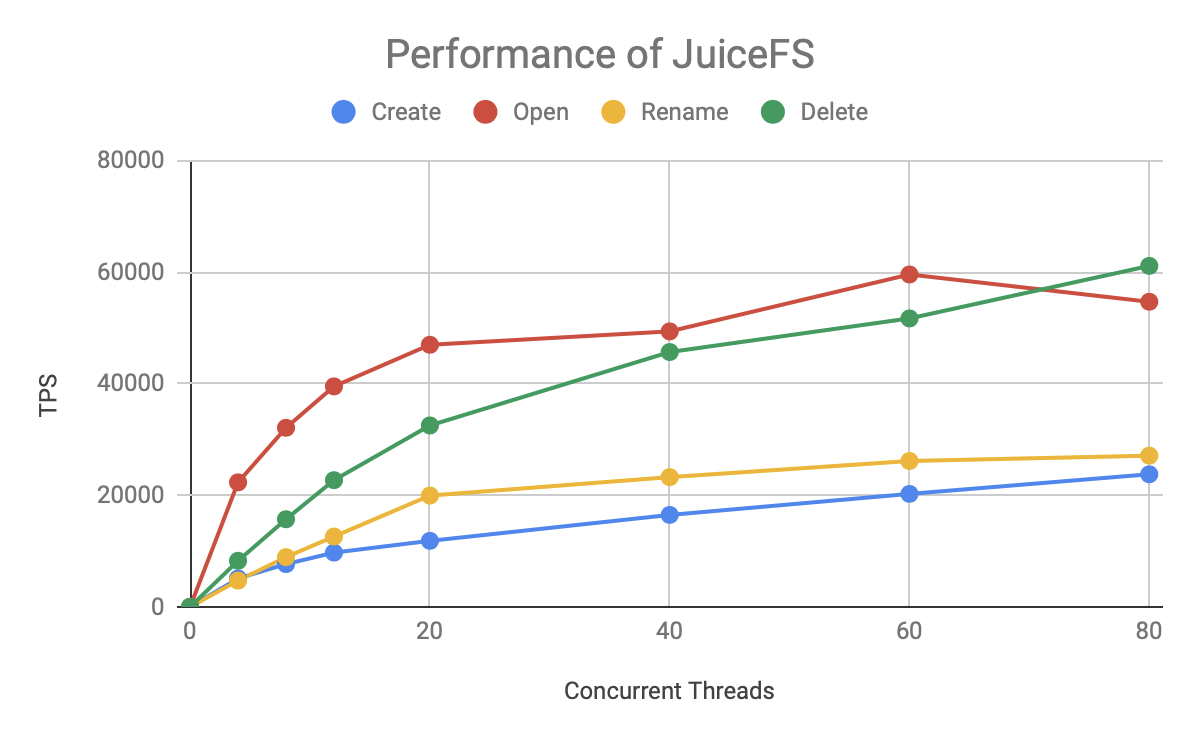
As you can see in figure, the overall trend is similar to HDFS, with Open / Read and Delete operations significantly faster than Create / Rename. The TPS of JuiceFS also kept thread growth basically within 20 concurrency, then slowed down and reached the peak at about 60 concurrency.
But the JuiceFS grew faster, with a higher ceiling.
Detailed Performance Comparison
To get a better sense of the performance differences between the three, let's put HDFS, Aliyun OSS, and JuiceFS together:
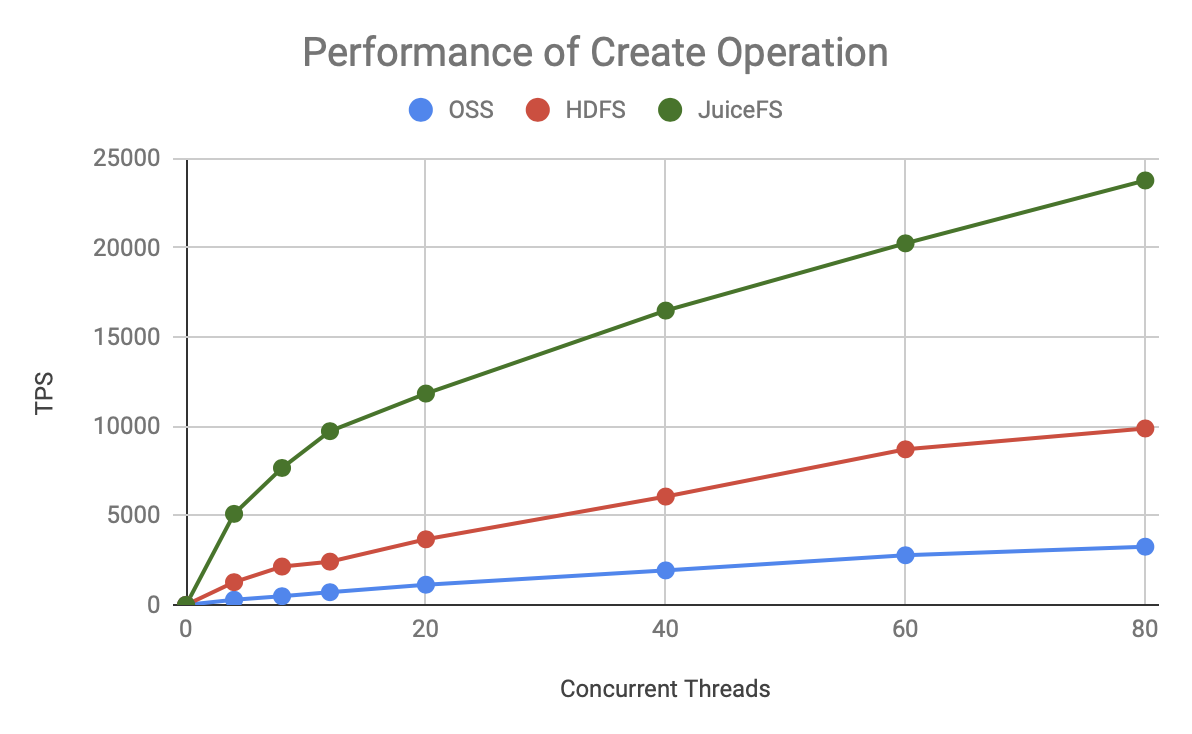
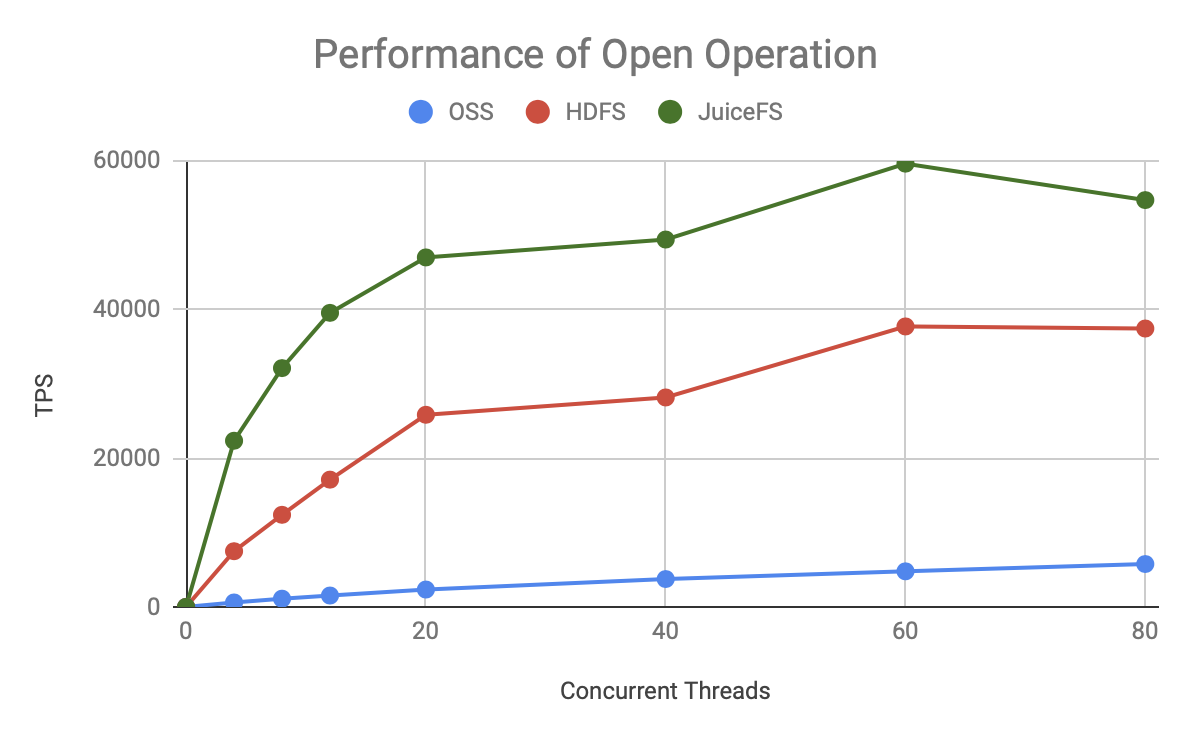
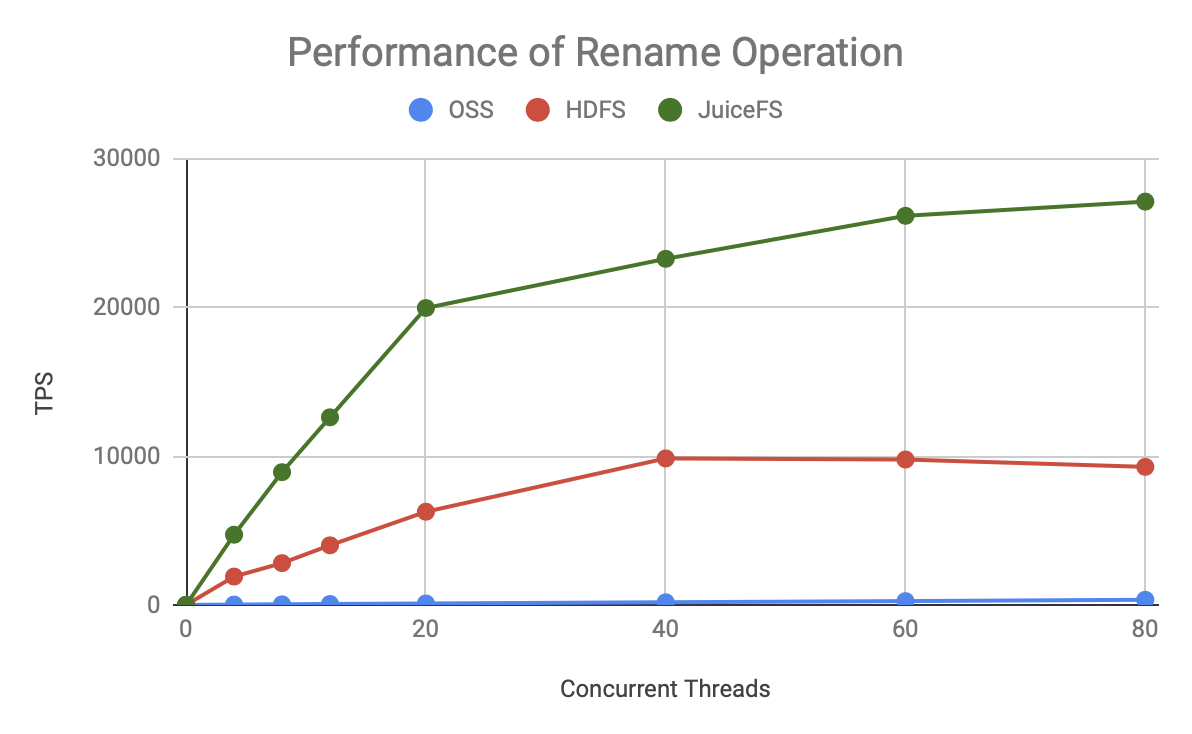
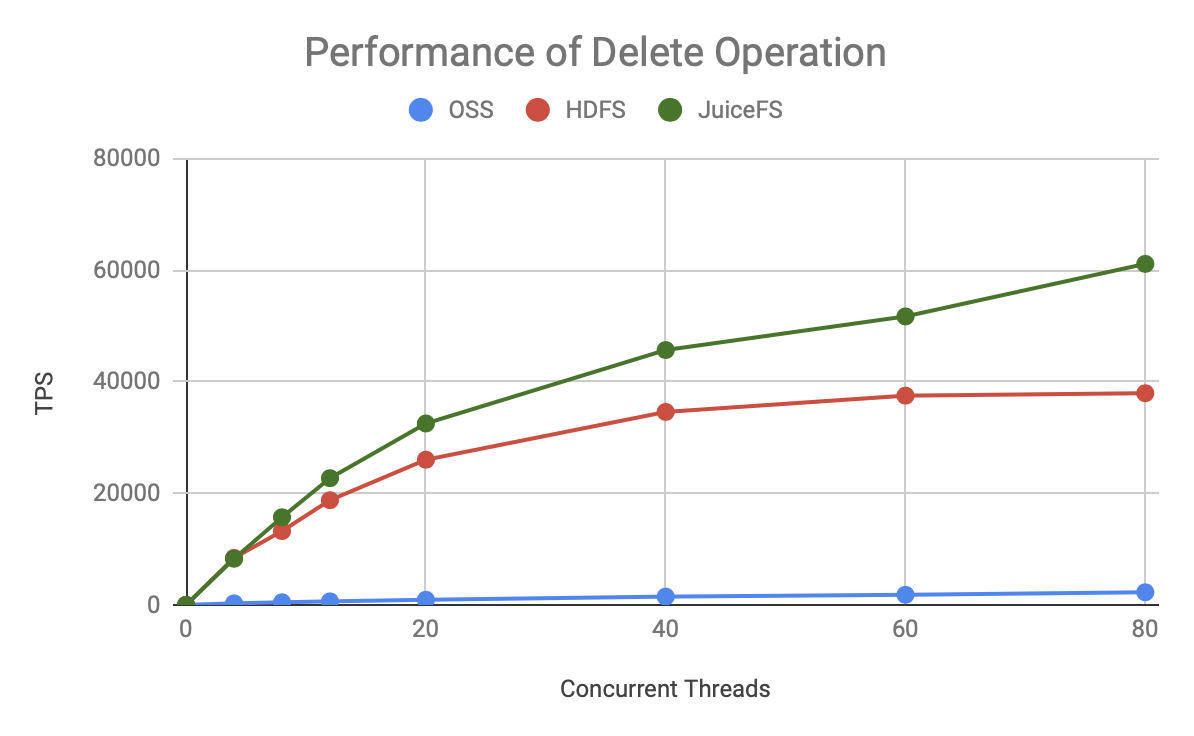
Thus, regardless of the metadata operation, the TPS of JuiceFS grows faster and has a higher upper bound than HDFS and OSS.
Conclusion
In general, when we look at the performance of a system, we focus on its operation delay (time consumed by a single operation) and throughput (processing capacity at full load) :
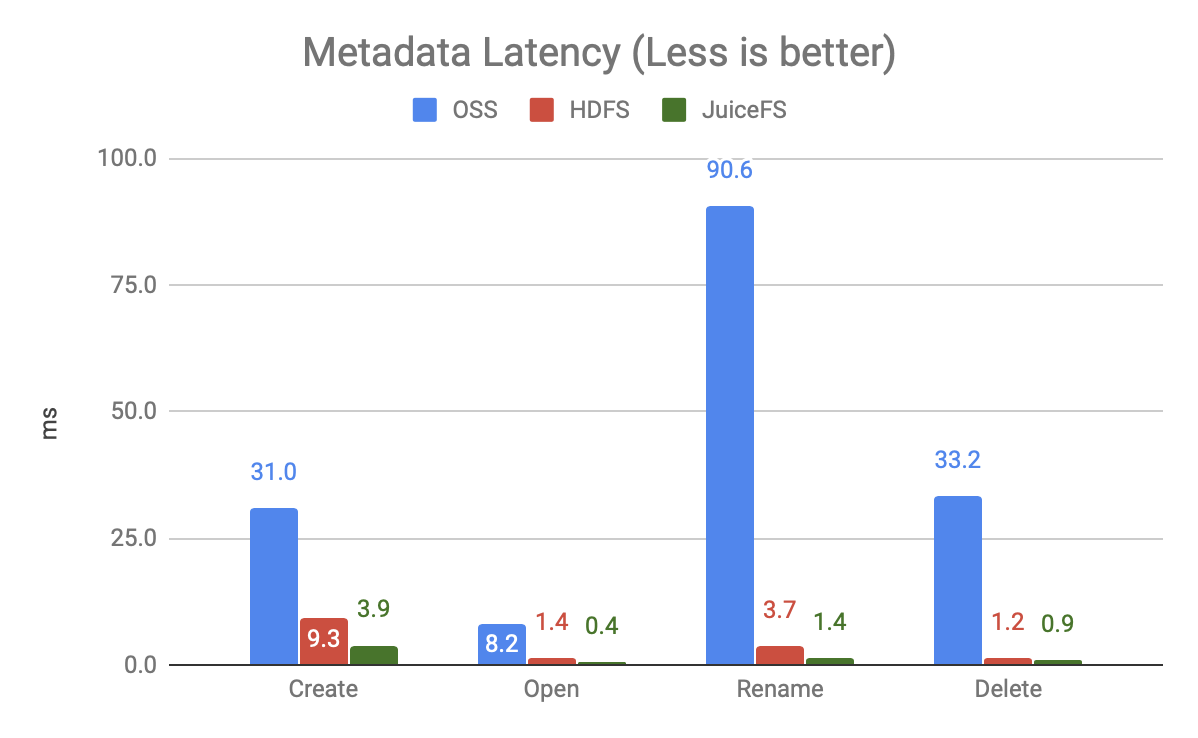
The graph above shows the delay of each of the 20 concurrent operations (not fully loaded) , and you can see:
- OSS is very slow, especially the Rename operation, because it is implemented through Copy + Delete. This article is still testing Rename for a single file, but the big data scenario uses Rename for an entire directory, so the gap is even wider
- JuiceFS is more than twice as fast as HDFS
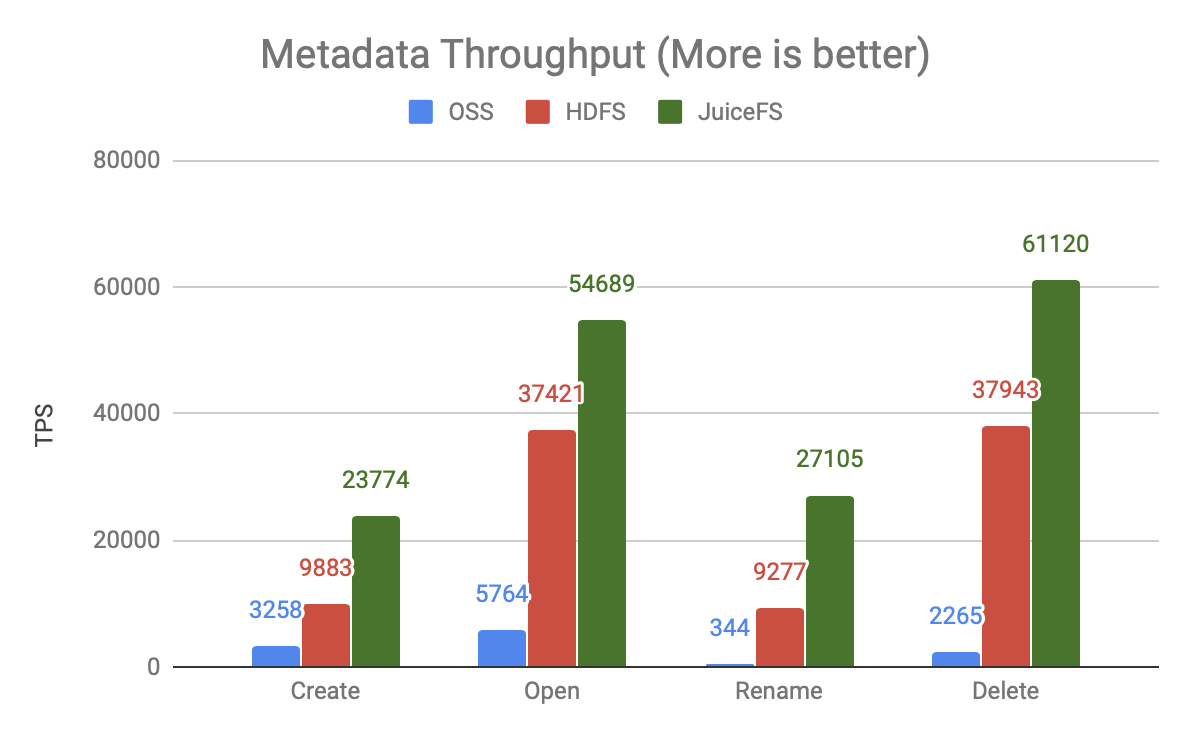
The graph above shows the throughput at 80 concurrent times and shows:
- OSS has very low throughput and is one or two orders of magnitude behind the other two products, meaning it requires more computing resources and higher concurrency to achieve the same processing power.
- JuiceFS has 50-200% more processing power than HDFS, and the same resources can support larger-scale computing.
From the above two core performance indicators, object storage is not suitable for the performance requirements of the big data analysis scenario. JuiceFS as a latecomer has comprehensively surpassed HDFS, with faster performance to support larger-scale computing processing.

